使用Apache Geode进行开发
使用Apache Geode进行开发解释了使用Apache Geode进行应用程序编程的主要概念。 它描述了如何规划和实现区域,数据序列化,事件处理,增量传播,事务等。
有关Geode REST应用程序开发的信息,请参阅为Apache Geode开发REST应用程序.
区域数据存储和分发
Apache Geode数据存储和分发模型可以在适当的时间将您的数据放在正确的位置。 在开始配置数据区域之前,您应该了解Geode中数据存储的所有选项。
分区区域
除基本区域管理外,分区区域还包括高可用性选项,数据位置控制以及跨集群的数据平衡。
分布式和复制区域
除基本区域管理外,分布式和复制区域还包括推送和分发模型,全局锁定和区域条目版本等选项,以确保Geode成员之间的一致性。
区域更新的一致性
Geode确保区域的所有副本最终在托管该区域的所有成员和客户端上达到一致状态,包括分发区域事件的Geode成员。
一般地区数据管理
对于所有区域,您可以选择控制内存使用,将数据备份到磁盘,并将过时数据保留在缓存之外。
数据序列化
您在Geode中管理的数据必须序列化和反序列化,以便在进程之间进行存储和传输。 您可以选择多个数据序列化选项。
事件和事件处理
Geode为缓存的数据和系统成员事件提供了通用且可靠的事件分发和处理。
增量传播
增量传播允许您通过仅包括对象而不是整个对象的更改来减少通过网络发送的数据量。
查询
Geode提供了一种类似SQL的查询语言OQL,允许您访问存储在Geode区域中的数据。
连续查询
连续查询会不断返回与您设置的查询匹配的事件。
事务
Geode提供了一个事务API,使用
begin,commit和rollback方法。 这些方法与熟悉的关系数据库事务方法非常相似。函数执行
函数是驻留在服务器上的代码体,应用程序可以从客户端或其他服务器调用,而无需自己发送函数代码。 调用者可以指示数据相关函数对特定数据集进行操作,或者可以指示与数据无关的函数在特定服务器,成员或成员组上操作。
区域数据存储和分发
Apache Geode数据存储和分发模型可以在适当的时间将您的数据放在正确的位置。 在配置数据区域之前,您应该了解Geode中数据存储的所有选项。
存储和分配选项
Geode提供了多种数据存储和分发模型,包括分区或复制区域以及分布式或非分布式区域(本地缓存存储)。
区域类型
区域类型定义单个集群中的区域行为。 您可以使用各种区域数据存储和分发选项。
区域数据存储和数据访问器
了解存储区域数据的成员与仅作为区域数据访问者的成员之间的区别。
动态创建区域
您可以在应用程序代码中动态创建区域,并自动在集群成员上实例化它们。
存储和分配选项
Geode提供了多种数据存储和分发模型,包括分区或复制区域以及分布式或非分布式区域(本地缓存存储)。
点对点区域存储和分发
最常见的是,数据管理意味着在应用程序需要的时间和地点提供当前数据。在正确配置的Geode安装中,您将数据存储在本地成员中,Geode会根据您的缓存配置设置自动将其分发给需要它的其他成员。您可能正在存储需要特殊考虑的非常大的数据对象,或者您可能需要仔细配置大量数据以保护应用程序的性能或内存使用。您可能需要能够在特定操作期间显式锁定某些数据。大多数数据管理功能都可以作为配置选项使用,您可以使用gfsh集群配置服务,cache.xml文件或API指定。配置完成后,Geode会自动管理数据。例如,这是您管理数据分发,磁盘存储,数据过期活动和数据分区的方式。通过API在运行时管理一些功能。
在体系结构级别,数据分发在单个群集中的对等体之间以及客户端和服务器之间运行。
- 点对点提供核心分发和存储模型,这些模型被指定为数据区域上的属性。
- 对于客户端/服务器,您可以选择在客户端和服务器层之间共享哪些数据区域。 然后,在每个区域内,您可以通过订阅子集来微调服务器自动发送到客户端的数据。
任何类型的安装中的数据存储都基于每个群集的点对点配置。 数据和事件分发基于点对点和系统到系统配置的组合。
存储和分发模型通过缓存和区域属性进行配置。 主要选择是分区,复制或仅分布式。 必须对所有服务器区域进行分区或复制。 每个区域的data-policy和subscription-attributes,如果它不是分区区域,它的scope进行交互以更好地控制数据分发。
在本地缓存中存储数据
要将数据存储在本地缓存中,请使用带有本地状态的RegionShortcut或ClientRegionShortcut的区域refid。 这些会自动将区域data-policy设置为非空策略。 没有存储的区域可以发送和接收事件分发,而无需在应用程序堆中存储任何内容。 使用其他设置,接收的所有输入操作都存储在本地。
区域类型
区域类型定义单个集群中的区域行为。 您可以使用各种区域数据存储和分发选项。
在Geode集群中,您可以定义分布式区域和非分布式区域,并且可以定义其数据分布在集群中的区域,以及其数据完全包含在单个成员中的区域。
您选择的区域类型部分取决于您运行的应用程序类型。 特别是,您需要为服务器和客户端使用特定的区域类型,以便在两个层之间进行有效通信:
- 服务器区域由服务器在
缓存内创建,并由从服务器集群外部连接到服务器的客户端访问。 服务器区域必须具有分区或复制的区域类型。 服务器区域配置使用RegionShortcut枚举设置。 - 客户端区域由客户端在
ClientCache内创建,并配置为在客户端和服务器层之间分发数据和事件。 客户区域必须具有区域类型local。 客户端区域配置使用ClientRegionShortcut枚举设置。 - 对等区域在
Cache内创建。 对等区域可以是服务器区域,或者它们可以是客户端不访问的区域。 对等区域可以具有任何区域类型。 对等区域配置使用RegionShortcut枚举设置。
使用gfsh或cache.xml文件配置服务器或对等区域时,可以使用region shortcuts来定义您所在区域的基本配置。 区域快捷方式提供了一组默认配置属性,这些属性是为各种类型的缓存体系结构设计的。 然后,您可以根据需要添加其他配置属性以自定义应用程序。 有关这些区域快捷方式的更多信息和完整参考,请参阅区域快捷方式参考.
这些是每个数据区域的主要配置选择。
| 区域类型 | 描述 | 最适合... |
|---|---|---|
| Partitioned | 系统范围的数据集设置。 数据被划分为跨定义区域的成员的桶。 为了实现高可用性,请配置冗余副本,以便每个存储桶存储在多个成员中,其中一个成员持有主数据. | 服务器区域和对等区域: 1.非常大的数据集; 2.高可用性; 3.写性能; 4.分区事件监听器和数据加载器 |
| Replicated (distributed) | 保存分布式区域中的所有数据。 来自分布区域的数据被复制到成员副本区域中。 可以与非复制混合,一些成员持有副本,一些成员持有非副本。 | 服务器区域和对等区域: 1.阅读繁重的小型数据集; 2.异步分配; 3.查询性能 |
| Distributed non-replicated | 数据分布在定义区域的成员之间。 每个成员只保留其表示感兴趣的数据。可以与复制混合,一些成员持有副本,一些成员持有非副本。 | 对等区域,但不是服务器区域和不是客户区域: 异步分配;查询性能 |
| Non-distributed (local) | 该区域仅对定义成员可见。 | 客户区域和对等区域: 1.应用程序之间未共享的数据 |
分区区域
对于非常大的服务器区域,分区是一个不错的选择。 分区区域非常适用于数百GB甚至更多的数据集。
注意: 分区区域通常需要比其他区域类型更多的JDBC连接,因为承载数据的每个成员必须具有连接。
分区区域将数据分组到存储桶中,每个存储桶都存储在所有系统成员的子集中。 存储桶中的数据位置不会影响逻辑视图 - 所有成员都会看到相同的逻辑数据集。
使用分区:
- 大数据集. 存储太大而无法放入单个成员的数据集,并且所有成员都将看到相同的逻辑数据集。 分区区域将数据划分为称为存储区的存储单元,这些存储区分为托管分区区域数据的成员,因此没有成员需要托管所有区域的数据。 Geode提供动态冗余恢复和分区区域的重新平衡,使其成为大规模数据容器的选择。 系统中的更多成员可以在所有主机成员之间实现更均匀的数据平衡,从而允许在添加新成员时扩展系统吞吐量(获取和放置)。
- 高可用性. 分区区域允许您配置Geode应该创建的数据副本数。 如果成员失败,您的数据将在不中断其他成员的情况下可用。 分区区域也可以持久保存到磁盘以获得额外的高可用性。
- 可扩展性. 分区区域可以扩展为大量数据,因为数据在可用于托管区域的成员之间划分。 只需添加新成员即可动态增加数据容量。 分区区域还允许您扩展处理能力。 由于您的条目分布在托管区域的成员中,因此对这些条目的读取和写入也会分散在这些成员中。
- 良好的写性能. 您可以配置数据的副本数量。 每次写入传输的数据量不会随着成员数量的增加而增加。 相反,对于复制区域,每个写入必须发送到具有复制区域的每个成员,因此每次写入传输的数据量随着成员数量的增加而增加。
在分区区域中,您可以在存储桶内和多个分区区域内共存keys。 您还可以控制哪些成员存储哪些数据存储桶。
复制区域
复制区域在吞吐量和延迟方面提供最高性能。 对于中小型服务器区域,复制是一个不错的选择。
使用复制区域:
- 集群的所有成员都需要少量数据. For example, currency rate information and mortgage rates.
- 可以完全包含在单个成员中的数据集. 每个复制区域都包含该区域的完整数据集
- 高性能数据访问. 复制保证了堆对应用程序线程的本地访问,从而为数据访问提供尽可能低的延迟。
- 异步分发. 所有分布式区域(复制和非复制)都提供最快的分发速度。
分布式,非复制区域
分布式区域提供与复制区域相同的性能,但每个成员仅通过订阅来自其他成员的事件或通过在其缓存中定义数据条目来仅存储其表达兴趣的数据。
使用分布式,非复制区域:
- 对等区域,但不是服务器区域或客户区域. 服务器的区域必须是复制或分区。 客户区域必须是本地的。
- 数据集,其中各个成员仅需要通知和更新数据子集的更改. 在非复制区域中,每个成员仅接收其在本地缓存中定义的数据条目的更新事件。
- 异步分发. 所有分布式区域(复制和非复制)都提供最快的分发速度。
本地区域
注意: 当使用ClientRegionShortcut设置创建时,客户端区域自动定义为本地,因为所有客户端分发活动都来自服务器层。
本地区域没有对等分发活动。
使用本地地区:
- 客户区域. 分发仅在客户端和服务器层之间进行。
- 定义成员的私有数据集. 对等成员看不到本地区域。
区域数据存储和数据访问器
了解存储区域数据的成员与仅作为区域数据访问者的成员之间的区别。
在大多数情况下,在成员缓存中定义数据区域时,还要指定该成员是否为数据存储。 存储区域数据的成员称为数据存储或数据主机。 不存储数据的成员称为访问者成员或空成员。 定义区域的任何成员,存储或访问者都可以访问它,将数据放入其中,并从其他成员接收事件。 要配置区域以使成员是数据访问者,请使用不为该区域指定本地数据存储的配置。 否则,该成员是该区域的数据存储。
对于服务器区域,通过在名称中指定包含术语PROXY的区域快捷方式来抑制区域创建时的本地数据存储,例如PARTITION_PROXY或REPLICATE_PROXY。
对于客户端区域,通过指定PROXY区域快捷方式来抑制区域创建时的本地数据存储。 不要使用CACHING_PROXY快捷方式,因为它允许本地数据存储。
动态创建区域
您可以在应用程序代码中动态创建区域,并自动在集群成员上实例化它们。
如果您的应用程序不需要分区区域,则可以使用org.apache.geode.cache.DynamicRegionFactory类动态创建区域,也可以使用cache.xml中的<dynamic-region-factory>元素创建它们。 定义区域的文件。 见.
由于涉及的选项数量众多,大多数开发人员使用函数在其应用程序中动态创建区域,如本主题中所述。 也可以从gfsh命令行创建动态区域。
有关使用Geode函数的完整讨论,请参阅Function Execution。 函数使用org.apache.geode.cache.execute.FunctionService类。
例如,以下Java类定义并使用函数来创建动态区域:
CreateRegionFunction类定义客户端使用FunctionService类的onServer()方法在服务器上调用的函数。 此函数调用通过将条目放入区域属性元数据区域来启动区域创建。 条目key是区域名称,value是用于创建区域的区域属性集。
#CreateRegionFunction.java
import org.apache.geode.cache.Cache;
import org.apache.geode.cache.CacheFactory;
import org.apache.geode.cache.DataPolicy;
import org.apache.geode.cache.Declarable;
import org.apache.geode.cache.Region;
import org.apache.geode.cache.RegionAttributes;
import org.apache.geode.cache.RegionFactory;
import org.apache.geode.cache.Scope;
import org.apache.geode.cache.execute.Function;
import org.apache.geode.cache.execute.FunctionContext;
import java.util.Properties;
public class CreateRegionFunction implements Function, Declarable {
private final Cache cache;
private final Region<String,RegionAttributes> regionAttributesMetadataRegion;
private static final String REGION_ATTRIBUTES_METADATA_REGION =
"_regionAttributesMetadata";
public enum Status {SUCCESSFUL, UNSUCCESSFUL, ALREADY_EXISTS};
public CreateRegionFunction() {
this.cache = CacheFactory.getAnyInstance();
this.regionAttributesMetadataRegion = createRegionAttributesMetadataRegion();
}
public void execute(FunctionContext context) {
Object[] arguments = (Object[]) context.getArguments();
String regionName = (String) arguments[0];
RegionAttributes attributes = (RegionAttributes) arguments[1];
// Create or retrieve region
Status status = createOrRetrieveRegion(regionName, attributes);
// Return status
context.getResultSender().lastResult(status);
}
private Status createOrRetrieveRegion(String regionName,
RegionAttributes attributes) {
Status status = Status.SUCCESSFUL;
Region region = this.cache.getRegion(regionName);
if (region == null) {
// Put the attributes into the metadata region. The afterCreate call will
// actually create the region.
this.regionAttributesMetadataRegion.put(regionName, attributes);
// Retrieve the region after creating it
region = this.cache.getRegion(regionName);
if (region == null) {
status = Status.UNSUCCESSFUL;
}
} else {
status = Status.ALREADY_EXISTS;
}
return status;
}
private Region<String,RegionAttributes>
createRegionAttributesMetadataRegion() {
Region<String, RegionAttributes> metaRegion =
this.cache.getRegion(REGION_ATTRIBUTES_METADATA_REGION);
if (metaRegion == null) {
RegionFactory<String, RegionAttributes> factory =
this.cache.createRegionFactory();
factory.setDataPolicy(DataPolicy.REPLICATE);
factory.setScope(Scope.DISTRIBUTED_ACK);
factory.addCacheListener(new CreateRegionCacheListener());
metaRegion = factory.create(REGION_ATTRIBUTES_METADATA_REGION);
}
return metaRegion;
}
public String getId() {
return getClass().getSimpleName();
}
public boolean optimizeForWrite() {
return false;
}
public boolean isHA() {
return true;
}
public boolean hasResult() {
return true;
}
public void init(Properties properties) {
}
}
CreateRegionCacheListener类是一个缓存侦听器,它实现了两个方法:afterCreate()和afterRegionCreate()。 afterCreate()方法创建区域。 afterRegionCreate()方法使每个新服务器创建元数据区域中定义的所有区域。
#CreateRegionCacheListener.java
import org.apache.geode.cache.Cache;
import org.apache.geode.cache.CacheFactory;
import org.apache.geode.cache.Declarable;
import org.apache.geode.cache.EntryEvent;
import org.apache.geode.cache.Region;
import org.apache.geode.cache.RegionAttributes;
import org.apache.geode.cache.RegionEvent;
import org.apache.geode.cache.RegionExistsException;
import org.apache.geode.cache.util.CacheListenerAdapter;
import java.util.Map;
import java.util.Properties;
public class CreateRegionCacheListener
extends CacheListenerAdapter<String,RegionAttributes>
implements Declarable {
private Cache cache;
public CreateRegionCacheListener() {
this.cache = CacheFactory.getAnyInstance();
}
public void afterCreate(EntryEvent<String,RegionAttributes> event) {
createRegion(event.getKey(), event.getNewValue());
}
public void afterRegionCreate(RegionEvent<String,RegionAttributes> event) {
Region<String,RegionAttributes> region = event.getRegion();
for (Map.Entry<String,RegionAttributes> entry : region.entrySet()) {
createRegion(entry.getKey(), entry.getValue());
}
}
private void createRegion(String regionName, RegionAttributes attributes) {
if (this.cache.getLogger().fineEnabled()) {
this.cache.getLogger().fine(
"CreateRegionCacheListener creating region named: "
+ regionName + " with attributes: " + attributes);
}
try {
Region region = this.cache.createRegionFactory(attributes)
.create(regionName);
if (this.cache.getLogger().fineEnabled()) {
this.cache.getLogger().fine("CreateRegionCacheListener created: "
+ region);
}
System.out.println("CreateRegionCacheListener created: " + region);
} catch (RegionExistsException e) {/* ignore */}
}
public void init(Properties p) {
}
}
分区区域
除基本区域管理外,分区区域还包括高可用性选项,数据位置控制以及跨群集的数据平衡。
了解分区
要使用分区区域,您应该了解它们的工作方式以及管理它们的选项。
配置分区区域
规划主机和访问者成员的分区区域的配置和持续管理,并配置启动区域。
配置分区区域的桶数
确定要分配给分区区域的桶数,并相应地设置配置。
自定义分区和数据共置
您可以自定义Apache Geode如何使用自定义分区和数据同地对分区区域数据进行分组。
配置分区区域的高可用性
默认情况下,Apache Geode仅在区域的数据存储中存储分区区域数据的单个副本。 您可以配置Geode以维护分区区域数据的冗余副本,以实现高可用性。
配置对服务器分区区域的单跳客户端访问
单跳数据访问使客户端池能够跟踪分区区域的数据在服务器中的托管位置。 要访问单个条目,客户端将在一个跃点中直接联系承载key的服务器。
重新平衡分区区域数据
在对成员读取或更新并发线程的争用最小的群集中,您可以使用重新平衡来动态增加或减少数据和处理容量。
检查分区中的冗余
在某些情况下,验证分区区域数据是否为冗余并且在成员重新启动时,已跨分区区域成员正确恢复冗余非常重要。
将分区区域数据移动到另一个成员
您可以使用
PartitionRegionHelper,moveBucketByKey和moveData方法将分区区域数据从一个成员显式移动到另一个成员。
了解分区
要使用分区区域,您应该了解它们的工作方式以及管理它们的选项。
在操作期间,分区区域看起来像一个大的虚拟区域,具有定义区域的所有成员保持相同的逻辑视图。
对于您定义区域的每个成员,您可以选择允许区域数据存储的空间,包括根本没有本地存储。 无论本地存储多少,该成员都可以访问所有区域数据。
群集可以具有多个分区区域,并且可以将分区区域与分布区域和局部区域混合。 除了具有局部范围的区域之外,对于唯一区域名称的通常要求仍然适用。 单个成员可以托管多个分区区域。
数据分区
Geode自动确定托管分区区域数据的成员中数据的物理位置。 Geode将分区区域数据分解为称为存储区的存储单元,并将每个存储区存储在区域主机成员中。 存储桶根据成员的区域属性设置进行分配。
创建条目时,会将其分配给存储桶。 key组合在一个桶中并始终保留在那里。 如果配置允许,则可以在构件之间移动桶以平衡负载。
您必须运行所需的数据存储以适应分区区域的存储区。 您可以动态启动新的数据存储。 当新数据存储创建区域时,它负责分区区域和成员配置允许的桶数。
您可以自定义Geode如何使用自定义分区和数据同地对分区区域数据进行分组。
分区区域操作
分区区域的运行方式与分区范围的非分区区域非常相似。 大多数标准的Region方法都是可用的,尽管一些通常是本地操作的方法成为分布式操作,因为它们作为一个整体而不是本地缓存在分区区域上工作。 例如,分区区域中的put或create实际上可能不会存储到调用该操作的成员的高速缓存中。 检索任何条目只需要成员之间不超过一跳。
与其他区域一样,分区区域支持客户端/服务器模型。 如果需要将数十个客户端连接到单个分区区域,则使用服务器可以大大提高性能。
有关分区区域的其他信息
请记住有关分区区域的以下内容:
- 分区区域永远不会异步运行。 分区区域中的操作始终等待来自包含原始数据条目和任何冗余副本的高速缓存的确认。
- 分区区域需要每个区域数据存储中的缓存加载器(
local-max-memory> 0)。 - Geode在存储分区区域数据的所有成员之间尽可能均匀地分布数据桶,在您使用的任何自定义分区或数据同地的限制内。 分配区域分配的桶数决定了数据存储的粒度,从而决定了数据的均匀分布。 存储桶的数量是整个群集中整个区域的总数。
- 在重新平衡该地区的数据时,Geode移动存储桶,但不会在存储桶内移动数据。
- 您可以查询分区区域,但存在某些限制。 有关详细信息,请参阅查询分区区域 。
配置分区区域
规划主机和访问者成员的分区区域的配置和持续管理,并配置启动区域。
在开始之前,请了解基本配置和编程.
- 使用
PARTITION区域快捷键设置之一启动区域配置。 请参见区域快捷方式和自定义命名区域属性. - 如果您需要分区区域的高可用性,请为此配置。 请参见为分区区域配置高可用性.
- 估算该地区所需的空间量。 如果使用冗余,则这是存储在成员中的所有主副本和副副本的最大值。 例如,冗余为1时,每个区域数据条目需要的空间是没有冗余的两倍,因为条目存储了两次。 请参阅缓存数据的内存要求.
- 配置该区域的桶总数。 对于同地区域,此数字必须相同。 请参见配置分区区域的桶数.
- 为区域配置成员的数据存储和数据加载:
- 您可以让没有本地数据存储的成员和具有不同存储量的成员。 确定此区域的不同成员类型中可用的最大内存。 这些将在
partition-attributeslocal-max-memory中设置。 这是partition-attributes中唯一可以在成员之间变化的设置。 使用这些最大值和您对区域内存要求的估计值来帮助您计算该区域开始的成员数量。 - 对于存储区域数据的成员(
local-max-memory大于0),定义数据加载器。 请参阅实现数据加载器. - 如果您的成员没有本地数据存储(
local-max-memory设置为0),请检查系统启动/关闭过程。 当任何没有存储的成员正在运行时,请确保始终至少有一个成员具有本地数据存储。
- 您可以让没有本地数据存储的成员和具有不同存储量的成员。 确定此区域的不同成员类型中可用的最大内存。 这些将在
- 如果要自定义对区域中的数据进行分区,或者在多个区域之间同地数据,请相应地进行编码和配置。 请参阅了解自定义分区和数据同地.
- 规划您的分区重新平衡策略并为其配置和编程。 请参阅重新平衡分区区域数据.
注意: 要使用gfsh配置分区区域,请参阅gfsh命令帮助.
配置分区区域的桶数
确定要分配给分区区域的桶数,并相应地设置配置。
分区区域的存储区总数决定了数据存储的粒度,从而决定了数据的均匀分布。 Geode在数据存储中尽可能均匀地分配存储桶。 区域创建后,桶的数量是固定的。
分区属性total-num-buckets设置所有参与成员的整个分区区域的编号。 使用以下之一设置它:
XML:
<region name="PR1"> <region-attributes refid="PARTITION"> <partition-attributes total-num-buckets="7"/> </region-attributes> </region>Java:
RegionFactory rf = cache.createRegionFactory(RegionShortcut.PARTITION); rf.setPartitionAttributes(new PartitionAttributesFactory().setTotalNumBuckets(7).create()); custRegion = rf.create("customer");gfsh:
使用
create region命令的-total-num-buckets参数。 例如:gfsh>create region --name="PR1" --type=PARTITION --total-num-buckets=7
计算分区区域的桶总数
请遵循以下准则来计算分区区域的存储区总数:
- 使用素数。 这提供了最均匀的分布。
- 使其至少是您期望为该地区拥有的数据存储数量的四倍。 存储桶与数据存储的比率越大,负载在成员之间的分布越均匀。 但请注意,在负载平衡和开销之间存在折衷。 管理存储桶会带来很大的开销,尤其是冗余级别更高。
您试图避免某些成员拥有的数据条目明显多于其他成员的情况。 例如,比较接下来的两个数字。 该图显示了具有三个数据存储区和七个存储区的区域。 如果以大约相同的速率访问所有条目,则此配置在成员M3中创建热点,其具有比其他数据存储多大约50%的数据。 M3可能是一个缓慢的接收器和潜在的故障点。

