Apache Geode文档
本文档介绍了产品概念,并提供了Apache Geode 1.7的完整设置说明。 源文件可从Apache Geode Github存储库获得,有关如何构建此文档的说明如下: 可在[Geode项目自述文件]中找到(../../../../ github.com/apache/geode/blob/develop/geode-book/README.md)。
(../../../../cwiki.apache.org/confluence/display/GEODE/Index).
您还可以在Apache Geode Wiki上找到有关Geode的其他文档。
[TOC]
Apache Geode入门
教程演示了功能,主要功能部分介绍了主要功能。
-
Apache Geode是一个数据管理平台,可在广泛分布的云架构中提供对数据密集型应用程序的实时,一致的访问。
-
本节总结了Apache Geode的主要功能和主要功能。
-
满足一小部分先决条件的每个Apache Geode主机都可以遵循提供的安装说明。
-
需要快速介绍Apache Geode? 参加这个简短的游览,尝试基本功能。
关于 Apache
Apache Geode是一个数据管理平台,可在广泛分布的云架构中提供对数据密集型应用程序的实时,一致的访问。
Geode跨多个进程汇集内存,CPU,网络资源和可选的本地磁盘,以管理应用程序对象和行为。 它使用动态复制和数据分区技术来实现高可用性,改进的性能,可伸缩性和容错性。 除了作为分布式数据容器之外,Geode还是一个内存数据管理系统,可提供可靠的异步事件通知和有保证的消息传递。
主要概念和组件
Caches是描述Geode集群中节点的抽象。 应用程序架构师可以在peer-to-peer或client/server拓扑中安排这些节点。
在每个缓存中,您可以定义数据regions。 数据区域类似于关系数据库中的表,并以分布式方式管理数据作为name/value对。一个replicated区域在集群的每个缓存成员上存储相同的数据副本。一个partitioned区域在缓存成员之间传播数据。配置系统后,客户端应用程序可以在不了解底层系统体系结构的情况下访问区域中的分布式数据。 您可以定义侦听器以创建有关数据何时更改的通知,并且可以定义到期条件以删除区域中的过时数据。
对于大型生产系统,Geode提供locators。 定位器提供发现和负载平衡服务。 使用定位器服务列表配置客户端,定位器维护成员服务器的动态列表。 默认情况下,Geode客户端和服务器使用端口40404相互发现。
有关产品功能的更多信息,请参阅 Apache Geode的主要特点.
Apache Geode的主要特点
本节总结了主要功能和主要功能。
- 高读写吞吐量
- 低且可预测的延迟
- 高可扩展性
- 持续可用性
- 可靠的事件通知
- 数据存储上的并行应用程序行为
- 无共享磁盘持久性
- 降低拥有成本
- 客户/服务器的单跳能力
- 客户/服务器安全
- 多站点数据分布
- 连续查询
- 异构数据共享
高读写吞吐量
读写吞吐量由并发主存储器数据结构和高度优化的分发基础结构提供。 应用程序可以通过同步或异步复制在内存中动态复制数据,以实现高读取吞吐量,或者跨多个系统成员对数据进行分区,以实现高读写吞吐量。 如果数据访问在整个数据集中相当平衡,则数据分区会使聚合吞吐量翻倍。 吞吐量的线性增加仅受骨干网容量的限制。
低且可预测的延迟
优化的缓存层最大限度地减少了线程和进程之间的上下文切换。 它管理高度并发结构中的数据,以最大限度地减少争用点。 如果接收器可以跟上,则与对等成员的通信是同步的,这使得数据分发的延迟保持最小。 服务器以序列化形式管理对象图,以减少垃圾收集器的压力。
订阅管理(兴趣注册和连续查询)跨服务器数据存储进行分区,确保仅为所有感兴趣的客户端处理订阅一次。 由此带来的CPU使用和带宽利用率的提高可提高吞吐量并减少客户端订阅的延迟。
高可扩展性
通过跨多个成员动态分区数据并在服务器之间统一分布数据来实现可伸缩性。 对于“热”数据,您可以将系统配置为动态扩展以创建更多数据副本。 您还可以将应用程序行为设置为以接近所需数据的分布式方式运行。
如果您需要支持高且不可预测的并发客户端负载突发,您可以增加管理数据的服务器数量,并在其中分配数据和行为,以提供统一且可预测的响应时间。 客户端根据服务器在其负载条件下的持续反馈,不断对服务器场进行负载均衡。 通过跨服务器分区和复制数据,客户端可以动态移动到不同的服务器,以统一加载服务器并提供最佳响应时间。
您还可以通过实现对外部数据存储(如数据库)的数据更改的异步“write behind后写”来提高可伸缩性。 这可以通过按顺序冗余排队所有更新来避免瓶颈。 您还可以混合更新并将它们批量传播到数据库。
持续可用性
除了保证内存中数据的一致性副本之外,应用程序还可以通过使用“无共享磁盘体系结构”将数据同步或异步地保存在一个或多个成员的磁盘上。所有异步事件(存储转发事件)至少是冗余管理的 两个成员,如果一个服务器发生故障,冗余的服务器将接管。 所有客户端都连接到逻辑服务器,并且客户端在故障期间或服务器无响应时自动故障转移到组中的备用服务器。