配置更多存储桶可使存储桶中的条目更少,数据分布更均衡。 此图使用与以前相同的数据,但将桶数增加到13.现在数据条目的分布更均匀。

自定义分区和共享数据
您可以自定义Apache Geode如何使用自定义分区和数据同地对分区区域数据进行分组。
了解自定义分区和数据同地
自定义分区和数据同地可以单独使用,也可以相互结合使用。
标准自定义分区
默认情况下,Geode使用key上的散列策略将每个数据条目分区到一个存储桶中。 此外,键值对的物理位置从应用程序中抽象出来。 您可以通过提供标准分区解析程序来更改分区区域的这些策略,该分区解析程序将条目映射到称为分区的一组存储区。
固定的自定义分区
默认情况下,Geode使用key上的散列策略将每个数据条目分区到一个存储桶中。 此外,键值对的物理位置从应用程序中抽象出来。 您可以通过提供固定分区解析程序来更改分区区域的这些策略,该解析程序不仅将条目映射到称为分区的一组存储区,还指定哪些成员承载哪些数据存储区。
共享来自不同分区区域的数据
默认情况下,Geode为独立于任何其他分区区域的数据位置的分区区域分配数据位置。 您可以为任何分区区域组更改此策略,以便跨区域相关数据全部由同一成员托管。 某些操作需要进行同地,并通过减少对其他集群成员上托管的条目的数据访问次数来提高其他操作的性能。
了解自定义分区和数据同地
自定义分区和数据同地可以单独使用,也可以相互结合使用。
自定义分区
使用自定义分区将类似条目分组到区域内的区域存储桶中。 默认情况下,Geode根据条目键的哈希码为桶分配新条目。 通过自定义分区,您可以以任何方式将条目分配给存储桶。
如果使用自定义分区对区域内的类似数据进行分组,通常可以获得更好的性能。 例如,如果所有1月帐户数据都由单个成员托管,则在1月创建的所有帐户上运行的查询运行得更快。 为单个客户分组所有数据可以提高处理客户数据的数据操作的性能。 数据感知功能执行还利用了自定义分区。
使用自定义分区,您有两种选择:
标准自定义分区. 使用标准自定义分区,您可以将条目分组到存储区中,但不指定存储区所在的位置。 Geode始终将条目保留在您指定的存储区中,但可以移动存储区以进行负载平衡。 请参阅标准自定义分区 for implementation and configuration details.
固定的自定义分区. 使用固定的自定义分区,您可以指定每个区域条目所在的确切成员。 您将条目分配给分区,然后分配给该分区中的存储桶。 您将特定成员命名为每个分区的主要和辅助主机。
这使您可以完全控制该区域的主要和任何辅助存储桶的位置。 当您希望在特定物理机器上存储特定数据或需要将数据保持在某些硬件元素附近时,这非常有用。
固定分区具有以下要求和注意事项:
- Geode无法重新平衡固定分区区域数据,因为它无法在主机成员之间移动存储桶。 您必须仔细考虑您创建的分区的预期数据加载。
- 使用固定分区,主机成员之间的区域配置不同。 每个成员都标识它承载的命名分区,以及它是托管主副本还是主副本。 然后,您可以对固定分区解析程序进行编程以返回分区ID,因此该条目位于右侧成员上。 对于特定分区名称,只有一个成员可以是主要成员,并且该成员不能是该分区的辅助成员。
有关实现和配置细节,请参见固定自定义分区 。
区域之间的数据同地
通过数据同地,Geode在单个成员中存储跨多个数据区域相关的条目。 Geode通过将具有相同ID的所有区域桶一起存储在同一成员中来实现此目的。 在重新平衡操作期间,Geode将这些桶组移动到一起或根本不移动。
因此,例如,如果您有一个区域包含客户联系信息,另一个区域包含客户订单,您可以使用托管将单个客户的所有联系信息和所有订单保存在一个成员中。 这样,对单个客户执行的任何操作都只使用单个成员的缓存。
此图显示了具有数据同地的两个区域,其中数据按客户类型进行分区。

数据同地需要对所有同地区域使用相同的数据分区机制。 您可以使用Geode提供的默认分区或任何自定义分区策略。
您必须在同地区域中使用相同的高可用性设置。
有关实施和配置详细信息,请参阅来自不同分区区域的共存数据。
标准自定义分区
默认情况下,Geode使用key上的散列策略将每个数据条目分区到一个存储桶中。 此外,键值对的物理位置从应用程序中抽象出来。 您可以通过提供以自定义方式映射条目的标准自定义分区解析程序来更改分区区域的这些策略。
注意: 如果要同时进行区域数据和自定义分区,则所有同地区域必须使用相同的自定义分区机制。 请参阅来自不同分区区域的共存数据.
要自定义分区您的区域数据,请执行以下两个步骤:
- 实现接口
- 配置区域
实现标准自定义分区
以下列方式之一实现
org.apache.geode.cache.PartitionResolver接口,在Geode使用的搜索顺序中列出:- 使用自定义类. 在类中实现
PartitionResolver,然后在创建区域时将类指定为分区解析器。 - 使用key的类. 让条目key的类实现
PartitionResolver接口。 - 使用回调参数的类. 让实现你的回调参数的类实现
PartitionResolver接口。 使用此实现时,任何和所有Region操作必须是指定回调参数的操作。
- 使用自定义类. 在类中实现
实现解析器的
getName,init和close方法。getName的简单实现是return getClass().getName();init方法在高速缓存启动时执行与分区解析器任务相关的任何初始化步骤。 仅当使用由gfsh或XML(在cache.xml文件中)配置的自定义类时才会调用此方法。close方法完成在缓存关闭完成之前必须完成的任何清理。 例如,close可能会关闭分区解析器打开的文件或连接。实现解析器的
getRoutingObject方法以返回每个条目的路由对象。 返回的路由对象的哈希值确定存储桶。 因此,getRoutingObject应该返回一个对象,该对象在通过其hashCode运行时,将分组对象定向到所需的存储桶。注意: 只有
getKey返回的键应该由getRoutingObject使用。 不要在getRoutingObject的实现中使用与键相关联的值或任何其他元数据。 不要使用getOperation或getValue。
实现字符串前缀分区解析器
Geode在org.apache.geode.cache.util.StringPrefixPartitionResolver中提供了基于字符串的分区解析器的实现。 该解析器不需要任何进一步的实现。 它根据key的一部分将条目分组到存储桶中。 所有键必须是字符串,每个键必须包含一个’|’字符,用于分隔字符串。 在键中的’|’分隔符之前的子字符串将由getRoutingObject返回。
配置分区解析程序区域属性
配置区域,以便Geode找到所有区域操作的解析器。
自定义类. 使用以下方法之一指定分区解析程序区域属性:
gfsh:
将选项
--partition-resolver添加到gfsh create region命令,指定标准自定义分区解析程序的包和类名。字符串前缀分区解析器的gfsh:
将
--partition-resolver = org.apache.geode.cache.util.StringPrefixPartitionResolver选项添加到gfsh create region命令。Java API:
PartitionResolver resolver = new TradesPartitionResolver(); PartitionAttributes attrs = new PartitionAttributesFactory() .setPartitionResolver(resolver).create(); Cache c = new CacheFactory().create(); Region r = c.createRegionFactory() .setPartitionAttributes(attrs) .create("trades");字符串前缀分区解析器的Java API:
PartitionAttributes attrs = new PartitionAttributesFactory() .setPartitionResolver(new StringPrefixPartitionResolver()).create(); Cache c = new CacheFactory().create(); Region r = c.createRegionFactory() .setPartitionAttributes(attrs) .create("customers");XML:
<region name="trades"> <region-attributes> <partition-attributes> <partition-resolver> <class-name>myPackage.TradesPartitionResolver </class-name> </partition-resolver> <partition-attributes> </region-attributes> </region>字符串前缀分区解析器的XML:
<region name="customers"> <region-attributes> <partition-attributes> <partition-resolver> <class-name>org.apache.geode.cache.util.StringPrefixPartitionResolver </class-name> </partition-resolver> <partition-attributes> </region-attributes> </region>如果您的同地数据位于服务器系统中,请将
PartitionResolver实现类添加到Java客户端的CLASSPATH中。 对于Java单跳访问,解析器类需要具有零参数构造函数,并且解析器类不能具有任何状态;init方法包含在此限制中。
固定的自定义分区
默认情况下,Geode使用密钥上的散列策略将每个数据条目分区到一个存储桶中。 此外,键值对的物理位置从应用程序中抽象出来。 您可以通过提供固定的自定义分区解析程序来更改分区区域的这些策略,该解析程序不仅将条目映射到称为分区的一组存储区,还指定哪些成员承载哪些数据存储区。
注意: 如果要同时进行区域数据和自定义分区,则所有同地区域必须使用相同的自定义分区机制。 请参阅来自不同分区区域的同地数据.
要自定义分区您的区域数据,请执行以下两个步骤:
- 实现接口
- 配置区域
这些步骤根据使用的分区解析程序而有所不同。
实现固定自定义分区
在以下位置之一中实现
org.apache.geode.cache.FixedPartitionResolver接口,这些位置在Geode使用的搜索顺序中列出:- 自定义类. 在区域创建期间将此类指定为分区解析程序。
- 条目 key. 对于作为对象实现的键,定义键类的接口。
- 在缓存回调类中. 在缓存回调的类中实现接口。 使用此实现时,任何和所有
Region操作必须是将回调指定为参数的操作。
实现解析器的
getName,init和close方法。getName的简单实现是return getClass().getName();init方法在高速缓存启动时执行与分区解析器任务相关的任何初始化步骤。close方法完成在缓存关闭完成之前必须完成的任何清理。 例如,close可能会关闭分区解析器打开的文件或连接。实现解析器的
getRoutingObject方法以返回每个条目的路由对象。 返回的路由对象的哈希值确定分区内的存储区。对于每个分区只有一个存储区的固定分区,此方法可以为空。 该实现将分区分配给服务器,以便应用程序完全控制服务器上的分组条目。
注意: 创建路由对象时,只应使用key上的字段。 不要为此目的使用值或其他元数据。
实现
getPartitionName方法,根据您希望条目驻留的位置,为每个条目返回分区的名称。 分区中的所有条目都将位于单个服务器上。此示例根据日期放置数据,每个季度使用不同的分区名称,每个月使用不同的路由对象。
/** * Returns one of four different partition names * (Q1, Q2, Q3, Q4) depending on the entry's date */ class QuarterFixedPartitionResolver implements FixedPartitionResolver<String, String> { @Override public String getPartitionName(EntryOperation<String, String> opDetails, Set<String> targetPartitions) { Date date = (Date)opDetails.getKey(); Calendar cal = Calendar.getInstance(); cal.setTime(date); int month = cal.get(Calendar.MONTH); if (month >= 0 && month < 3) { if (targetPartitions.contains("Q1")) return "Q1"; } else if (month >= 3 && month < 6) { if (targetPartitions.contains("Q2")) return "Q2"; } else if (month >= 6 && month < 9) { if (targetPartitions.contains("Q3")) return "Q3"; } else if (month >= 9 && month < 12) { if (targetPartitions.contains("Q4")) return "Q4"; } return "Invalid Quarter"; } @Override public String getName() { return "QuarterFixedPartitionResolver"; } @Override public Serializable getRoutingObject(EntryOperation<String, String> opDetails) { Date date = (Date)opDetails.getKey(); Calendar cal = Calendar.getInstance(); cal.setTime(date); int month = cal.get(Calendar.MONTH); return month; } @Override public void close() { } }
配置固定自定义分区
为每个成员设置固定分区属性。
这些属性定义成员为区域存储的数据,并且对于不同的成员必须是不同的。 有关属性的定义,请参阅
org.apache.geode.cache.FixedPartitionAttributes。 在区域的数据主机成员中定义每个partition-name。 对于每个分区名称,在要托管主副本的成员中,使用is-primary设置为true来定义它。 在要托管辅助副本的每个成员中,使用is-primary设置为false(默认值)来定义它。 辅助数量必须与您为该区域定义的冗余副本数相匹配。 请参见为分区区域配置高可用性.注意: 分区的存储桶仅由已在其
FixedPartitionAttributes中定义分区名称的成员托管。这些示例将成员的分区属性设置为“Q1”分区数据的主要主机和“Q3”分区数据的辅助主机。
XML:
<cache> <region name="Trades"> <region-attributes> <partition-attributes redundant-copies="1"> <partition-resolver> <class-name>myPackage.QuarterFixedPartitionResolver</class-name> </partition-resolver> <fixed-partition-attributes partition-name="Q1" is-primary="true"/> <fixed-partition-attributes partition-name="Q3" is-primary="false" num-buckets="6"/> </partition-attributes> </region-attributes> </region> </cache>Java:
FixedPartitionAttribute fpa1 = FixedPartitionAttributes .createFixedPartition("Q1", true); FixedPartitionAttribute fpa3 = FixedPartitionAttributes .createFixedPartition("Q3", false, 6); PartitionAttributesFactory paf = new PartitionAttributesFactory() .setPartitionResolver(new QuarterFixedPartitionResolver()) .setTotalNumBuckets(12) .setRedundantCopies(2) .addFixedPartitionAttribute(fpa1) .addFixedPartitionAttribute(fpa3); Cache c = new CacheFactory().create(); Region r = c.createRegionFactory() .setPartitionAttributes(paf.create()) .create("Trades");gfsh:
您不能使用gfsh指定固定分区解析程序。
如果您的同地数据位于服务器系统中,请将实现
FixedPartitionResolver接口的类添加到Java客户端的CLASSPATH中。 对于Java单跳访问,解析器类需要具有零参数构造函数,并且解析器类不能具有任何状态;init方法包含在此限制中。
共享来自不同分区区域的数据
默认情况下,Geode为独立于任何其他分区区域的数据位置的分区区域分配数据位置。 您可以为任何分区区域组更改此策略,以便跨区域相关数据全部由同一成员托管。 某些操作需要进行同地,并通过减少对其他集群成员上托管的条目的数据访问次数来提高其他操作的性能。
分区区域之间的数据同地通常可以提高数据密集型操作的性能。 您可以减少网络跃点,以便对相关数据集进行迭代操作。 数据密集型的计算密集型应用程序可以显着提高整体吞吐量。 例如,如果所有数据都分组在一个成员中,则对患者的健康记录,保险和账单信息运行的查询会更有效。 同样,如果所有交易,风险敏感度和与单个工具相关的参考数据在一起,则金融风险分析应用程序运行得更快。
步骤
将一个区域标识为中心区域,明确地将其他区域中的数据与其区分开来。 如果对任何区域使用持久性,则必须保留中心区域。
在创建其他区域之前创建中心区域,可以在
cache.xml或代码中创建。 XML中的区域是在代码中的区域之前创建的,因此如果在XML中创建任何共处区域,则必须先在XML中创建中心区域,然后再创建其他区域。 Geode将在其他人创建时验证其存在,如果中心区域不存在则返回IllegalStateException。 不要向此中心区域添加任何托管规范。对于所有其他区域,在区域分区属性中,在
colocated-with属性中提供中心区域的名称。 使用以下方法之一:XML:
<cache> <region name="trades"> <region-attributes> <partition-attributes> ... <partition-attributes> </region-attributes> </region> <region name="trade_history"> <region-attributes> <partition-attributes colocated-with="trades"> ... <partition-attributes> </region-attributes> </region> </cache>Java:
PartitionAttributes attrs = ... Region trades = new RegionFactory().setPartitionAttributes(attrs) .create("trades"); ... attrs = new PartitionAttributesFactory().setColocatedWith(trades.getFullPath()) .create(); Region trade_history = new RegionFactory().setPartitionAttributes(attrs) .create("trade_history");gfsh:
gfsh>create region --name="trades" type=PARTITION gfsh> create region --name="trade_history" --colocated-with="trades"
对于每个同地区域,对与存储区管理相关的这些分区属性使用相同的值:
recovery-delayredundant-copiesstartup-recovery-delaytotal-num-buckets
如果您自定义分区您的区域数据,请为所有同地区域指定自定义解析程序。 此示例对两个区域使用相同的分区解析程序:
XML:
<cache> <region name="trades"> <region-attributes> <partition-attributes> <partition-resolver name="TradesPartitionResolver"> <class-name>myPackage.TradesPartitionResolver </class-name> <partition-attributes> </region-attributes> </region> <region name="trade_history"> <region-attributes> <partition-attributes colocated-with="trades"> <partition-resolver name="TradesPartitionResolver"> <class-name>myPackage.TradesPartitionResolver </class-name> <partition-attributes> </region-attributes> </region> </cache>Java:
PartitionResolver resolver = new TradesPartitionResolver(); PartitionAttributes attrs = new PartitionAttributesFactory() .setPartitionResolver(resolver).create(); Region trades = new RegionFactory().setPartitionAttributes(attrs) .create("trades"); attrs = new PartitionAttributesFactory() .setColocatedWith(trades.getFullPath()).setPartitionResolver(resolver) .create(); Region trade_history = new RegionFactory().setPartitionAttributes(attrs) .create("trade_history");gfsh:
指定分区解析程序,如[自定义分区您的区域数据]的配置部分所述(https://geode.apache.org/docs/guide/17/developing/partitioned_regions/using_custom_partition_resolvers.html).
如果要在同地区域中保留数据,请保留中心区域,然后根据需要保留其他区域。 对您保留的所有共存区域使用相同的磁盘存储。
配置分区区域的高可用性
默认情况下,Apache Geode仅在区域的数据存储中存储分区区域数据的单个副本。 您可以配置Geode以维护分区区域数据的冗余副本,以实现高可用性。
了解分区区域的高可用性
凭借高可用性,为分区区域托管数据的每个成员都会获得一些主副本和一些冗余(辅助)副本。
配置分区区域的高可用性
为分区区域配置内存中高可用性。 设置其他高可用性选项,例如冗余区域和冗余恢复策略。
了解分区区域的高可用性
凭借高可用性,为分区区域托管数据的每个成员都会获得一些主副本和一些冗余(辅助)副本。
使用冗余时,如果一个成员发生故障,则操作将在分区区域继续运行,而不会中断服务:
- 如果托管主副本的成员丢失,Geode会将辅助副本作为主副本。 这可能会导致暂时的冗余丢失,但不会导致数据丢失。
- 只要没有足够的辅助副本来满足冗余,系统就会通过将另一个成员分配为辅助副本并将数据复制到其中来恢复冗余。
注意: 如果足够的成员在足够短的时间内发生故障,您仍然可以在使用冗余时丢失缓存数据。
您可以配置系统在不满足时如何恢复冗余。 您可以将恢复配置为立即执行,或者,如果您希望为替换成员提供启动机会,则可以配置等待期。 在任何分区数据重新平衡操作期间,还会自动尝试冗余恢复。 使用gemfire.MAX_PARALLEL_BUCKET_RECOVERIES系统属性配置并行恢复的最大桶数。 默认情况下,系统尝试恢复冗余时,最多可并行恢复8个存储桶。
如果没有冗余,丢失任何区域的数据存储都会导致丢失某些区域的缓存数据。 通常,当应用程序可以直接从其他数据源读取,或者写入性能比读取性能更重要时,不应使用冗余。
控制你的初级和二级居住地
默认情况下,Geode会为您放置主数据副本和辅助数据副本,从而避免在同一台物理计算机上放置两个副本。 如果没有足够的机器将不同的副本分开,Geode会将副本放在同一台物理计算机上。 您可以更改此行为,因此Geode仅将副本放在不同的计算机上。
您还可以控制哪些成员存储主数据副本和辅助数据副本。 Geode提供两种选择:
- 固定自定义分区. 为该区域设置此选项。 固定分区使您可以绝对控制托管区域数据的位置。 通过固定分区,您可以为Geode提供代码,该代码为区域中的每个数据条目指定存储桶和数据存储。 将此选项与冗余配合使用时,可以指定主数据存储和辅助数据存储。 固定分区不参与重新平衡,因为您固定了所有存储桶位置。
- 冗余区域. 此选项在成员级别设置。 冗余区域允许您按成员组或区域分隔主副本副本。 您将每个数据主机分配给区域。 然后Geode将冗余副本放在不同的冗余区域中,就像在不同的物理机器上放置冗余副本一样。 您可以使用此选项在不同的机架或网络中拆分数据副本。此选项允许您动态添加成员并使用重新平衡来重新分配数据负载,并在单独的区域中维护冗余数据。 使用冗余区域时,Geode不会在同一区域中放置两个数据副本,因此请确保您有足够的区域。
在虚拟机中运行进程
默认情况下,Geode将冗余副本存储在不同的计算机上。 在虚拟机中运行进程时,计算机的常规视图将成为VM而非物理计算机。 如果在同一台物理计算机上运行多个VM,则最终可能会将分区区域主存储区存储在单独的VM中,但与第二个存储区位于同一物理计算机上。 如果物理机出现故障,您可能会丢失数据。 在VM中运行时,可以将Geode配置为标识物理计算机并将冗余副本存储在不同的物理计算机上。
在高可用分区区域中进行读写
Geode在高可用性分区区域中对读取和写入的处理方式与在其他区域中不同,因为数据在多个成员中可用:
- 写操作(如
put和create)转到数据键的主要操作,然后同步分发到冗余副本。 事件被发送到配置了subscription-attributesintece-policy设置为all的成员。 - 读操作会转到任何持有数据副本的成员,并且本地缓存很受欢迎,因此读取密集型系统可以更好地扩展并处理更高的负载。
在此图中,M1正在读取W,Y和Z.它直接从其本地副本获取W. 由于它没有Y或Z的本地副本,因此它会进入缓存,随机选择源缓存。