可靠的事件通知
发布/订阅系统提供数据分发服务,其中新事件被发布到系统中并以可靠的方式路由到所有感兴趣的订户。 传统的消息传递平台专注于消息传递,但接收应用程序通常需要在处理事件之前访问相关数据。 这要求他们在事件传递时访问标准数据库,以数据库的速度限制订阅者。
数据和事件通过单一系统提供。 数据作为一个或多个分布式数据区域中的对象进行管理,类似于数据库中的表。 应用程序只需在数据区域中插入,更新或删除对象,平台就会将对象更改传递给订阅者。 接收事件的订户可以直接访问本地存储器中的相关数据,或者可以通过单跳从其他成员之一获取数据。
数据存储上的并行应用程序行为
您可以在成员上并行执行应用程序业务逻辑。 数据感知功能执行服务允许在成员上执行任意的,依赖于数据的应用程序功能,其中数据被分区以用于参考和缩放的位置。
通过并置相关数据并并行化计算,可以提高整体吞吐量。 计算延迟与可以并行化的成员数成反比。
基本前提是将功能透明地路由到承载功能所需的数据子集的应用程序,并避免在网络上移动数据。 应用程序功能只能在一个成员上执行,在成员子集上并行执行,或在所有成员上并行执行。 此编程模型类似于Google的流行Map-Reduce模型。 数据感知功能路由最适合需要迭代多个数据项的应用程序(例如查询或自定义聚合功能)。
无共享磁盘持久性
每个集群成员独立于其他成员管理磁盘文件上的数据。 一个成员中的磁盘故障或缓存故障不会影响另一个缓存实例在其磁盘文件上安全运行的能力。 这种“无共享”持久性体系结构允许对应用程序进行配置,使得不同类别的数据持久保存在整个系统的不同成员上,即使为应用程序对象配置了磁盘持久性,也会显着提高应用程序的整体吞吐量。
与传统数据库系统不同,单独的文件不用于管理数据和事务日志。 所有数据更新都附加到与传统数据库的事务日志类似的文件中。 如果磁盘未被其他进程同时使用,则可以避免磁盘寻道时间,并且唯一的成本是旋转延迟。
降低拥有成本
您可以在层中配置缓存。 客户端应用程序进程可以在本地(在内存中并溢出到磁盘)托管缓存,并在未命中时委托给缓存服务器场。 即使本地缓存的命中率达到30%,也可以显著节省成本。 与每个事务相关的总成本来自CPU周期花费,网络成本,对数据库的访问以及与数据库维护相关的无形成本。 通过将数据作为应用程序对象进行管理,可以避免与将SQL行映射到对象相关联的额外成本(CPU周期)。
客户/服务器的单跳能力
客户端可以将单个数据请求直接发送到持有数据key的服务器,从而避免多跳以定位已分区的数据。 客户端中的元数据标识正确的服务器。 此功能可提高服务器层中分区区域的性能和客户端访问权限。
客户/服务器安全
客户端应用程序中可能有多个不同的用户。 此功能适用于客户端嵌入应用程序服务器的安装,每个应用程序服务器都支持来自许多用户的数据请求。 每个用户可能被授权访问服务器上的一小部分数据,如在客户应用程序中,其中每个客户只能访问他们自己的订单和货件。 客户端中的每个用户都使用自己的一组凭据连接到服务器,并拥有自己对服务器缓存的访问权限。
多站点数据分布
数据站点在地理上分布在广域网(WAN)上可能导致可伸缩性问题。 模型可以解决这些拓扑问题,从单个对等集群到WAN上数据中心之间的可靠通信。 此模型允许集群以无限且松散耦合的方式扩展,而不会降低性能,可靠性或数据一致性。
该体系结构的核心是用于将区域事件分发到远程站点的网关发送器配置。 您可以并行部署网关发送方实例,从而增加通过WAN分发区域事件的吞吐量。 您还可以配置网关发件人队列以实现持久性和高可用性,以避免在成员发生故障时丢失数据。
连续查询
在Java Message Service等消息传递系统中,客户端订阅主题和队列。 传递给主题的任何消息都将发送给订阅者。 Geode允许通过使用对象查询语言使应用程序表达复杂的兴趣来进行连续查询。
异构数据共享
C#,C ++和Java应用程序可以共享应用程序业务对象,而无需通过SOAP或XML等转换层。 服务器端行为虽然是用Java实现的,但它为C ++和.NET应用程序提供了唯一的本机缓存。 可以在C ++进程堆中管理应用程序对象,并使用对象的常见“线上”表示将其分发到其他进程。 C ++序列化对象可以直接反序列化为等效的Java或C#对象。 使用一种语言更改业务对象可以在使用其他支持的语言编写的应用程序中触发可靠的通知。
先决条件和安装说明
满足一小部分先决条件的每个Apache Geode主机都可以遵循提供的安装说明。
-
主机必须满足Apache Geode的一系列要求。
-
从源代码构建或使用ZIP或TAR发行版在将运行Apache Geode的每台物理和虚拟机上安装Apache Geode。
-
本主题描述了Geode进程如何设置其CLASSPATH。
-
本节介绍如何删除Geode。
主机要求
主机必须满足Apache Geode的一系列要求。
每台运行Apache Geode的计算机都必须满足以下要求:
Java SE Development Kit 8 with update 121 or a more recent version 8 update.