配置分区区域的高可用性
为分区区域配置内存中高可用性。 设置其他高可用性选项,例如冗余区域和冗余恢复策略。
以下是为分区区域配置高可用性的主要步骤。 请参阅后面的部分了解详情
- 设置系统应保留区域数据的冗余副本数。 请参阅设置冗余份数.
- (可选)如果要将数据存储成员分组到冗余区域,请相应地进行配置。 请参见为成员配置冗余区域.
- (可选)如果希望Geode仅将冗余副本放在不同的物理计算机上,请为此配置。 请参阅设置强制唯一主机.
- 决定如何管理冗余恢复并根据需要更改Geode的默认行为。
- 成员崩溃后. 如果要进行自动冗余恢复,请更改其配置。 请参见为分区区域配置成员崩溃冗余恢复.
- 成员加入后. 如果您不希望立即进行自动冗余恢复,请更改配置。 请参见为分区区域配置成员加入冗余恢复.
- 确定Geode在执行冗余恢复时应尝试并行恢复的桶数。 默认情况下,系统最多可并行恢复8个存储桶。 使用
gemfire.MAX_PARALLEL_BUCKET_RECOVERIES系统属性可以在执行冗余恢复时增加或减少并行恢复的最大桶数。 - 对于除固定分区区域之外的所有区域,请查看启动重新平衡的点。 冗余恢复在任何重新平衡开始时自动完成。 如果在成员崩溃或加入后没有自动恢复运行,这是最重要的。 请参阅重新平衡分区区域数据.
在运行时,您可以通过添加区域的新成员来添加容量。 对于不使用固定分区的区域,您还可以启动重新平衡操作以在所有成员之间传播区域存储桶。
设置冗余副本数
通过指定要在区域数据存储中维护的辅助副本数,为分区区域配置内存中高可用性。
为成员配置冗余区域
将成员分组到冗余区域,以便Geode将冗余数据副本分成不同的区域。
设置强制唯一主机
将Geode配置为仅使用唯一的物理机器来分区区域数据的冗余副本。
为分区区域配置成员崩溃冗余恢复
配置成员崩溃后是否以及如何在分区区域中恢复冗余。
为分区区域配置成员加入冗余恢复
配置成员加入后是否以及如何在分区区域中恢复冗余。
设置冗余副本数
通过指定要在区域数据存储中维护的辅助副本数,为分区区域配置内存中高可用性。
在分区属性redundant-copies设置中指定分区区域数据所需的冗余副本数。 默认设置为0。
例如:
XML:
<region name="PR1"> <region-attributes refid="PARTITION"> <partition-attributes redundant-copies="1"/> </region-attributes> </region>Java:
PartitionAttributes pa = new PartitionAttributesFactory().setRedundantCopies(1).create();gfsh:
gfsh>create region --name="PR1" --type=PARTITION --redundant-copies=1
为成员配置冗余区域
将成员分组到冗余区域,以便Geode将冗余数据副本分成不同的区域。
了解如何设置成员的'gemfire.properties`设置。 见参考.
使用gemfire.properties设置redundancy-zone将分区区域主机分组到冗余区域。
例如,如果将冗余设置为1,那么每个数据条目都有一个主副本和一个副副本,则可以通过为每个机架定义一个冗余区域,在两个计算机机架之间拆分主数据副本和辅助数据副本。 为此,您可以在gemfire.properties中为在一个机架上运行的所有成员设置此区域:pre redundancy-zone = rack1
你可以为另一个机架上的所有成员设置这个区域gemfire.properties:pre redundancy-zone = rack2
每个辅助副本都将托管在托管其主要副本的机架对面的机架上。
设置强制唯一主机
将Geode配置为仅使用唯一的物理机器来分区区域数据的冗余副本。
Understand how to set a member’s gemfire.properties settings. See Reference.
配置您的成员,以便Geode始终使用不同的物理机器使用gemfire.properties设置enforce-unique-host来分区区域数据的冗余副本。 此设置的默认值为false。
例子:
enforce-unique-host=true
为分区区域配置成员崩溃冗余恢复
配置成员崩溃后是否以及如何在分区区域中恢复冗余。
使用partition属性recovery-delay指定成员崩溃冗余恢复。
| 恢复延迟分区属性 | 会员失败后的效果 |
|---|---|
| -1 | 成员失败后无法自动恢复冗余。 这是默认值。 |
| 大于或等于0 | 在恢复冗余之前成员发生故障后要等待的毫秒数。 |
默认情况下,成员崩溃后不会恢复冗余。 如果您希望快速重新启动大多数崩溃的成员,将此默认设置与成员加入冗余恢复相结合可以帮助您在成员关闭时避免不必要的数据重排。 通过等待丢失的成员重新加入,使用新启动的成员完成冗余恢复,并且使用较少的处理来更好地平衡分区。
使用以下方法之一设置崩溃冗余恢复:
XML:
// Give a crashed member 10 seconds to restart // before recovering redundancy <region name="PR1"> <region-attributes refid="PARTITION"> <partition-attributes recovery-delay="10000"/> </region-attributes> </region>Java:
PartitionAttributes pa = new PartitionAttributesFactory().setRecoveryDelay(10000).create();gfsh:
gfsh>create region --name="PR1" type=PARTITION --recovery-delay=10000
为分区区域配置成员加入冗余恢复
本节介绍配置成员加入后是否以及如何在分区区域中恢复冗余。
使用partition属性startup-recovery-delay指定成员加入冗余恢复。
startup-recovery-delay的值 |
成员加入后的效果 |
|---|---|
| -1 | 新成员上线后无法自动恢复冗余。 使用此值和默认的recovery-delay设置,冗余恢复仅通过重新平衡操作来实现。 |
| long >= 0 | 成员加入恢复冗余之前等待的毫秒数。 默认值为0(零),只要承载分区区域的成员加入,就会立即执行冗余恢复。 |
将startup-recovery-delay设置为高于默认值0的值允许多个新成员在冗余恢复开始之前加入。 在恢复期间存在多个成员时,系统将在它们之间扩展冗余恢复。 如果没有延迟,如果紧密连续启动多个成员,则系统可以仅选择为大多数或所有冗余恢复启动的第一个成员。
注意: 满足冗余与增加容量不同。 如果满足冗余,则新成员在调用重新平衡操作之前不会获取桶。
并行恢复实施迅速恢复。 因此,在同时重新启动多个成员时,将startup-recovery-delay配置为适当的值更为重要。 将startup-recovery-delay设置为一个值,确保所有成员在冗余恢复启动之前都已启动并可用。
使用以下方法之一设置加入冗余恢复:
XML:
// Wait 5 seconds after a new member joins before // recovering redundancy <region name="PR1"> <region-attributes refid="PARTITION"> <partition-attributes startup-recovery-delay="5000"/> </region-attributes> </region>Java:
PartitionAttributes pa = new PartitionAttributesFactory().setStartupRecoveryDelay(5000).create();gfsh:
gfsh>create region --name="PR1" --type=PARTITION --startup-recovery-delay=5000
配置对服务器分区区域的单跳客户端访问
单跳数据访问使客户端池能够跟踪分区区域的数据在服务器中的托管位置。 要访问单个条目,客户端将在一个跃点中直接联系承载key的服务器。
了解客户端对服务器分区区域的单跳访问
通过单跳访问,客户端连接到每个服务器,因此通常使用更多连接。 这适用于较小的安装,但是缩放的障碍。
配置客户端对服务器分区区域的单跳访问
配置客户端/服务器系统,以便直接,单跳访问服务器中的分区区域数据。
了解客户端对服务器分区区域的单跳访问
通过单跳访问,客户端连接到每个服务器,因此通常使用更多连接。 这适用于较小的安装,但是缩放的障碍。
如果您具有包含许多客户端的大型安装,则可能需要通过在池声明中将池属性pr-single-hop-enabled设置为false来禁用单跳。
如果没有单跳,客户端将使用任何可用的服务器连接,与所有其他操作相同。 接收请求的服务器确定数据位置并与主机联系,主机可能是不同的服务器。 因此,对服务器系统进行了更多的多跳请求。
注意: 单跳用于以下操作:put,get,destroy,putAll,getAll,removeAll和onRegion函数执行。
即使启用了单跳访问,您偶尔也会看到一些多跳行为。 要执行单跳数据访问,客户端会自动从服务器获取有关托管条目所在位置的元数据。 元数据是懒惰的。 它仅在单跳操作最终需要多跳之后更新,这是客户端中陈旧元数据的指示。
单跳和池最大连接设置
不要在启用单跳的情况下设置池的max-connections设置。 使用单跳限制池的连接可能会导致连接抖动,吞吐量丢失和服务器日志膨胀。
如果您需要限制池的连接,请禁用单跳或密切关注系统中的这些负面影响。
但是,对连接设置无限制可能会导致与服务器的连接过多,从而可能导致您遇到系统的文件句柄限制。 检查您预期的连接使用情况,并确保您的服务器能够容纳它。
平衡单跳服务器连接使用
当您的服务器之间的数据访问平衡良好时,单跳可带来最大的好处。 特别是,如果您将这些负载组合在一起,客户端/服务器连接的负载可能会失去平衡:
- 作为空数据访问器或不承载客户端通过单键操作访问的数据的服务器
- 来自客户的许多单键操作
如果数据访问大大失衡,客户端可能会尝试访问数据服务器。 在这种情况下,禁用单跳并通过不托管数据的服务器可能会更快。
配置客户端对服务器分区区域的单跳访问
配置客户端/服务器系统,以便直接,单跳访问服务器中的分区区域数据。
这需要在服务器上使用一个或多个分区区域的客户端/服务器安装。
- 验证客户端的池属性,未设置
pr-single-hop-enabled或设置为true。 默认情况下是这样。 - 如果可能,将池的
max-connections保留为默认的无限设置(-1)。 - 如果可能,请使用自定义数据解析程序根据客户端的数据使用模式对服务器区域数据进行分区。 请参阅自定义 - 分区您的区域数据. 在客户端的
CLASSPATH中包含服务器的分区解析器实现。 服务器为每个自定义分区区域传递解析程序的名称,因此客户端使用正确的分区。 如果服务器不使用分区解析器,则服务器和客户端之间的默认分区匹配,因此单跳工作。 - 将单跳注意事项添加到整个服务器负载平衡计划中。 单跳使用数据位置而不是最少加载的服务器来选择服务器以进行单键操作。 不均衡的单跳数据访问会影响整体客户端/服务器负载平衡。 一些平衡是自动完成的,因为具有更多单键操作的服务器变得更加负载,并且不太可能被挑选用于其他操作。
重新平衡分区区域数据
在对成员读取或更新并发线程的争用最小的群集中,您可以使用重新平衡来动态增加或减少数据和处理容量。
重新平衡是一项成员操作。 它会影响成员定义的所有分区区域,无论成员是否承载区域的数据。 重新平衡操作执行两项任务:
- 如果不满足配置的分区区域冗余,则重新平衡会尽其所能来恢复冗余。 请参见为分区区域配置高可用性.
- 重新平衡根据需要在主机成员之间移动分区区域数据桶,以在集群中建立最公平的数据和行为平衡。
为了提高效率,在启动多个成员时,在添加所有成员后,一次触发重新平衡。
注意: 如果您的系统中正在运行事务,请务必规划重新平衡操作。 重新平衡可能会在成员之间移动数据,这可能会导致正在运行的事务失败并出现TransactionDataRebalancedException。 修复了自定义分区,完全阻止了重新平衡。 除非您在不同时间运行事务和重新平衡操作,否则所有其他数据分区策略都允许重新平衡并导致此异常。
使用以下方法之一启动重新平衡:
gfsh命令。 首先,启动gfsh提示并连接到集群。 然后键入以下命令:gfsh>rebalance(可选)您可以指定要在重新平衡中包含或排除的区域,为重新平衡操作指定超时或仅模拟重新平衡操作. 输入
help rebalance或查看rebalance 以获取更多信息。API 调用:
ResourceManager manager = cache.getResourceManager(); RebalanceOperation op = manager.createRebalanceFactory().start(); //Wait until the rebalance is complete and then get the results RebalanceResults results = op.getResults(); //These are some of the details we can get about the run from the API System.out.println("Took " + results.getTotalTime() + " milliseconds\n"); System.out.println("Transfered " + results.getTotalBucketTransferBytes()+ "bytes\n");
您还可以通过API模拟重新平衡,以查看是否值得运行:
ResourceManager manager = cache.getResourceManager();
RebalanceOperation op = manager.createRebalanceFactory().simulate();
RebalanceResults results = op.getResults();
System.out.println("Rebalance would transfer " + results.getTotalBucketTransferBytes() +" bytes ");
System.out.println(" and create " + results.getTotalBucketCreatesCompleted() + " buckets.\n");
分区区域重新平衡的工作原理
重新平衡操作以异步方式运行。
默认情况下,一次在一个分区区域上执行重新平衡。 对于具有共处置数据的区域,重新平衡作为一个组在区域上工作,维护区域之间的数据共置。
您可以选择通过设置gemfire.resource.manager.threads系统属性来并行重新平衡多个区域。 将此属性设置为大于1的值可使Geode在使用API启动重新平衡操作时并行重新平衡多个区域。
在重新平衡正在进行时,您可以继续正常使用分区区域。 数据移动时,继续执行读操作,写操作和函数执行。 如果函数正在本地数据集上执行,则在函数执行期间,如果该数据移动到另一个主机,则可能会出现性能下降。 将来的函数调用将路由到正确的成员。
Geode尝试确保每个成员具有与每个分区区域相同的可用空间百分比。 百分比在partition-attributes和local-max-memory设置中配置。
分区重新平衡:
- 除非通过溢出到磁盘启用LRU驱逐,否则不允许超出
local-max-memory设置。 - 尽可能将同一存储桶的多个副本放在不同的主机IP地址上。
- 在存储桶迁移期间重置实时和空闲时间统计信息的输入时间。
- 替换离线成员。
何时重新平衡分区区域
您通常希望在成员启动,关闭或失败时增加或减少容量时触发重新平衡。
您可能还需要在以下时间重新平衡:
- 您使用冗余实现高可用性,并将您的区域配置为在丢失后不自动恢复冗余。 在这种情况下,Geode仅在您调用重新平衡时恢复冗余。 请参见为分区区域配置高可用性.
- 您有不均匀的数据散列。 如果您的key没有哈希代码方法(确保均匀分布),或者如果使用
PartitionResolver来分配分区区域数据(请参阅来自不同分区区域的共存数据),则可能会出现不均匀的哈希。在任何一种情况下,一些桶可能比其他桶接收更多数据。 通过在托管大型存储桶的成员上放置更少的存储桶,可以使用重新平衡来平衡数据存储之间的负载。
如何模拟区域重新平衡
您可以通过使用以下选项执行rebalance命令来移动任何实际数据之前模拟重新平衡操作:
gfsh>rebalance --simulate
注意: 如果您使用heap_lru进行数据驱逐,您可能会注意到模拟结果与实际重新平衡结果之间存在差异。 这种差异可能是由于VM在您执行模拟后开始逐出条目。 然后,当您执行实际的重新平衡操作时,操作将根据较新的堆大小做出不同的决定。
自动重新平衡
实验自动重新平衡功能 会根据时间表触发重新平衡操作。
检查分区中的冗余
在某些情况下,验证分区区域数据是否为冗余并且在成员重新启动时,已跨分区区域成员正确恢复冗余非常重要。
您可以通过确保所有分区区域的numBucketsWithoutRedundancy统计数值为零来验证分区区域冗余。 要检查此统计信息,请使用以下gfsh命令:
gfsh>show metrics --categories=partition --region=region_name
例如:
gfsh>show metrics --categories=partition --region=posts
Cluster-wide Region Metrics
--------- | --------------------------- | -----
partition | putLocalRate | 0
| putRemoteRate | 0
| putRemoteLatency | 0
| putRemoteAvgLatency | 0
| bucketCount | 1
| primaryBucketCount | 1
| numBucketsWithoutRedundancy | 1
| minBucketSize | 1
| maxBucketSize | 0
| totalBucketSize | 1
| averageBucketSize | 1
如果为分区区域配置了start-recovery-delay=-1,则需要在重新启动群集中的任何成员后对区域执行重新平衡,以便恢复冗余。
如果将start-recovery-delay设置为较低的数字,则可能需要等待额外的时间,直到该区域恢复冗余。
将分区区域数据移动到另一个成员
您可以使用PartitionRegionHelper moveBucketByKey和moveData方法将分区区域数据从一个成员显式移动到另一个成员。
moveBucketByKey方法将包含指定键的存储桶从源成员移动到目标成员。 例如,您可以使用该方法将流行的产品项移动到新的空成员,以减少源成员的负载。
例如:
Object product = ...
Region r = ...
DistributedSystem ds = ...
String memberName = ...
//Find the member that is currently hosting the product.
Set<DistributedMember> sourceMembers =
PartitionRegionHelper.getAllMembersForKey(r, product);
//Find the member to move the product to.
DistributedMember destination = ds.findDistributedMember(memberName);
//In this example we assume there is always at least one source.
//In practice, you should check that at least one source
//for the data is available.
source = sourceMembers.iterator().next();
//Move the bucket to the new node. The bucket will
//be moved when this method completes. It throws an exception
//if there is a problem or invalid arguments.
PartitionRegionHelper.moveBucketByKey(r, source, destination, product);
有关更多详细信息,请参阅org.apache.geode.cache.partition.PartitionRegionHelper.moveBucketByKey的Java API文档。
moveData方法将数据从源成员移动到目标成员的给定百分比(以字节为单位)。 例如,您可以使用此方法将指定百分比的数据从重载成员移动到另一个成员以改进分发。
例如:
Region r = ...
DistributedSystem ds = ...
String sourceName = ...
String destName = ...
//Find the source member.
DistributedMember source = ds.findDistributedMember(sourceName);
DistributedMember destination = ds.findDistributedMember(destName);
//Move up to 20% of the data from the source to the destination node.
PartitionRegionHelper.moveData(r, source, destination, 20);
有关更多详细信息,请参阅org.apache.geode.cache.partition.PartitionRegionHelper.moveData的Java API文档。
有关分区区域和重新平衡的更多信息,请参阅分区区域.
分布式和复制区域
除基本区域管理外,分布式和复制区域还包括推送和分配模型,全局锁定和区域条目版本等选项,以确保Geode成员之间的一致性。
分布式如何运作
要使用分布式和复制区域,您应该了解它们的工作方式以及管理它们的选项。
区域分布选项
您可以使用包含和不包含确认的分发,或使用区域分布的全局锁定。 配置为通过确认分发的区域也可以配置为在托管该区域的所有Geode成员之间一致地解析并发更新。
复制和预加载的工作原理
要使用复制和预加载区域,您应该了解如何在缓存中初始化和维护其数据。
配置分布式,复制和预加载区域
规划分布式,复制和预加载区域的配置和持续管理,并配置区域。
锁定全局区域
在全局区域中,系统在更新期间锁定条目和区域。 您还可以根据应用程序的需要显式锁定区域及其条目。 锁定包括系统设置,可帮助您优化性能并锁定成员之间的行为。
分布式如何运作
要使用分布式和复制区域,您应该了解它们的工作方式以及管理它们的选项。
注意: 复制和分布式区域的管理补充了基本配置和编程中提供的用于管理数据区域的一般信息。 另请参见org.apache.geode.cache.PartitionAttributes。
分布式区域自动将条目值更新发送到远程高速缓存并从它们接收更新。
- 分布式条目更新来自
Regionput和create操作(具有非null值的条目的创建被视为已经具有条目key的远程缓存的更新)。 条目更新是有选择地分发的 - 仅限于已定义条目key的高速缓存。 与您通过复制获得的推送模型相比,这提供了拉动模型。 - 仅分发不会导致从远程缓存复制新条目。
- 分布式区域跨群集共享缓存加载器和缓存编写器应用程序事件处理程序插件。
在分布式区域中,新的和更新的条目值会自动分发到已定义条目的远程缓存中。
步骤 1: 应用程序更新或创建条目。 此时,M1缓存中的条目可能尚不存在。