系统时钟设置为正确的时间和时间同步服务,如网络时间协议(NTP)。 正确的时间戳允许以下活动:
- 对故障排除有用的日志。 同步时间戳确保可以合并来自不同主机的日志消息,以重现分布式运行的准确时间历史记录。
- 汇总产品级别和应用程序级别的时间统计信息。
- 使用脚本和其他工具准确监控Geode系统,这些工具可读取系统统计信息和日志文件。
已为计算机正确配置主机名和主机文件。 主机名和主机文件配置可能会影响
gfsh和Pulse功能。禁用
TCP SYN cookie。 大多数默认Linux安装使用SYN cookie来保护系统免受泛滥TCP SYN数据包的恶意攻击,但此功能与稳定和繁忙的Geode集群不兼容。 安全实现应该通过将Geode服务器集群置于高级防火墙保护之下来寻求防止攻击。要永久禁用SYN cookie:
编辑
/etc/sysctl.conf文件以包含以下行:net.ipv4.tcp_syncookies = 0将此值设置为零将禁用
SYN Cookie。重新加载
sysctl.conf:sysctl -p
有关详细信息,请参阅禁用TCP SYN Cookie。
如何安装
从源代码构建或使用ZIP或TAR发行版在将运行Apache Geode的每台物理和虚拟机上安装Apache Geode。
在Unix上从Source构建
设置JAVA_HOME环境变量。
JAVA_HOME=/usr/java/jdk1.8.0_121 export JAVA_HOME从http://geode.apache.org上的Releases页面下载项目源代码,然后解压缩源代码。
在包含解压缩源代码的目录中,无需测试即可构建:
$ ./gradlew build -Dskip.tests=true或者,使用测试构建:
$ ./gradlew build通过调用
gfsh来打印版本信息并退出来验证安装。 在Linux/Unix平台上,版本类似于:$ cd geode-assembly/build/install/apache-geode $ bin/gfsh version v1.1.0
在Windows上从源代码构建
设置JAVA_HOME环境变量。 例如:
$ set JAVA_HOME="C:\Program Files\Java\jdk1.8.0_121"安装Gradle,版本2.3或更新版本。
从http://geode.apache.org上的Releases页面下载项目源代码,然后解压缩源代码。
在包含解压缩源代码的文件夹中,不使用测试进行构建:
$ gradle build -Dskip.tests=true或者,使用测试构建:
$ gradle build通过调用
gfsh来打印版本信息并退出来验证安装。$ cd geode-assembly\build\install\apache-geode\bin $ gfsh.bat version v1.1.0
从.zip或.tar文件安装二进制文件
从http://geode.apache.org上的Releases页面下载.zip或.tar文件。
解压缩.zip文件或展开.tar文件,其中
path_to_product是绝对路径,文件名因版本号而异。 对于.zip格式:$ unzip apache-geode-1.1.0.zip -d path_to_product对于.tar格式:
$ tar -xvf apache-geode-1.1.0.tar -C path_to_product设置JAVA_HOME环境变量。 在Linux / Unix平台上:
JAVA_HOME=/usr/java/jdk1.8.0_121 export JAVA_HOME在Windows平台上:
set JAVA_HOME="C:\Program Files\Java\jdk1.8.0_121"将Geode脚本添加到PATH环境变量中。 在Linux/Unix平台上:
PATH=$PATH:$JAVA_HOME/bin:path_to_product/bin export PATH在Windows平台上:
set PATH=%PATH%;%JAVA_HOME%\bin;path_to_product\bin要验证安装,请在命令行键入
gfsh version,并注意输出列出已安装的Geode版本。 例如:$ gfsh version v1.1.0有关更详细的版本信息,例如构建日期,内部版本号和正在使用的JDK版本,请调用:
$ gfsh version --full
设置CLASSPATH
本主题描述了Geode进程如何设置其CLASSPATH。
为了简化CLASSPATH环境设置,Geode将Geode进程所需的所有应用程序库组织成* -dependencies.jar文件。 所有依赖项JAR文件都位于path_to_product/lib目录中。
使用gfsh启动服务器或定位器进程时,应用程序JAR文件会自动从两个目录加载到进程的CLASSPATH中:
path_to_product/lib/path_to_product/extensions/
注意: 要在应用程序中嵌入Geode,请将path_to_product/lib/geode-dependencies.jar添加到CLASSPATH中。
下表列出了与各种Geode进程关联的依赖项JAR文件:
| Geode Process | Associated JAR Files |
|---|---|
| gfsh | gfsh-dependencies.jar |
| server and locator | geode-dependencies.jarNote:Use this library for all standalone or embedded Geode processes (including Java clients) that host cache data. |
在gfsh管理的进程中修改CLASSPATH
有两个选项可用于更新geode服务器的CLASSPATH和在gfsh命令行上启动的定位器进程。
选项1: 在进程启动时指定--classpath参数。 例如,要修改定位器的CLASSPATH:
gfsh> start locator --name=locator1 --classpath=/path/to/applications/classes.jar
并修改服务器的CLASSPATH:
gfsh> start server --name=server1 --classpath=/path/to/applications/classes.jar
作为--classpath选项的参数提供的应用程序类是prepended到服务器或定位器的CLASSPATH,从第二个位置开始。 出于安全原因,CLASSPATH中的第一个条目保留用于核心Geode jar文件。
选项 2: 在OS环境中定义CLASSPATH环境变量。 然后,在进程启动时指定--include-system-classpath参数。 例如:
gfsh> start locator --name=locator1 --include-system-classpath=true
服务器进程也可以这样做:
gfsh> start server --name=server1 --include-system-classpath=true
此选项在启动时将系统CLASSPATH环境变量的内容附加到定位器或服务器的CLASSPATH。 在没有值的情况下指定此选项会将其设置为true。
为应用程序和独立Java进程设置CLASSPATH
如果以编程方式(独立或嵌入式)启动Geode进程,我们建议您在程序执行时使用java -classpath或java -cpcommand-line选项指定CLASSPATH。 此方法首选将CLASSPATH设置为环境变量,因为它允许您为每个应用程序单独设置值,而不会影响其他应用程序,也不会修改其值的其他应用程序。
例如,要使用LocatorLauncher API启动Geode定位器进程,可以在命令行上执行以下命令:
prompt# java -cp "path_to_product/lib/geode-dependencies.jar"
org.apache.geode.distributed.LocatorLauncher start locator1
<locator-launcher-options>
要使用ServerLauncher API启动Geode服务器进程,请执行以下操作:
prompt# java -cp "path_to_product/lib/geode-dependencies.jar:/path/to/your/applications/classes.jar"
org.apache.geode.distributed.ServerLauncher start server1
<server-launcher-options>
请注意,除了与进程关联的* -dependencies.jar文件之外,还必须指定要在Geode进程中访问的任何自定义应用程序JAR。 例如,如果您计划在区域上使用自定义压缩器,则应指定包含要使用的压缩器应用程序的应用程序JAR。
要使用嵌入式缓存启动应用程序:
java -cp "path_to_product/lib/geode-dependencies.jar:/path/to/your/applications/classes.jar"
com.mycompany.package.ApplicationWithEmbeddedCache
注意: 使用您自己的应用程序更新服务器进程的CLASSPATH的另一种方法是使用gfsh deploy命令。 部署应用程序JAR文件将自动更新所有部署目标成员的CLASSPATH。有关详细信息,请参阅将应用程序JAR部署到Apache Geode成员。
如何卸载
本节介绍如何删除Geode。
关闭所有正在运行的Geode进程,然后删除整个目录树。 不需要对Windows注册表项进行其他系统修改或修改。
Apache Geode在15分钟或更短时间内完成
需要快速介绍Apache Geode? 参加这个简短的游览,尝试基本功能。
步骤 1: 安装Apache Geode
有关说明,请参见如何安装.