步骤 2: 新值自动分发给持有条目的缓存。

步骤 3: 整个群集中条目的值相同。

区域分布式选项
您可以使用包含和不包含确认的分发,或使用区域分布的全局锁定。 配置为通过确认分发的区域也可以配置为在托管该区域的所有Geode成员之间一致地解析并发更新。
每个分布式区域必须在整个群集中具有相同的范围和并发检查设置。
分布式范围分为三个级别:
distributed-no-ack. 分发操作返回时无需等待其他缓存的响应。 此范围提供最佳性能并使用最少的开销,但它也最容易出现由网络问题引起的不一致。 例如,网络传输层的临时中断可能导致在将更新分发到远程机器上的缓存时失败,同时本地缓存继续更新。
distributed-ack. 发布在继续之前等待来自其他缓存的确认。 这比
distributed-no-ack慢,但涵盖了简单的通信问题,例如临时网络中断。在存在许多
distributed-no-ack操作的系统中,distributed-ack操作可能需要很长时间才能完成。 群集具有可配置的时间,等待对任何distributed-ack消息的确认,然后向日志发送有关无响应成员可能出现的问题的警报。 无论等待多长时间,发送方都会等待以遵守分布式ack区域设置。 管理它的gemfire.properties属性是ack-wait-threshold。global. 在分发操作期间,条目和区域会在群集中自动锁定。 对区域及其条目的所有加载,创建,放置,无效和销毁操作都使用分布式锁执行。 全局范围在整个集群中实施严格一致性,但它是实现一致性的最慢机制。 除了分发操作执行的隐式锁定之外,还可以通过应用程序API显式锁定具有全局范围及其内容的区域。 这允许应用程序对区域和区域条目执行原子,多步操作。
复制和预加载的工作原理
要使用复制和预加载区域,您应该了解如何在缓存中初始化和维护其数据。
通过使用REPLICATE区域快捷方式设置之一,或通过将region属性data-policy设置为replicate,persistent-replicate或preloaded来配置复制和预加载区域。
复制和预加载区域的初始化
在区域创建时,系统使用可以找到的最完整和最新的数据集初始化预加载或复制的区域。 系统使用这些数据源按照此优先顺序初始化新区域:
- 另一个已在集群中定义的复制区域。
- 仅用于持久复制。 磁盘文件,后跟分布式缓存中区域的所有副本的并集。
- 仅适用于预加载区域。 另一个已在集群中定义的预加载区域。
- 分布式缓存中区域的所有副本的并集。

在从复制或预加载区域初始化区域时,如果源区域崩溃,则初始化将重新开始。
如果区域联合用于初始化,如图所示,并且其中一个单独的源区域在初始化期间消失(由于缓存关闭,成员崩溃或区域破坏),新区域可能包含部分数据集 来自坠毁的源区域。 发生这种情况时,不会记录任何警告或抛出异常。 新区域仍然有一整套剩余的成员区域。
初始化后复制和预加载区域的行为
初始化后,预加载区域的操作类似于具有normal和data-policy数据策略的区域,仅接收它在本地缓存中定义的条目的分布。

如果区域配置为复制区域,则它将从其他成员接收分布式区域中的所有新创建。 这是推送分发模型。 与预加载区域不同,复制区域具有一个契约,表明它将保存分布式区域中任何位置的所有条目。

配置分布式,复制和预加载区域
规划分布式,复制和预加载区域的配置和持续管理,并配置区域。
在开始之前,请了解基本配置和编程.
选择与您的区域配置最匹配的区域快捷方式设置。 请参阅 org.apache.geode.cache.RegionShortcut 或Region Shortcuts. 要创建复制区域,请使用
REPLICATE快捷方式设置之一。 要创建预加载区域,请将您的区域data-policy设置为preloaded。 这个cache.xml声明创建了一个复制区域:<region-attributes refid="REPLICATE"> </region-attributes>您还可以使用gfsh配置区域。 例如:
gfsh>create region --name=regionA --type=REPLICATE参见区域类型.
选择您所在地区的分布式级别。
RegionShortcut中分布式区域的区域快捷方式使用distributed-ack范围。 如果需要不同的范围,请将region-attributesscope设置为distributed-no-ack或global。例子:
<region-attributes refid="REPLICATE" scope="distributed-no-ack"> </region-attributes>如果您使用
distributed-ack范围,则可以选择启用该区域的并发检查。例子:
<region-attributes refid="REPLICATE" scope="distributed-ack" concurrency-checks-enabled="true"> </region-attributes>如果您正在使用
global范围,除了Geode提供的自动锁定外,还需要编程您需要的任何显式锁定。
复制区域中的本地销毁和无效
在仅影响本地缓存的所有操作中,在复制区域中仅允许本地区域销毁。 其他操作不可配置或抛出异常。 例如,您不能将本地destroy用作复制区域上的到期操作。 这是因为诸如条目失效和破坏之类的本地操作仅从本地缓存中删除数据。 如果数据在本地删除但保持不变,则复制区域将不再完整。
锁定全局区域
在全局区域中,系统在更新期间锁定条目和区域。 您还可以根据应用程序的需要显式锁定区域及其条目。 锁定包括系统设置,可帮助您优化性能并锁定成员之间的行为。
在具有全局范围的区域中,锁定有助于确保缓存一致性
区域和条目的锁定有两种方式:
Implicit(隐式). Geode在大多数操作期间自动锁定全局区域及其数据条目。 区域失效和销毁不会获取锁定。
Explicit(明确). 您可以使用API显式锁定区域及其条目。 这样做是为了保证具有多步分布式操作的任务的原子性。
Region方法org.apache.geode.cache.Region.getDistributedLock和org.apache.geode.cache.Region.getRegionDistributedLock为区域和指定的键返回java.util.concurrent.locks.Lock的实例。注意: 您必须使用
RegionAPI来锁定区域和区域条目。 不要在org.apache.geode.distributed包中使用DistributedLockService。 该服务仅适用于锁定任意分布式应用程序。 它与Region的locking方法不兼容。
锁定超时
获取区域或条目的锁定是获取实体的锁定实例然后使用实例设置锁定的两步过程。 锁定后,持有它进行操作,然后将其释放给其他人使用。 您可以设置等待获取锁定所花费的时间限制以及持有锁定所花费的时间。 隐式和显式锁定操作都受超时影响:
锁定超时限制等待获取锁定。 缓存属性
lock-timeout控制隐式锁请求。 对于显式锁定,通过调用从RegionAPI返回的java.util.concurrent.locks.Lock实例来指定等待时间。 您可以等待一段特定的时间,无论是否有锁,都可以立即返回,或者无限期地等待。<cache lock-timeout="60"> </cache>gfsh:
gfsh>alter runtime --lock-timeout=60锁定租约限制锁定在自动释放之前可以保持多长时间。 定时锁允许应用程序在成员未能在租用时间内释放获得的锁时进行恢复。 对于所有锁定,此超时使用缓存属性
lock-lease设置。<cache lock-lease="120"> </cache>gfsh:
gfsh>alter runtime --lock-lease=120
优化锁定性能
对于每个全局区域,将为已定义区域的成员之一分配锁定授予者的作业。 锁定授予者运行锁定服务,该服务接收来自系统成员的锁定请求,根据需要对它们进行排队,并按接收的顺序授予它们。
锁定授予者比其他成员略有优势,因为它是唯一一个不必发送消息来请求锁定的成员。 出于同样的原因,设保人的要求成本最低。 因此,您可以通过将锁定授予者状态分配给获取最多锁定的成员来优化区域中的锁定。 这可能是执行最多put的成员,因此需要最隐式锁,或者这可能是执行许多显式锁的成员。
锁定授予者分配如下:
- 任何具有区域定义的成员都会为其分配请求锁定授予者状态。 因此,在任何时候,发出请求的最新成员是锁定授予者。
- 如果没有成员请求区域的锁定授予者状态,或者当前锁定授予者消失,则系统从具有在其高速缓存中定义的区域的成员分配锁定授予者。
您可以申请锁定设备状态:
- 在区域创建时通过
is-lock-grantor属性。 您可以通过region方法getAttributes检索此属性,以查看您是否要求成为该区域的锁定授予者。 注意: 区域创建后,is-lock-grantor属性不会更改。 - 通过区域
becomeLockGrantor方法创建区域后。 但是,应该谨慎地更改锁定授予者,因为这样做需要从其他操作开始循环。 特别是,要小心避免创建一个成员争夺锁定授予者状态的情况。
例子
这两个示例显示了条目锁定和解锁。 注意如何获取条目的Lock对象,然后调用其锁定方法来实际设置锁。 示例程序将条目锁定信息存储在哈希表中以供将来参考。
/* Lock a data entry */
HashMap lockedItemsMap = new HashMap();
...
String entryKey = ...
if (!lockedItemsMap.containsKey(entryKey))
{
Lock lock = this.currRegion.getDistributedLock(entryKey);
lock.lock();
lockedItemsMap.put(name, lock);
}
...
/* Unlock a data entry */
String entryKey = ...
if (lockedItemsMap.containsKey(entryKey))
{
Lock lock = (Lock) lockedItemsMap.remove(name);
lock.unlock();
}
区域更新的一致性
Geode确保区域的所有副本最终在托管该区域的所有成员和客户端上达到一致状态,包括分发区域事件的Geode成员。
按地区类型检查一致性
Geode根据您配置的区域类型执行不同的一致性检查。
配置一致性检查
Geode默认启用一致性检查。 您无法禁用持久性区域的一致性检查。 对于所有其他区域,您可以通过将
cache.xml中的concurrency-checks-enabled区域属性设置为“true”或“false”来显式启用或禁用一致性检查。一致性检查的开销
一致性检查需要额外的开销来存储和分发版本和时间戳信息,以及在一段时间内维护销毁的条目以满足一致性要求。
一致性检查如何适用于复制区域
每个区域都存储用于冲突检测的版本和时间戳信息。 在应用分布式更新之前,Geode成员使用记录的信息一致地检测和解决冲突。
如何解决Destroy和Clear操作
为区域启用一致性检查时,当应用程序销毁该条目时,Geode成员不会立即从该区域中删除条目。 相反,成员将条目保留其当前版本标记一段时间,以便检测可能与已发生的操作发生冲突。 保留的条目称为墓碑。 为了提供一致性,Geode保留了分区区域和非复制区域以及复制区域的逻辑删除。
具有一致性区域的事务
修改启用了一致性检查的区域的事务会在事务提交时生成区域更新的所有必要版本信息。
按地区类型检查一致性
Geode根据您配置的区域类型执行不同的一致性检查。
分区区域的一致性
对于分区区域,Geode通过将给定key上的所有更新路由到保存该key主副本的Geode成员来维护一致性。 该成员持有对key的锁定,同时将更新分发给承载key副本的其他成员。 由于分区区域的所有更新都在主要Geode成员上序列化,因此所有成员都以相同的顺序应用更新,并始终保持一致性。 请参阅了解分区.
复制区域一致性
对于复制区域,托管该区域的任何成员都可以更新key并将该更新分发给其他成员,而无需锁定key。 两个成员可能同时更新相同的key(并发更新)。 由于网络等待时间,一个成员的更新也可能在稍后时间分配给其他成员,之后这些成员已经对key应用了更新的更新(无序更新)。 默认情况下,Geode成员在应用区域更新之前执行冲突检查,以便检测并一致地解决并发和无序更新。 冲突检查可确保区域数据最终在托管该区域的所有成员上保持一致。 复制区域的冲突检查行为总结如下:
- 如果两个成员同时更新同一个key,则冲突检查会确保所有成员最终应用相同的值,即两个并发更新之一的值。
- 如果成员收到无序更新(在应用一个或多个最新更新后收到的更新),则冲突检查可确保丢弃无序更新,而不应用于缓存。
一致性检查如何适用于复制区域 和 如何解决Destroy和Clear操作 提供有关Geode在应用更新时如何执行冲突检查的更多详细信息。
非复制区域和客户端缓存一致性
当成员收到非复制区域中的条目的更新并应用更新时,它将以与复制区域相同的方式执行冲突检查。 但是,如果成员对区域中不存在的条目启动操作,则它首先将该操作传递给承载复制的成员。 承载副本的成员生成并提供后续冲突检查所需的版本信息。 请参见一致性检查如何为复制区域工作.
客户端缓存在收到区域条目的更新时也以相同的方式执行一致性检查。 但是,首先将源自客户端缓存的所有区域操作传递到可用的Geode服务器,该服务器生成后续冲突检查所需的版本信息。
配置一致性检查
Geode默认启用一致性检查。 您无法禁用持久性区域的一致性检查。 对于所有其他区域,您可以通过将cache.xml中的concurrency-checks-enabled 区域属性设置为“true”或“false”来显式启用或禁用一致性检查。
承载区域的所有Geode成员必须对该区域使用相同的concurrency-checks-enabled设置。
即使服务器缓存启用了对同一区域的一致性检查,客户端缓存也可以禁用区域的一致性检查。 此配置可确保客户端查看该区域的所有事件,但不会阻止客户端缓存区域与服务器缓存不同步。
注意: 不启用一致性检查的区域仍然受竞争条件的影响。 并发更新可能导致一个或多个成员具有相同key的不同值。 网络延迟可能导致在发生更新后将旧更新应用于key。
一致性检查的开销
一致性检查需要额外的开销来存储和分发版本和时间戳信息,以及在一段时间内维护销毁的条目以满足一致性要求。
为了提供一致性检查,每个区域条目使用额外的16个字节。 删除条目时,会创建并维护大约13个字节的逻辑删除条目,直到逻辑删除过期或在成员中进行垃圾收集。 (当一个条目被销毁时,该成员临时保留该条目及其当前版本标记,以检测可能与已发生的操作的冲突。保留的条目称为墓碑。)参见如何解决销毁和清除操作.
如果您无法支持部署中的额外开销,则可以通过为每个区域设置concurrency-checks-enabled为“false”来禁用一致性检查。 请参阅区域更新的一致性.
一致性检查如何适用于复制区域
每个区域都存储用于冲突检测的版本和时间戳信息。 在应用分布式更新之前,Geode成员使用记录的信息一致地检测和解决冲突。
默认情况下,区域中的每个条目都存储上次更新条目的Geode成员的ID,以及每次更新发生时递增的条目的版本标记。 版本信息存储在每个本地条目中,并且在更新本地条目时将版本标记分发给其他Geode成员。
接收更新消息的Geode成员或客户端首先将更新版本标记与其本地高速缓存中记录的版本标记进行比较。 如果更新版本标记较大,则表示该条目的较新版本,因此接收成员在本地应用更新并更新版本信息。 较小的更新版本标记表示无序更新,将被丢弃。
相同的版本标记表示多个Geode成员同时更新了相同的条目。 要解决并发更新,Geode成员始终应用(或保留)具有最高成员身份ID的区域条目; 具有较低成员资格ID的区域条目被丢弃。
注意: 当Geode成员丢弃更新消息时(无论是无序更新还是解析并发更新),它都不会将丢弃的事件传递给该区域的事件侦听器。 您可以使用conflatedEvents统计信息跟踪每个成员的丢弃更新数。 参见Geode统计列表. 某些成员可能会在其他成员应用更新时丢弃更新,具体取决于每个成员收到更新的顺序。 因此,每个Geode成员的conflatedEvents统计信息都不同。 以下示例更详细地描述了此行为。
以下示例显示如何在三个Geode成员的集群中处理并发更新。 假设成员A,B和C的成员资格ID分别为1,2和3。 每个成员当前在其版本C2的缓存中存储条目X(该条目最后由成员C更新):
步骤 1: 应用程序更新Geode成员A上的条目X,同时另一个应用程序更新成员C上的条目X.每个成员递增条目的版本标记,并在其本地缓存中记录带有其成员标识的版本标记。 在这种情况下,条目最初是在C2版本,因此每个成员在其本地缓存中将版本更新为3(分别为A3和C3)。