步骤 2: 使用gfsh启动定位器
在终端窗口中,使用gfsh命令行界面启动定位器。 Apache Geode gfsh(发音为“jee-fish”)提供了一个直观的命令行界面,您可以从中启动,管理和监控Apache Geode流程,数据和应用程序。 见gfsh。
locator是一个Geode进程,它告诉运行成员所在的新连接成员,并为服务器使用提供负载均衡。 默认情况下,定位器启动JMX Manager,该管理器用于监视和管理Geode集群。 集群配置服务使用定位器将集群配置保留并分发到集群成员。参见 运行Geode定位器进程 和 集群配置服务概述.
创建一个临时工作目录(例如
my_geode)和将目录切换到它。gfsh在此位置保存定位器和服务器工作目录和日志文件。通过在命令行键入
gfsh来启动gfsh(如果使用的是Windows,则输入gfsh.bat)。_________________________ __ / _____/ ______/ ______/ /____/ / / / __/ /___ /_____ / _____ / / /__/ / ____/ _____/ / / / / /______/_/ /______/_/ /_/ 1.7 Monitor and Manage Geode gfsh>在
gfsh提示符下,键入start locator命令并指定定位符的名称:gfsh>start locator --name=locator1 Starting a Geode Locator in /home/username/my_geode/locator1... ................................. Locator in /home/username/my_geode/locator1 on ubuntu.local[10334] as locator1 is currently online. Process ID: 3529 Uptime: 18 seconds Geode Version: 1.7 Java Version: 1.8.0_121 Log File: /home/username/my_geode/locator1/locator1.log JVM Arguments: -Dgemfire.enable-cluster-configuration=true -Dgemfire.load-cluster-configuration-from-dir=false -Dgemfire.launcher.registerSignalHandlers=true -Djava.awt.headless=true -Dsun.rmi.dgc.server.gcInterval=9223372036854775806 Class-Path: /home/username/Apache_Geode_Linux/lib/geode-core-1.0.0.jar: /home/username/Apache_Geode_Linux/lib/geode-dependencies.jar Successfully connected to: JMX Manager [host=10.118.33.169, port=1099] Cluster configuration service is up and running.