步骤 2: 成员A将其更新消息分发给成员B和C.
成员B将更新版本标记(3)与其记录的版本标记(2)进行比较,并将更新作为版本A3应用于其本地高速缓存。 在此成员中,更新将暂时应用,并传递给已配置的事件侦听器。
成员C将更新版本标记(3)与其记录的版本标记(3)进行比较,并标识并发更新。 为解决冲突,成员C接下来将更新的成员身份ID与存储在其本地缓存中的成员身份ID进行比较。 因为更新(A3)的分布式系统ID低于存储在高速缓存(C3)中的ID,所以成员C丢弃更新(并增加conflatedEvents统计信息)。

步骤 3: 成员C将更新消息分发给成员A和B.
成员A和B将更新版本标记(3)与其记录的版本标记(3)进行比较,并识别并发更新。 为了解决冲突,两个成员都将更新的成员身份ID与存储在其本地缓存中的成员身份ID进行比较。 由于缓存值中A的分布式系统ID小于更新中的C的ID,因此两个成员都会在其本地缓存中记录更新C3,从而覆盖先前的值。
此时,托管该区域的所有成员都已成为成员A和C上的并发更新的一致状态。

如何解决Destroy和Clear操作
为区域启用一致性检查时,当应用程序销毁该条目时,Geode成员不会立即从该区域中删除条目。 相反,成员将条目保留其当前版本标记一段时间,以便检测可能与已发生的操作发生冲突。 保留的条目称为墓碑。 为了提供一致性,Geode保留了分区区域和非复制区域以及复制区域的逻辑删除。
客户端缓存或非复制区域中的逻辑删除在8分钟后到期,此时逻辑删除立即从缓存中删除。
复制或分区区域的墓碑在10分钟后到期。 过期的墓碑有资格由Geode成员进行垃圾收集。 任何类型的100,000个墓碑在本地Geode成员中超时后,将自动触发垃圾收集。 您可以选择将gemfire.tombstone-gc-threshold属性设置为小于100000的值,以更频繁地执行垃圾回收。
注意: 为了避免内存不足错误,当可用内存量低于总内存的30%时,Geode成员还会启动逻辑删除的垃圾回收。
您可以使用CachePerfStats中的tombstoneCount统计信息来监视缓存中的逻辑删除总数。 tombstoneGCCount统计信息记录成员执行的逻辑删除垃圾收集周期的总数。 replicatedTombstonesSize和nonReplicatedTombstonesSize分别显示复制或分区区域和非复制区域中墓碑当前消耗的大致字节数。 参见Geode统计列表.
关于Region.clear()操作
区域条目版本标记和逻辑删除仅在单个条目被销毁时确保一致性。 但是,Region.clear()操作一次对区域中的所有条目进行操作。 为了为Region.clear()操作提供一致性,Geode获得该区域的分布式读/写锁,该锁阻止对该区域的所有并发更新。 在清除区域之前允许在清除操作之前启动的任何更新。
具有一致性区域的事务
修改启用了一致性检查的区域的事务会在事务提交时生成区域更新的所有必要版本信息。
如果事务修改了正常区域,预加载区域或空区域,则事务首先委托给保存区域复制的Geode成员。 此行为类似于分区区域的事务行为,其中分区区域事务将转发到承载分区区域更新主节点的成员。
正常,预加载或空区域上的事务限制是,当启用一致性检查时,事务不能对该区域执行localDestroy或localInvalidate操作。 在这种情况下,Geode会抛出UnsupportedOperationInTransactionException异常。 当启用一致性检查时,应用程序应使用Destroy或Invalidate操作代替localDestroy或localInvalidate。
一般地区数据管理
对于所有区域,您可以选择控制内存使用,将数据备份到磁盘,以及从缓存中丢弃过时数据。
Persistence and Overflow(持久性和溢出)
您可以将数据保留在磁盘上以进行备份,并将其溢出到磁盘以释放内存,而无需从缓存中完全删除数据。
Eviction(驱逐)
使用逐出来控制数据区域大小。 驱逐行动由基于空间的阈值触发。
Expiration(到期)
使用到期可以保持数据最新并通过删除过时条目来减小区域大小。 到期操作由基于时间的阈值触发。
保持缓存与外部数据源同步
通过编程和安装适用于您所在地区的应用程序插件,使分布式缓存与外部数据源保持同步。
Persistence and Overflow(持久性和溢出)
您可以将数据保留在磁盘上以进行备份,并将其溢出到磁盘以释放内存,而无需从缓存中完全删除数据。
注意: 这补充了基本配置和编程中提供的管理数据区域的一般步骤.
所有磁盘存储都使用Apache Geode 磁盘存储.
持久性和溢出如何工作
要使用Geode持久性和溢出,您应该了解它们如何处理您的数据。
配置区域持久性和溢出
计划数据区域的持久性和溢出并相应地进行配置。
溢出配置示例
cache.xml示例显示了区域和服务器订阅队列溢出的配置。
持久性和溢出如何工作
要使用Geode持久性和溢出,您应该了解它们如何处理您的数据。
Geode持续存在并溢出了几种类型的数据。 您可以保留或溢出您所在地区的应用程序数据。 此外,Geode持续存在并溢出消息队列,以管理内存消耗并提供高可用性。
持久性数据比区域所在的成员更长,并且可用于在创建时初始化区域。 溢出仅作为内存中区域的扩展。
根据Geode磁盘存储的配置将数据写入磁盘。 对于任何磁盘选项,您可以指定要使用的磁盘存储的名称或使用Geode默认磁盘存储。 参见磁盘存储.
数据如何保持和溢出
对于持久性,将条目键和值复制到磁盘。 对于溢出,仅复制条目值。 其他数据(如统计信息和用户属性)仅保留在内存中。
- 数据区域通过最近最少使用(LRU)条目溢出到磁盘,因为这些条目被认为是应用程序最不感兴趣的,因此不太可能被访问。
- 服务器订阅队列溢出最近使用的(MRU)条目。 这些是位于队列末尾的消息,因此最后排队发送到客户端。
Persistence(持久化)
持久性提供区域条目数据的磁盘备份。 所有条目的键和值都保存到磁盘,就像在磁盘上具有该区域的副本一样。 区域输入操作(如put和destroy)在内存和磁盘上执行。

当成员因任何原因停止时,磁盘上的区域数据仍然存在。 在分区区域中,数据存储区在成员之间划分,这可能导致某些数据仅在磁盘上,某些数据在磁盘上和内存中。 磁盘数据可以在成员启动时使用以填充相同的区域。
Overflow(溢出)
溢出通过将最近最少使用(LRU)条目的值移动到磁盘来限制内存中的区域大小。 溢出基本上使用磁盘作为条目值的交换空间。 如果请求的条目的值仅在磁盘上,则该值将被复制回内存,可能导致将不同LRU条目的值移动到磁盘。 与持久化条目一样,溢出条目在磁盘上维护,就像它们在内存中一样。
在此图中,条目X的值已移至磁盘以在内存中腾出空间。 X的键仍然在内存中。 从分布式系统的角度来看,磁盘上的值与内存中的数据一样是区域的一部分。

持久性和溢出在一起
一起使用,持久性和溢出将所有条目键和值保留在磁盘上,并且只保留内存中最活跃的条目值。 由于溢出而从内存中删除条目值对磁盘副本没有影响,因为所有条目都已在磁盘上。