如果从gfsh运行start locator而不指定成员名称,gfsh将自动选择一个随机成员名称。 这对自动化很有用。
步骤 3: 启动`Pulse`
启动基于浏览器的Pulse监控工具。 Pulse是一个Web应用程序,它提供了一个图形仪表板,用于监视Geode集群,成员和区域的重要实时运行状况和性能。 请参阅Geode Pulse。
gfsh>start pulse
此命令启动Pulse并自动将您连接到定位器中运行的JMX Manager。 在Pulse登录界面,输入默认用户名admin和密码admin。
Pulse应用程序现在显示刚刚启动的定位器(locator1):
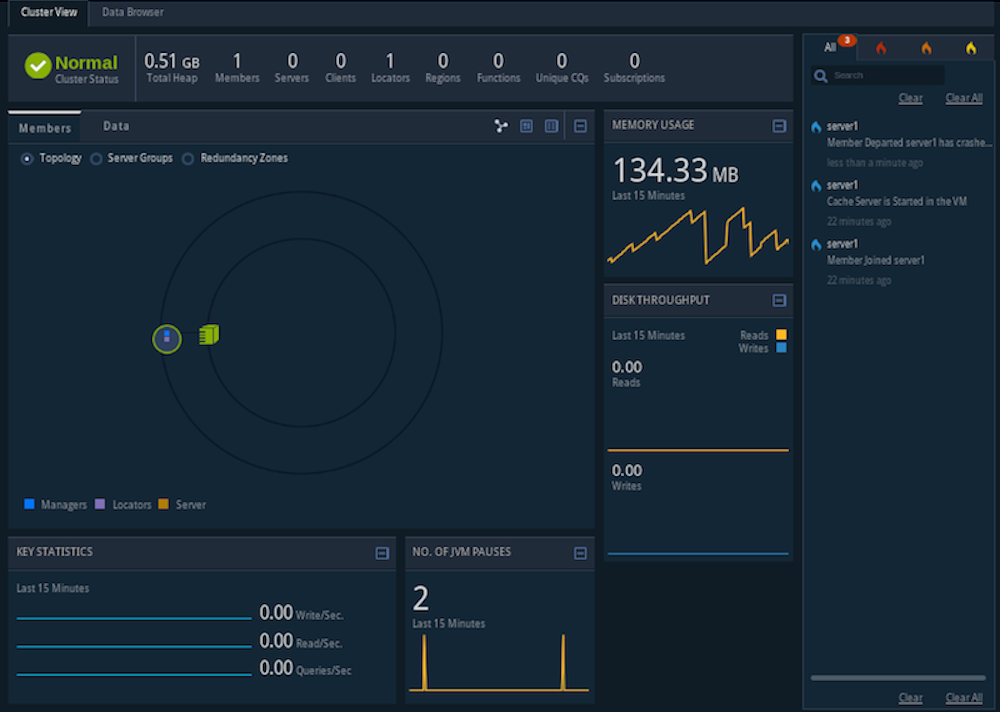
步骤 4: 启动一个`server`
Geode服务器是一个作为集群的长期可配置成员运行的进程。 Geode服务器主要用于托管长期数据区域以及运行标准Geode进程,例如客户端/服务器配置中的服务器。 请参阅运行Geode服务器进程。
启动缓存服务器:
gfsh>start server --name=server1 --server-port=40411
此命令在指定的40411端口上启动名为“server1”的缓存服务器。
如果从gfsh运行start server而不指定成员名称,gfsh将自动选择一个随机成员名称。 这对自动化很有用。
观察Pulse中的更改(新成员和服务器)。 尝试扩展分布式系统图标以图形方式查看定位器和缓存服务器。
步骤 5: Create a replicated, persistent region(创建一个复制的持久区域)
在此步骤中,您将使用gfsh命令行实用程序创建一个区域。 区域是Geode集群的核心构建块,并提供组织数据的方法。 您为此练习创建的区域使用复制来跨集群成员复制数据,并利用持久性将数据保存到磁盘。 请参阅数据区域。
Create a replicated, persistent region(创建一个复制的持久区域):
gfsh>create region --name=regionA --type=REPLICATE_PERSISTENT Member | Status ------- | -------------------------------------- server1 | Region "/regionA" created on "server1"请注意,该区域托管在server1上。
使用
gfsh命令行查看集群中的区域列表。gfsh>list regions List of regions --------------- regionA列出集群的成员。 您启动的定位器和缓存服务器显示在列表中:
gfsh>list members Name | Id ------------ | --------------------------------------- Coordinator: | 192.0.2.0(locator1:3529:locator)<ec><v0>:59926 locator1 | 192.0.2.0(locator1:3529:locator)<ec><v0>:59926 server1 | 192.0.2.0(server1:3883)<v1>:65390要查看有关区域的详细信息,请键入以下内容:
gfsh>describe region --name=regionA .......................................................... Name : regionA Data Policy : persistent replicate Hosting Members : server1 Non-Default Attributes Shared By Hosting Members Type | Name | Value ------ | ---- | ----- Region | size | 0在Pulse中,单击绿色集群图标以查看刚刚添加到集群中的所有新成员和新区域。
注意: 保持这个gfsh提示符打开以进行后续步骤。
步骤 6: 处理区域中的数据并演示持久性
Apache Geode将数据作为键/值对进行管理。 在大多数应用程序中,Java程序会添加,删除和修改存储的数据。 您还可以使用gfsh命令添加和检索数据。 请参阅数据命令。
运行以下
put命令将一些数据添加到该区域:gfsh>put --region=regionA --key="1" --value="one" Result : true Key Class : java.lang.String Key : 1 Value Class : java.lang.String Old Value : <NULL> gfsh>put --region=regionA --key="2" --value="two" Result : true Key Class : java.lang.String Key : 2 Value Class : java.lang.String Old Value : <NULL>运行以下命令以从该区域检索数据:
gfsh>query --query="select * from /regionA" Result : true startCount : 0 endCount : 20 Rows : 2 Result ------ two one请注意,结果显示使用
put命令创建的两个数据条目的值。请参阅数据条目。
使用以下命令停止缓存服务器:
gfsh>stop server --name=server1 Stopping Cache Server running in /home/username/my_geode/server1 on ubuntu.local[40411] as server1... Process ID: 3883 Log File: /home/username/my_geode/server1/server1.log ....使用以下命令重新启动缓存服务器:
gfsh>start server --name=server1 --server-port=40411运行以下命令再次从该区域检索数据 - 请注意数据仍然可用:
gfsh>query --query="select * from /regionA" Result : true startCount : 0 endCount : 20 Rows : 2 Result ------ two one由于regionA使用持久性,因此它会将数据副本写入磁盘。 当托管regionA的服务器启动时,数据将填充到缓存中。 请注意,结果显示在停止服务器之前使用
put命令创建的两个数据条目的值。请参阅数据条目。
请参阅数据区域。
步骤 7: 检查复制的影响
在此步骤中,您将启动第二个缓存服务器。 由于regionA被复制,因此数据将在托管该区域的任何服务器上可用。
请参阅数据区域。
启动第二个缓存服务器:
gfsh>start server --name=server2 --server-port=40412运行
describe region命令查看有关regionA的信息:gfsh>describe region --name=regionA .......................................................... Name : regionA Data Policy : persistent replicate Hosting Members : server1 server2 Non-Default Attributes Shared By Hosting Members Type | Name | Value ------ | ---- | ----- Region | size | 2请注意,您无需再次为server2创建regionA。 该命令的输出显示regionA托管在server1和server2上。 当gfsh启动服务器时,它会从集群配置服务请求配置,然后将共享配置分发到任何加入集群的新服务器。
添加第三个数据条目:
gfsh>put --region=regionA --key="3" --value="three" Result : true Key Class : java.lang.String Key : 3 Value Class : java.lang.String Old Value : <NULL>打开Pulse应用程序(在Web浏览器中)并观察集群拓扑。 您应该看到一个带有两个连接服务器的定位器。 单击“数据”选项卡以查看有关regionA的信息。
使用以下命令停止第一个缓存服务器:
gfsh>stop server --name=server1 Stopping Cache Server running in /home/username/my_geode/server1 on ubuntu.local[40411] as server1... Process ID: 4064 Log File: /home/username/my_geode/server1/server1.log ....从剩余的缓存服务器中检索数据。
gfsh>query --query="select * from /regionA" Result : true startCount : 0 endCount : 20 Rows : 3 Result ------ two one three请注意,数据包含3个条目,包括您刚添加的条目。
添加第四个数据条目:
gfsh>put --region=regionA --key="4" --value="four" Result : true Key Class : java.lang.String Key : 3 Value Class : java.lang.String Old Value : <NULL>请注意,只有server2正在运行。 由于数据被复制并保留,因此所有数据仍然可用。 但新数据条目目前仅在服务器2上可用。
gfsh>describe region --name=regionA .......................................................... Name : regionA Data Policy : persistent replicate Hosting Members : server2 Non-Default Attributes Shared By Hosting Members Type | Name | Value ------ | ---- | ----- Region | size | 4停止剩余的缓存服务器:
gfsh>stop server --name=server2 Stopping Cache Server running in /home/username/my_geode/server2 on ubuntu.local[40412] as server2... Process ID: 4185 Log File: /home/username/my_geode/server2/server2.log .....