持久性和多站点配置
多站点网关发送方队列溢出最近使用的(MRU)条目。 这些是队列末尾的消息,因此最后排队发送到远程站点。 您还可以配置网关发件人队列以保持高可用性。
配置区域持久性和溢出
计划数据区域的持久性和溢出并相应地进行配置。
使用以下步骤为持久性和溢出配置数据区域:
根据需要配置磁盘存储。 请参阅设计和配置磁盘存储。 缓存磁盘存储区定义数据写入磁盘的位置和方式。
<disk-store name="myPersistentStore" . . . > <disk-store name="myOverflowStore" . . . >指定区域的持久性和溢出条件。 如果未使用默认磁盘存储,请在区域属性配置中提供磁盘存储名称。 要异步写入磁盘,请指定
disk-synchronous=“false”。对于溢出,请在区域的'eviction-attributes`中指定溢出条件,并命名要使用的磁盘存储。
例子:
<region name="overflowRegion" . . . > <region-attributes disk-store-name="myOverflowStore" disk-synchronous="true"> <eviction-attributes> <!-- Overflow to disk when 100 megabytes of data reside in the region --> <lru-memory-size maximum="100" action="overflow-to-disk"/> </eviction-attributes> </region-attributes> </region>gfsh:
你不能使用gfsh配置
lru-memory-size。对于持久性,将
data-policy设置为persistent-replicate并命名要使用的磁盘存储。例子:
<region name="partitioned_region" refid="PARTITION_PERSISTENT"> <region-attributes disk-store-name="myPersistentStore"> . . . </region-attributes> </region>
启动成员时,将使用磁盘存储和磁盘写入行为自动执行溢出和持久性。
注意: 您还可以使用gfsh命令行界面配置区域和磁盘存储。 参见地区命令 和 磁盘存储命令.
| 相关话题 |
|---|
org.apache.geode.cache.RegionAttributes 用于数据区域持久性信息 |
org.apache.geode.cache.EvictionAttributes 用于数据区域溢出信息 |
org.apache.geode.cache.server.ClientSubscriptionConfig |
溢出配置示例
cache.xml示例显示了区域和服务器订阅队列溢出的配置。
根据以下因素之一配置溢出条件:
- 条目计数
- 绝对内存消耗
- 内存消耗占应用程序堆的百分比(不适用于服务器订阅队列)
区域溢出配置:
<!-- Overflow when the region goes over 10000 entries -->
<region-attributes>
<eviction-attributes>
<lru-entry-count maximum="10000" action="overflow-to-disk"/>
</eviction-attributes>
</region-attributes>
服务器客户端订阅队列溢出的配置:
<!-- Overflow the server's subscription queues when the queues reach 1 Mb of memory -->
<cache>
<cache-server>
<client-subscription eviction-policy="mem" capacity="1"/>
</cache-server>
</cache>
Eviction(逐出)
使用逐出来控制数据区域大小。 驱逐行动由基于空间的阈值触发。
逐出如何运作
逐出设置会导致Apache Geode通过删除最近最少使用(LRU)条目来为新条目腾出空间,从而使区域的资源在指定级别下保持使用。
配置数据逐出
配置区域的'eviction-attributes`设置以使您的区域保持在指定的限制内。
驱逐如何运作
驱逐通过删除最近最少使用(LRU)条目来为新条目让路,从而使区域的资源在指定级别下保持使用。 您可以选择过期的条目是溢出到磁盘还是已销毁。 参见持久性和溢出.
当超过基于大小的阈值时触发驱逐。 区域的逐出阈值可以基于:
- 条目计数
- 绝对内存使用量
- 可用堆的百分比
这些驱逐算法是互斥的; 只有一个可以对给定区域有效。
当Geode确定添加或更新条目会使区域超过指定级别时,它会溢出或删除足够的旧条目以腾出空间。 对于条目计数驱逐,这意味着较新条目的一对一交易。 对于内存设置,需要删除以创建空间的旧条目数取决于较旧和较新条目的大小。
为了提高效率,移除物品的选择不是严格的LRU,而是从该地区最古老的条目中选择驱逐候选者。 因此,逐出可能会在本地数据存储中留下该区域的旧条目。
驱逐行动
Apache Geode提供以下驱逐操作:
- 当地销毁 - 从本地缓存中删除条目,但不将删除操作分发给远程成员。 此操作可以应用于分区区域中的条目,但如果启用了冗余(冗余副本> 0),则不建议这样做,因为它会引入冗余存储区之间的不一致。 当应用于复制区域中的条目时,Geode会将区域类型静默更改为
预加载以适应本地修改。 - 溢出到磁盘 - 条目的值溢出到磁盘并在内存中设置为null。 条目的key保留在缓存中。 这是分区区域唯一完全支持的驱逐操作。
分区中的驱逐
在分区区域中,Geode会删除正在执行新条目操作的存储桶中可找到的最旧条目。 Geode在逐桶的基础上维护LRU条目信息,因为跨分区区域维护信息的成本会降低系统的性能。
- 对于存储器和入口计数驱逐,LRU驱逐在正在执行新的条目操作的桶中完成,直到成员中的组合桶的总体大小已经下降到足以执行操作而不超过限制。
- 对于堆驱逐,每个分区区域桶被视为它是一个单独的区域,每个驱逐操作仅考虑桶的LRU,而不是整个分区区域。
配置数据驱逐
配置区域的'eviction-attributes`设置以使您的区域保持在指定的限制内。
配置数据驱逐如下。 您无需按所示顺序执行这些步骤。
- 决定是否根据以下方式逐出:
- 条目计数(如果您的条目大小相对均匀,则非常有用)。
- 使用的总字节数。 在分区区域中,使用
local-max-memory设置。 在非分区区域中,它在eviction-attributes中设置。 - 使用的应用程序堆的百分比。 这使用Geode资源管理器。 当管理器确定需要驱逐时,管理器命令驱逐控制器开始从驱逐算法设置为
lru-heap-percentage的所有区域驱逐。 驱逐出去,直到管理器停止。 Geode驱逐该成员为该地区托管的最近最少使用的条目。 请参阅管理堆和堆外内存.
- 确定达到限制时要采取的操作:
- 在本地销毁该条目。
- 将条目数据溢出到磁盘。 参见持久性和溢出.
- 确定成员中允许的最大数据量,用于指示的驱逐测量。 这是成员中区域的所有存储的最大值。 对于分区区域,这是存储在区域成员中的所有存储区的总数,包括用于冗余的任何辅助存储区。
- 决定是否为您所在的地区编制自定义sizer。 如果您能够提供这样的类,它可能比Geode完成的标准大小更快。 您的自定义类必须遵循定义自定义类的准则,另外,必须实现
org.apache.geode.cache.util.ObjectSizer。 请参见在数据缓存中使用自定义类的要求.
例子:
设置LRU内存驱逐阈值为1000 MB。 使用自定义类来测量区域中每个对象的大小:
gfsh>create region --name=myRegion --type=REPLICATE --eviction-max-memory=1000 \
--eviction-action=overflow-to-disk --eviction-object-sizer=com.myLib.MySizer
在分区区域上创建逐出阈值,最大条目数为512:
gfsh>create region --name=myRegion --type=PARTITION --eviction-entry-count=512 \
--eviction-action=overflow-to-disk
要为堆LRU驱逐配置分区区域,首先在服务器启动时配置资源管理器,然后创建启用了驱逐的区域:
gfsh>start server --name=Server1 --eviction-heap-percentage=80
...
gfsh>create region --name=myRegion --type=PARTITION --eviction-action=overflow-to-disk
Expiration(到期)
使用到期可以保持数据最新并通过删除过时条目来减小区域大小。 到期操作由基于时间的阈值触发。
过期如何运作
到期删除您未使用的旧条目和条目。 您可以选择是否使过期的条目失效或销毁。
配置数据过期
配置到期类型和要使用的到期操作。
过期如何运作
到期通过删除您未使用的旧条目和条目来保持区域数据的新鲜。 您可以选择是否使过期的条目失效或销毁。
分布式区域中的过期活动可以是分布式的或本地的。 因此,一个高速缓存可以控制系统中的多个高速缓存的到期。
此图显示了客户端/服务器系统的两个基本过期设置。 服务器(右侧)从数据库填充区域,数据自动分布在整个系统中。 数据仅在一小时内有效,因此服务器对一小时的条目执行分布式销毁。 客户端应用程序是消费者。 客户端通过删除没有本地利益的条目的本地副本(空闲时间到期)来释放其缓存中的空间。 对客户端已过期的条目的请求将转发到服务器。
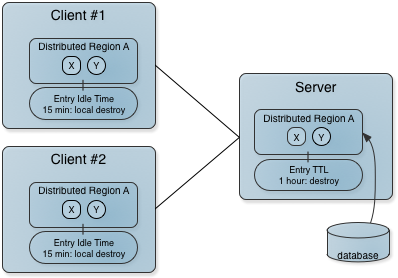
到期类型
Apache Geode提供两种类型的到期,每种类型都由基于时间的阈值触发。 这些可以共存; 它们不是相互排斥的。
- Time to live (TTL). 在上次创建或更新后,对象可能保留在缓存中的时间量(以秒为单位)。 对于条目,对于创建和放置操作,计数器设置为零。 创建区域时以及当条目的计数器重置时,区域计数器将复位。 TTL到期属性是
region-time-to-live和entry-time-to-live。 - Idle timeout. 在上次访问后,对象可能保留在缓存中的时间量(以秒为单位)。 只要TTL计数器复位,对象的空闲超时计数器就会复位。 此外,只要通过get操作或netSearch访问条目,就会重置条目的空闲超时计数器。 只要为其中一个条目重置空闲超时,就会重置区域的空闲超时计数器。 空闲超时到期属性是:
region-idle-time和entry-idle-time。
到期行动
Apache Geode提供以下过期操作:
- invalidate (default) - 数据项的值将被删除,但key仍保留在缓存中。 适用于复制数据项的所有分布式成员。
- destroy - 数据项的键和值都被删除。 适用于复制数据项的所有分布式成员。
- local invalidate - 删除数据项的值。 仅适用于本地成员。
- local destroy - 删除数据项的键和值。 仅适用于本地成员。
您不能在复制或分区区域中使用local-destroy或local-invalidate到期操作。 您只能在分布式区域上使用本地选项,其数据策略为空,正常或预加载。
复制区域和分区区域中的条目到期
在复制区域中,条目更新在最方便可用的数据副本中执行,然后复制到其他成员,同时重置其上次更新的统计信息。 在分区区域中,始终在主副本中完成条目更新,重置主副本的上次更新和最后访问的统计信息,然后更新辅助副本以匹配。
在复制区域和分区区域中,条目检索使用最方便的可用数据副本,其可以是任何分布式副本。 检索不会传播给其他成员。 当数据项被考虑到期时,将协调上次访问时间的差异。
如果自上次更新或读取访问后经过的时间超过建立的阈值,则可以在复制区域的任何副本中触发到期。 分区区域中的到期在主副本中执行,基于主要的上次访问和最后更新的统计信息。 在这两种情况下,到期机制都会检查数据项的所有副本的最后访问日期,并将所有副本的最后访问日期更新为最近的最后访问日期。 然后,如果经过的时间仍然使数据项超过到期阈值,则根据为该区域指定的到期动作删除该项。
到期设置和netSearch之间的交互
在netSearch从远程缓存中检索条目值之前,它根据local区域的到期设置验证remote条目的统计信息。 已经过期的本地缓存中的条目将被传递。 验证后,该条目将进入本地缓存,并为本地副本更新本地访问和更新统计信息。 重置最后访问的时间,并将最后修改的时间更新为远程高速缓存中的时间,并对系统时钟差异进行更正。 因此,为本地条目分配了在集群中修改条目的真实最后时间。 netSearch操作对远程缓存中的到期计数器没有影响。
netSearch方法仅在分布式区域上运行,其数据策略为空,正常和预加载。
配置数据过期
配置到期类型和要使用的到期操作。
- 到期操作需要将
statistics-enabled的region属性设置为true。 这可以在cache.xml文件的region元素,gfsh命令行或通过API完成。 - 使用到期类型设置到期属性,包括最大时间和到期操作。 查看区域属性列表中的
entry-time-to-live,entry-idle-time,region-time-to-live和region-idle-time在 .
用于到期的统计信息可通过Region和Region.Entry getStatistics方法返回的CacheStatistics对象直接提供给应用程序。 CacheStatistics对象还提供了重置统计计数器的方法。
对于分区区域:
- 在分区区域上,仅对区域的条目支持到期,而不支持区域本身。 区域范围的到期属性,例如
region-time-to-live和region-idle-time不适用于分区区域中的数据项。 - 要在使用分区区域时确保可靠的读取行为,请使用
entry-time-to-live属性,而不是entry-idle-time属性。 - 您不能在分区区域中使用
local-destroy或local-invalidate到期操作。
复制区域示例:
// Setting standard expiration on an entry
<region-attributes statistics-enabled="true">
<entry-idle-time>
<expiration-attributes timeout="60" action="local-invalidate"/>
</entry-idle-time>
</region-attributes>
如果应用程序需要,请覆盖特定条目的区域范围设置。 去做这个:
编写实现
org.apache.geode.cache.CustomExpiry的自定义过期类。 例如:// Custom expiration class // Use the key for a region entry to set entry-specific expiration timeouts of // 10 seconds for even-numbered keys with a DESTROY action on the expired entries // Leave the default region setting for all odd-numbered keys. public class MyClass implements CustomExpiry, Declarable { private static final ExpirationAttributes CUSTOM_EXPIRY = new ExpirationAttributes(10, ExpirationAction.DESTROY); public ExpirationAttributes getExpiry(Entry entry) { int key = (Integer)entry.getKey(); return key % 2 == 0 ? CUSTOM_EXPIRY : null; } }在区域的到期属性设置中定义类。 例如:
<!-- Set default entry idle timeout expiration for the region --> <!-- Pass entries to custom expiry class for expiration overrides --> <region-attributes statistics-enabled="true"> <entry-idle-time> <expiration-attributes timeout="60"> <custom-expiry> <class-name>com.company.mypackage.MyClass</class-name> </custom-expiry> </expiration-attributes> </entry-idle-time> </region-attributes>
上述XML的gfsh等价物是:
gfsh> create region --name=region1 --type=REPLICATE --enable-statistics \ --entry-idle-time-expiration=60 --entry-idle-time-custom-expiry=com.company.mypackage.MyClass当主要过期条目时,它会从辅助节点请求最后访问的统计信息。 如果有必要,主要采用最近的访问时间并重新安排到期时间。 这仅针对分布式到期操作执行,并且适用于分区和复制区域。
您还可以使用gfsh命令行界面配置区域。 参见区域命令.
配置到期的线程数
您可以使用gemfire.EXPIRY_THREADS系统属性来增加处理到期的线程数。 默认情况下,一个线程处理到期,当条目到期的速度超过线程可以使它们到期时,线程可能会变得过载。 如果单个线程处理过多的过期,则可能导致OOME。 启动缓存服务器时,将gemfire.EXPIRY_THREADS系统属性设置为所需的数字。
保持缓存与外部数据源同步
通过编程和安装适用于您所在地区的应用程序插件,使分布式缓存与外部数据源保持同步。
外部数据源概述
Apache Geode具有应用程序插件,可将数据读入缓存并将其写出。
使用JNDI配置数据库连接.
使用JNDI维护包含外部数据源的连接池。
数据加载器的工作原理
默认情况下,区域没有定义数据加载器。 通过在托管区域数据的成员上设置region属性cache-loader,将应用程序定义的加载程序插入任何区域。
实现数据加载器
编程数据加载器并配置您的区域以使用它。
外部数据源概述
Apache Geode具有应用程序插件,可将数据读入缓存并将其写出。
应用程序插件:
使用
org.apache.geode.cache.CacheLoader的实现加载有关缓存未命中的数据。 当get操作无法在缓存中找到值时,将调用CacheLoader.load方法。 从加载器返回的值被放入缓存并返回到getoperation。 您可以将此与数据到期结合使用以清除旧数据和其他数据加载应用程序,这些应用程序可能由外部数据源中的事件提示。 请参阅配置数据过期.使用缓存事件处理程序
CacheWriter和CacheListener将数据写入数据源。 有关实现的详细信息,请参阅实现缓存事件处理程序.实现缓存事件处理程序
CacheWriter同步运行。 在对区域条目执行任何操作之前,如果为群集中的区域定义了任何缓存编写器,则系统将调用最方便的编写器。 在分区和分布式区域中,缓存编写器通常仅在包含该区域的高速缓存的子集中定义 - 通常仅在一个高速缓存中。 缓存写入器可以中止区域输入操作。CacheListener在更新缓存后同步运行。 此侦听器仅适用于本地缓存事件,因此请将侦听器安装在您希望它处理事件的每个缓存中。 您可以在任何缓存中安装多个缓存侦听器。
除了使用应用程序插件外,还可以在cache.xml中配置外部JNDI数据库源,并在事务中使用这些数据源。 有关详细信息,请参阅使用JNDI配置数据库连接。
使用JNDI配置数据库连接
要连接到外部数据库,例如在使用JTA事务时,可以在cache.xml中配置数据库JNDI数据源。 DataSource对象指向JDBC连接,或者更常见的是JDBC连接池。 连接池通常是首选,因为程序可以根据需要使用和重用连接,然后释放它以供另一个线程使用。
以下列表显示了JTA事务中使用的DataSource连接类型:
- XAPooledDataSource. XA池化SQL连接。
- ManagedDataSource. J2EE连接器体系结构(JCA)ManagedConnectionFactory的JNDI绑定类型。
- PooledDataSource. 池化SQL连接。
- SimpleDataSource. 单个SQL连接。 没有完成SQL连接池。 连接是动态生成的,无法重复使用。
jndi-binding元素的jndi-name属性是键绑定参数。 如果jndi-name的值是DataSource,则它被绑定为java:/myDatabase**,其中myDatabase*是您为数据源指定的名称。 如果数据源无法在运行时绑定到JNDI,则Geode会记录警告。 有关DataSource接口的信息,请参阅: http://docs.oracle.com/javase/8/docs/api/javax/sql/DataSource.html
Geode支持JDBC 2.0和3.0。
注意: 在CLASSPATH中包含任何数据源JAR文件。
cache.xml中的示例DataSource配置
以下部分显示为每个DataSource连接类型配置的示例cache.xml文件。
XAPooledDataSource cache.xml示例(Derby)
该示例显示了为连接到数据资源newDB的XAPooledDataSource连接池配置的cache.xml文件。
登录和阻止超时设置低于默认值。 连接信息,包括user-name和password,在cache.xml文件中设置,而不是等到连接时间。 密码未加密。
在为支持XA事务的JCA实现的数据库驱动程序指定配置属性时(换句话说,XAPooledDataSource),必须使用配置属性来定义数据源连接,而不是connection-url元素的<jndi-binding>属性。 配置属性因数据库供应商而异。 通过config-property标记指定JNDI绑定属性,如本例所示。 您可以根据需要添加尽可能多的config-property标签。
<?xml version="1.0" encoding="UTF-8"?>
<cache
xmlns="http://geode.apache.org/schema/cache"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://geode.apache.org/schema/cache http://geode.apache.org/schema/cache/cache-1.0.xsd"
version="1.0"
lock-lease="120" lock-timeout="60" search-timeout="300">
<region name="root">
<region-attributes scope="distributed-no-ack" data-policy="cached" initial-capacity="16"
load-factor="0.75" concurrency-level="16" statistics-enabled="true">
. . .
</region>
<jndi-bindings>
<jndi-binding type="XAPooledDataSource"
jndi-name="newDB2trans"
init-pool-size="20"
max-pool-size="100"
idle-timeout-seconds="20"
blocking-timeout-seconds="5"
login-timeout-seconds="10"
xa-datasource-class="org.apache.derby.jdbc.EmbeddedXADataSource"
user-name="mitul"
password="thecleartextpassword">
<config-property>
<config-property-name>Description</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>pooled_transact</config-property-value>
</config-property>
<config-property>
<config-property-name>DatabaseName</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>newDB</config-property-value>
</config-property>
<config-property>
<config-property-name>CreateDatabase</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>create</config-property-value>
</config-property>
. . .
</jndi-binding>
</jndi-bindings>
</cache>
不同XAPooledDataSource连接的JNDI绑定配置属性
以下是不同数据库的一些示例数据源配置。 有关其他详细信息,请参阅供应商数据库的文档。
MySQL
...
<jndi-bindings>
<jndi-binding type="XAPooledDataSource"
...
xa-datasource-class="com.mysql.jdbc.jdbc2.optional.MysqlXADataSource">
<config-property>
<config-property-name>URL</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>"jdbc:mysql://mysql-servername:3306/databasename"</config-property-value>
</config-property>
...
</jndi-binding>
...
</jndi-bindings>
PostgreSQL
...
<jndi-bindings>
<jndi-binding type="XAPooledDataSource"
...
xa-datasource-class="org.postgresql.xa.PGXADataSource">
<config-property>
<config-property-name>ServerName</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>postgresql-hostname</config-property-value>
</config-property>
<config-property>
<config-property-name>DatabaseName</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>postgresqldbname</config-property-value>
</config-property>
...
</jndi-binding>
...
</jndi-bindings>
Oracle
...
<jndi-bindings>
<jndi-binding type="XAPooledDataSource"
...
xa-datasource-class="oracle.jdbc.xa.client.OracleXADataSource">
<config-property>
<config-property-name>URL</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>jdbc:oracle:oci8:@tc</config-property-value>
</config-property>
...
</jndi-binding>
...
</jndi-bindings>
Microsoft SQL Server
...
<jndi-bindings>
<jndi-binding type="XAPooledDataSource"
...
xa-datasource-class="com.microsoft.sqlserver.jdbc.SQLServerXADataSource">
<config-property>
<config-property-name>ServerName</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>mysqlserver</config-property-value>
</config-property>
<config-property>
<config-property-name>DatabaseName</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>databasename</config-property-value>
</config-property>
<config-property>
<config-property-name>SelectMethod</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>cursor</config-property-value>
</config-property>
...
</jndi-binding>
...
</jndi-bindings>
ManagedDataSource连接示例(Derby)
JCA的ManagedConnectionFactory的ManagedDataSource连接的配置如示例所示。 这种配置类似于XAPooledDataSource连接,除了类型是ManagedDataSource,你指定managed-conn-factory-class而不是xa-datasource-class。
<?xml version="1.0"?>
<cache xmlns="http://geode.apache.org/schema/cache"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://geode.apache.org/schema/cache http://geode.apache.org/schema/cache/cache-1.0.xsd"
version="1.0"
lock-lease="120"
lock-timeout="60"
search-timeout="300">
<region name="root">
<region-attributes scope="distributed-no-ack" data-policy="cached" initial-capacity="16"
load-factor="0.75" concurrency-level="16" statistics-enabled="true">
. . .
</region>
<jndi-bindings>
<jndi-binding type="ManagedDataSource"
jndi-name="DB3managed"
init-pool-size="20"
max-pool-size="100"
idle-timeout-seconds="20"
blocking-timeout-seconds="5"
login-timeout-seconds="10"
managed-conn-factory-class="com.myvendor.connection.ConnFactory"
user-name="mitul"
password="thecleartextpassword">
<config-property>
<config-property-name>Description</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>pooled_transact</config-property-value>
</config-property>
<config-property>
<config-property-name>DatabaseName</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>newDB</config-property-value>
</config-property>
<config-property>
<config-property-name>CreateDatabase</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>create</config-property-value>
</config-property>
. . .
</jndi-binding>
</jndi-bindings>
</cache>
PooledDataSource示例(Derby)
对于在任何事务之外执行的操作,使用PooledDataSource和SimpleDataSource连接。 此示例显示了一个cache.xml文件,该文件是为数据资源newDB的PooledDataSource连接池配置的。 对于此非事务性连接池,登录和阻止超时设置为高于前两个示例中的事务连接池。 连接信息,包括user-name和password,在cache.xml文件中设置,而不是等到连接时间。 密码未加密。
<?xml version="1.0"?>
<cache xmlns="http://geode.apache.org/schema/cache"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://geode.apache.org/schema/cache http://geode.apache.org/schema/cache/cache-1.0.xsd"
version="1.0"
lock-lease="120"
lock-timeout="60"
search-timeout="300">
<region name="root">
<region-attributes scope="distributed-no-ack" data-policy="cached"
initial-capacity="16" load-factor="0.75" concurrency-level="16" statistics-enabled="true">
. . .
</region>
<jndi-bindings>
<jndi-binding
type="PooledDataSource"
jndi-name="newDB1"
init-pool-size="2"
max-pool-size="7"
idle-timeout-seconds="20"
blocking-timeout-seconds="20"
login-timeout-seconds="30"
conn-pooled-datasource-class="org.apache.derby.jdbc.EmbeddedConnectionPoolDataSource"
user-name="mitul"
password="thecleartextpassword">
<config-property>
<config-property-name>Description</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>pooled_transact</config-property-value>
</config-property>
<config-property>
<config-property-name>DatabaseName</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>newDB</config-property-value>
</config-property>
<config-property>
<config-property-name>CreateDatabase</config-property-name>
<config-property-type>java.lang.String</config-property-type>
<config-property-value>create</config-property-value>
</config-property>
. . .
</jndi-binding>
</jndi-bindings>
</cache>
SimpleDataSource连接示例(Derby)
下面的示例显示cache.xml文件中的一个非常基本的配置,用于与数据资源oldDB的SimpleDataSource连接。 您只需要为此连接池配置一些属性,如jndi-name,oldDB1和databaseName,oldDB。 此密码为明文。
简单的数据源连接通常不需要特定于供应商的属性设置。 如果需要,请添加config-property标签,如前面的示例所示。
<?xml version="1.0"?>
<cache xmlns="http://geode.apache.org/schema/cache"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://geode.apache.org/schema/cache http://geode.apache.org/schema/cache/cache-1.0.xsd"
version="1.0"
lock-lease="120"
lock-timeout="60"
search-timeout="300">
<region name="root">
<region-attributes scope="distributed-no-ack" data-policy="cached" initial-capacity="16"
load-factor="0.75" concurrency-level="16" statistics-enabled="true">
. . .
</region-attributes>
</region>
<jndi-bindings>
<jndi-binding type="SimpleDataSource"
jndi-name="oldDB1"
jdbc-driver-class="org.apache.derby.jdbc.EmbeddedDriver"
user-name="mitul"
password="thecleartextpassword"
connection-url="jdbc:derby:newDB;create=true">
. . .
</jndi-binding>
</jndi-bindings>
</cache>
数据加载器的工作原理
默认情况下,区域没有定义数据加载器。 通过在托管区域数据的成员上设置region属性cache-loader,将应用程序定义的加载程序插入任何区域。
在get操作期间,加载器在高速缓存未命中时被调用,除了将值返回给调用线程之外,它还使用新的条目值填充高速缓存。
可以将加载程序配置为从外部数据存储将数据加载到Geode缓存中。 要执行反向操作,将数据从Geode缓存写入外部数据存储,请使用缓存编写器事件处理程序。 请参见实现缓存事件处理程序.
如何安装缓存加载器取决于区域的类型。
分区区域中的数据加载
由于它们可以处理大量数据,因此分区区域支持分区加载。 每个缓存加载器仅加载定义加载器的成员中的数据条目。 如果配置了数据冗余,则仅在成员拥有主副本时才加载数据。 因此,您必须在分区属性local-max-memory不为零的每个成员中安装缓存加载器。
如果依赖于JDBC连接,则每个数据存储都必须与数据源建立连接,如下图所示。 这三个成员需要三个连接。 有关如何配置数据源的信息,请参阅使用JNDI配置数据库连接。
注意: 分区区域通常需要比分布式区域更多的JDBC连接。