步骤 8: 并行重新启动缓存服务器
在此步骤中,您将并行重新启动缓存服务器。 由于数据是持久的,因此服务器重新启动时数据可用。 由于数据是复制的,因此必须并行启动服务器,以便在启动之前同步数据。
启动server1。 因为regionA是复制和持久的,所以它需要来自其他服务器的数据才能启动并等待服务器启动:
gfsh>start server --name=server1 --server-port=40411 Starting a Geode Server in /home/username/my_geode/server1... ............................................................................ ............................................................................请注意,如果查看重新启动的服务器的server1.log文件,您将看到类似于以下内容的日志消息:
[info 2015/01/14 09:08:13.610 PST server1 <main> tid=0x1] Region /regionA has pot entially stale data. It is waiting for another member to recover the latest data. My persistent id: DiskStore ID: 8e2d99a9-4725-47e6-800d-28a26e1d59b1 Name: server1 Location: /192.0.2.0:/home/username/my_geode/server1/. Members with potentially new data: [ DiskStore ID: 2e91b003-8954-43f9-8ba9-3c5b0cdd4dfa Name: server2 Location: /192.0.2.0:/home/username/my_geode/server2/. ] Use the "gfsh show missing-disk-stores" command to see all disk stores that are being waited on by other members.在第二个终端窗口中,将目录更改为临时工作目录(例如,
my_geode)并启动gfsh:[username@localhost ~/my_geode]$ gfsh _________________________ __ / _____/ ______/ ______/ /____/ / / / __/ /___ /_____ / _____ / / /__/ / ____/ _____/ / / / / /______/_/ /______/_/ /_/ 1.7 Monitor and Manage Geode运行以下命令以连接到集群:
gfsh>connect --locator=localhost[10334] Connecting to Locator at [host=localhost, port=10334] .. Connecting to Manager at [host=ubuntu.local, port=1099] .. Successfully connected to: [host=ubuntu.local, port=1099]启动 server2:
gfsh>start server --name=server2 --server-port=40412当server2启动时,请注意 server1在第一个gfsh窗口中完成其启动:
Server in /home/username/my_geode/server1 on ubuntu.local[40411] as server1 is currently online. Process ID: 3402 Uptime: 1 minute 46 seconds Geode Version: 1.7 Java Version: 1.8.0_121 Log File: /home/username/my_geode/server1/server1.log JVM Arguments: -Dgemfire.default.locators=192.0.2.0[10334] -Dgemfire.use-cluster-configuration=true -XX:OnOutOfMemoryError=kill -KILL %p -Dgemfire.launcher.registerSignalHandlers=true -Djava.awt.headless=true -Dsun.rmi.dgc.server.gcInterval=9223372036854775806 Class-Path: /home/username/Apache_Geode_Linux/lib/geode-core-1.0.0.jar: /home/username/Apache_Geode_Linux/lib/geode-dependencies.jar验证定位器和两个服务器是否正在运行:
gfsh>list members Name | Id ------------ | --------------------------------------- Coordinator: | ubuntu(locator1:2813:locator)<ec><v0>:46644 locator1 | ubuntu(locator1:2813:locator)<ec><v0>:46644 server2 | ubuntu(server2:3992)<v8>:21507 server1 | ubuntu(server1:3402)<v7>:36532运行查询以验证您使用
put命令输入的所有数据是否可用:gfsh>query --query="select * from /regionA" Result : true startCount : 0 endCount : 20 Rows : 5 Result ------ one two four Three NEXT_STEP_NAME : END使用以下命令停止server2:
gfsh>stop server --dir=server2 Stopping Cache Server running in /home/username/my_geode/server2 on 192.0.2.0[40412] as server2... Process ID: 3992 Log File: /home/username/my_geode/server2/server2.log ....运行查询以验证您使用
put命令输入的所有数据是否仍然可用:gfsh>query --query="select * from /regionA" Result : true startCount : 0 endCount : 20 Rows : 5 Result ------ one two four Three NEXT_STEP_NAME : END
步骤 9: 关闭系统,包括定位器
要关闭集群,请执行以下操作:
在当前的
gfsh会话中,停止集群:gfsh>shutdown --include-locators=true请参阅shutdown。
出现提示时,键入'Y'以确认集群已关闭。
As a lot of data in memory will be lost, including possibly events in queues, do you really want to shutdown the entire distributed system? (Y/n): Y Shutdown is triggered gfsh> No longer connected to ubuntu.local[1099]. gfsh>输入
exit退出gfsh shell。
步骤 10: 接下来做什么…
以下是Apache Geode下一步要探索的一些建议:
- 继续阅读下一部分,以了解有关刚刚介绍的组件和概念的更多信息。
- 要使用
gfsh进行更多练习,请参阅教程 - 使用gfsh执行常见任务。 - 要了解集群配置服务,请参阅教程 - 创建和使用集群配置。