分布式区域中的数据加载
在非分区的分布式区域中,一个成员中定义的缓存加载器可供所有已定义区域的成员使用。 加载器通常仅定义在包含该区域的高速缓存的子集中。 当需要加载器时,将调用该区域的所有可用加载器,从最方便的加载器开始,直到加载数据或尝试所有加载器。
在下图中,一个群集的这些成员可以在不同的计算机上运行。 从M1执行对分布区域的加载。

本地区域的数据加载
对于本地区域,缓存加载器仅在定义它的成员中可用。 如果定义了加载程序,则只要在本地缓存中找不到值,就会调用它。
实现数据加载器
要使用数据加载器:
- 实现
org.apache.geode.cache.CacheLoader接口。 - 配置和部署实施。
实现CacheLoader接口
对于get操作,如果键不在缓存中,则为get操作提供服务的线程将调用CacheLoader.load方法。 实现load以返回键的值,除了返回给调用者之外,它还将被放入该区域。
org.apache.geode.cache.CacheLoader继承自Declarable,因此如果你的CacheLoader实现需要用一些参数初始化,那么实现Declarable.initialize方法。 在cache.xml文件或gfshcreate region或alter region命令中指定所需的参数。 不要定义Declarable.init()方法; 它已被弃用。
这是一个示例实现:
public class SimpleCacheLoader implements CacheLoader {
public Object load(LoaderHelper helper) {
String key = (String) helper.getKey();
// Return an entry value created from the key, assuming that
// all keys are of the form "key1", "key2", "keyN"
return "LoadedValue" + key.substring(3);
}
}
如果需要从实现中运行Region API调用,则为它们生成单独的线程。 不要从load方法直接调用Region方法,因为它可能导致缓存加载器阻塞,从而损害集群的性能。
配置和部署
使用以下三种方法之一配置和部署缓存加载器:
选项 1: 如果通过定义cache.xml文件来配置集群,则在启动服务器时通过将缓存加载器添加到类路径来进行部署。
这是cache.xml文件中的一个示例配置,它指定不带参数的加载器:
<region-attributes>
<cache-loader>
<class-name>myLoader</class-name>
</cache-loader>
</region-attributes>
或者,这是cache.xml文件中的一个示例配置,它指定带有参数的加载器:
<cache-loader>
<class-name>com.company.data.DatabaseLoader</class-name>
<parameter name="URL">
<string>jdbc:cloudscape:rmi:MyData</string>
</parameter>
</cache-loader>
要部署JAR文件,请在启动服务器时将缓存加载器JAR文件添加到类路径中。 例如:
gfsh>start server --name=s2 --classpath=/var/data/lib/myLoader.jar
选项 2: 如果在服务器启动时部署JAR文件,请将JAR文件添加到类路径并使用gfsh将配置应用于该区域。
要部署JAR文件,请在启动服务器时将缓存加载器JAR文件添加到类路径中。 例如:
gfsh>start server --name=s2 --classpath=/var/data/lib/myLoader.jar
使用gfsh将CacheLoader实现的配置应用于具有gfsh create region或gfsh alter region的区域。 以下是不带参数的区域创建示例:
gfsh>create region --name=r3 --cache-loader=com.example.appname.myCacheLoader
以下是使用参数创建区域的示例:
gfsh>create region --name=r3 \
--cache-loader=com.example.appname.myCacheLoader{'URL':'jdbc:cloudscape:rmi:MyData'}
以下是更改区域的示例:
gfsh>alter region --name=r3 --cache-loader=com.example.appname.myCacheLoader
选项 3 适用于分区区域: 如果在启动服务器后使用gfsh deploy命令部署JAR文件,请使用gfsh将配置应用于该区域。
创建服务器后,使用gfsh将JAR文件部署到所有服务器。 例如:
gfsh>deploy --jars=/var/data/lib/myLoader.jar
当服务器托管复制区域时,我们通常不使用gfsh deploy命令,详见数据加载器如何工作.
使用gfsh将CacheLoader实现的配置应用于具有gfsh create region或gfsh alter region的区域。 以下是不带参数的区域创建示例:
gfsh>create region --name=r3 --cache-loader=com.example.appname.myCacheLoader
以下是使用参数创建区域的示例:
gfsh>create region --name=r3 \
--cache-loader=com.example.appname.myCacheLoader{'URL':'jdbc:cloudscape:rmi:MyData'}
以下是更改区域的示例:
gfsh>alter region --name=r3 --cache-loader=com.example.appname.myCacheLoader
使用缓存加载器实现服务器或对等
具有嵌入式缓存的服务器和对等体可以仅在有意义的成员中配置缓存加载器。 例如,设计可以将从数据库加载的作业分配给由更多成员托管的区域的一个或两个成员。 当外部源是数据库时,可以这样做以减少连接数。
实现org.apache.geode.cache.CacheLoader接口。 区域创建配置缓存加载器,如下例所示:
RegionFactory<String,Object> rf = cache.createRegionFactory(REPLICATE);
rf.setCacheLoader(new QuoteLoader());
quotes = rf.create("NASDAQ-Quotes");
数据序列化
您在Geode中管理的数据必须序列化和反序列化,以便在进程之间进行存储和传输。 您可以选择多个数据序列化选项。
数据序列化概述
Geode提供除Java序列化之外的序列化选项,为数据存储,传输和语言类型提供更高的性能和更大的灵活性。
Geode PDX 序列化
Geode的便携式数据交换(PDX)是一种跨语言数据格式,可以降低分发和序列化对象的成本。 PDX将数据存储在您可以单独访问的命名字段中,以避免反序列化整个数据对象的成本。 PDX还允许您混合已添加或删除字段的对象版本。
Geode 数据序列化 (DataSerializable and DataSerializer)
Geode的
DataSerializable接口为您提供了对象的快速序列化。标准的 Java 序列化
您可以对仅在Java应用程序之间分发的数据使用标准Java序列化。 如果在非Java客户端和Java服务器之间分发数据,则需要执行其他编程以获取各种类格式之间的数据。
数据序列化概述
Geode提供除Java序列化之外的序列化选项,为数据存储,传输和语言类型提供更高的性能和更大的灵活性。
Geode移出本地缓存的所有数据都必须是可序列化的。 但是,您不一定需要实现java.io.Serializable,因为Geode中提供了其他序列化选项。 必须可序列化的区域数据属于以下类别:
- 分区区域
- 分布式区域
- 持久存储或溢出到磁盘的区域
- 客户端/服务器安装中的服务器或客户端区域
- 配置了网关发件人的区域,用于在多站点安装中分发事件
- 从远程缓存接收事件的区域
- 提供函数参数和结果的区域
注意: 如果使用HTTP会话管理模块存储对象,则这些对象必须是可序列化的,因为它们在被序列化之前 存储在该地区。
为了最大限度地降低序列化和反序列化的成本,Geode尽可能避免更改数据格式。 这意味着您的数据可能以序列化或反序列化的形式存储在缓存中,具体取决于您使用它的方式。 例如,如果服务器仅充当客户端之间数据分发的存储位置,则将数据保留为序列化形式,准备传输给请求它的客户端是有意义的。 分区区域数据最初始终以序列化形式存储。
数据序列化选项
使用Geode,您可以选择自动序列化域对象或使用Geode的一个接口实现序列化。 启用自动序列化意味着域对象被序列化和反序列化,而无需对这些对象进行任何代码更改。 这种自动序列化是通过使用名为ReflectionBasedAutoSerializer的自定义PdxSerializer注册域对象来执行的,该自定义PdxSerializer使用Java反射来推断要序列化的字段。
如果autoserialization不能满足您的需求,您可以通过实现Geode接口之一,PdxSerializable或DataSerializable来序列化您的对象。 您可以使用这些接口替换任何标准Java数据序列化以获得更好的性能。 如果你不能或不想修改你的域类,每个接口都有一个备用的序列化器类,PdxSerializer和DataSerializer。 要使用这些,请创建自定义序列化程序类,然后将其与Geode缓存配置中的域类相关联。
Geode数据序列化比PDX序列化快约25%,但使用PDX序列化将帮助您避免执行反序列化的更高成本。
| 性能 | Geode Data Serializable | Geode PDX Serializable |
|---|---|---|
| Implements Java Serializable. | X | |
| 处理多个版本的应用程序域对象,通过添加或减少字段来提供不同的版本. | X | |
| 提供序列化数据的单字段访问,无需完全反序列化 - 也支持OQL查询. | X | |
| Geode自动移植到其他语言 | X | |
| Works with .NET clients. | X | X |
| Works with C++ clients. | X | X |
| Works with Geode delta propagation. | X | X (See note below.) |
表 1. 序列化选项:功能比较
注意: 默认情况下,您可以将Geode delta传播与PDX序列化一起使用。 但是,如果已将Geode属性read-serialized设置为“true”,则delta传播将不起作用。 在反序列化方面,要应用更改增量传播,需要域类实例和fromDelta方法。 如果你将read-serialized设置为true,那么你将收到一个PdxInstance而不是一个域类实例,而PdxInstance没有delta传播所需的fromDelta方法。
Geode序列化(PDX或数据可序列化)和Java序列化之间的差异
Geode序列化(PDX序列化或数据序列化)不支持循环对象图,而Java序列化则支持循环对象图。 在Geode序列化中,如果在对象图中多次引用同一对象,则为每个引用序列化对象,并且反序列化生成对象的多个副本。 相比之下,在这种情况下,Java序列化将对象序列化一次,并且在反序列化对象时,它会生成具有多个引用的对象的一个实例。
Geode PDX序列化
Geode的便携式数据交换(PDX)是一种跨语言数据格式,可以降低分发和序列化对象的成本。 PDX将数据存储在您可以单独访问的命名字段中,以避免反序列化整个数据对象的成本。 PDX还允许您混合已添加或删除字段的对象版本。
Geode PDX序列化功能
Geode PDX序列化在功能方面具有多项优势。
使用PDX序列化的高级步骤
要使用PDX序列化,您可以配置和使用Geode基于反射的自动化程序,也可以使用PDX接口和类对对象的序列化进行编程。
使用基于自动反射的PDX序列化
您可以将缓存配置为自动序列化和反序列化域对象,而无需向其添加任何额外代码。
使用PdxSerializer序列化您的域对象
对于您不能或不想修改的域对象,请使用
PdxSerializer类来序列化和反序列化对象的字段。 您对整个缓存使用一个PdxSerializer实现,为您以这种方式处理的所有域对象编程。在域对象中实现PdxSerializable
对于可以修改源的域对象,在对象中实现
PdxSerializable接口,并使用其方法序列化和反序列化对象的字段。编写应用程序以使用PdxInstances
PdxInstance是PDX序列化字节周围的轻量级包装器。 它为应用程序提供对PDX序列化对象字段的运行时访问。将JSON文档添加到Geode缓存
JSONFormatterAPI允许您将JSON格式的文档放入区域,然后通过将文档作为PdxInstances存储在内部来检索它们。使用PdxInstanceFactory创建PdxInstances
当域类在服务器上不可用时,您可以使用
PdxInstanceFactory接口从原始数据创建PdxInstance。将PDX元数据保留到磁盘
Geode允许您将PDX元数据持久保存到磁盘并指定要使用的磁盘存储。
使用PDX对象作为区域条目键
Using PDX objects as region entry keys is highly discouraged.
Geode PDX序列化功能
Geode PDX序列化在功能方面具有多项优势。
PDX域对象的应用程序版本控制
域对象随应用程序代码一起发展。 您可以创建一个具有两个地址行的地址对象,然后稍后实现某些情况下需要第三行。 或者您可能会意识到某个特定字段未被使用并且想要摆脱它。 使用PDX,如果版本因添加或删除字段而不同,则可以在群集中一起使用旧版本和新版本的域对象。 通过此兼容性,您可以逐步将已修改的代码和数据引入群集,而无需关闭群集。
Geode维护PDX域对象元数据的中央注册表。 无论字段是否已定义,Geode都使用注册表保留每个成员缓存中的字段。 当成员收到具有该成员不知道的注册字段的对象时,该成员不会访问该字段,而是保留该字段并将其与整个对象一起传递给其他成员。 当成员根据成员的版本收到缺少一个或多个字段的对象时,Geode会将字段类型的Java默认值分配给缺少的字段。
PDX可序列化对象的可移植性
使用PDX序列化对象时,Geode将对象的类型信息存储在中央注册表中。 信息在客户端和服务器,对等端和集群之间传递。
对象类型信息的这种集中对于客户端/服务器安装是有利的,其中客户端和服务器以不同语言编写。 客户端在存储PDX序列化对象时会自动将注册表信息传递给服务器。 客户端可以针对服务器中的数据运行查询和功能,而无需服务器和存储对象之间的兼容性。 一个客户端可以将数据存储在服务器上以供另一个客户端检索,而服务器部分没有要求。
减少序列化对象的反序列化
PDX序列化对象的访问方法允许您检查域对象的特定字段,而无需反序列化整个对象。 根据您的对象使用情况,您可以显着降低序列化和反序列化成本。
Java和其他客户端可以针对服务器缓存中的对象运行查询和执行函数,而无需反序列化服务器端的整个对象。 查询引擎自动识别PDX对象,检索对象的PdxInstance并仅使用它需要的字段。 同样,对等体只能访问序列化对象中的必要字段,从而使对象以序列化形式保存在缓存中。
使用PDX序列化的高级步骤
要使用PDX序列化,您可以配置和使用Geode基于反射的自动化程序,也可以使用PDX接口和类对对象的序列化进行编程。
(可选)对应用程序代码进行编程,以便对序列化对象的PDX表示中的各个字段进行反序列化。 您可能还需要将PDX元数据保留到磁盘以便在启动时进行恢复。
步骤
对于要使用PDX序列化序列化的每种对象类型,请使用以下序列化选项之一:
要确保服务器不需要加载应用程序类,请将
pdxread-serialized属性设置为true。 在gfsh中,在启动服务器之前执行以下命令:gfsh>configure pdx --read-serialized=true通过使用gfsh,此配置可以通过集群配置服务在群集中传播。 或者,您需要在每个服务器的
cache.xml文件中配置pdx read-serialized。如果要将任何Geode数据存储在磁盘上,则必须配置PDX序列化以使用持久性。 有关详细信息,请参阅将PDX元数据保留到磁盘 。
(可选)无论您在何处运行显式应用程序代码来检索和管理缓存条目,您都可能希望在不使用完全反序列化的情况下管理数据对象。 要执行此操作,请参阅编写应用程序以使用Pdx实例.
PDX和多站点(WAN)部署
仅对于多站点(WAN)安装 - 如果要在任何启用WAN的区域中使用PDX序列化,则对于每个群集,必须选择介于0(零)和255之间的唯一整数并设置distributed-system-id 在每个成员的gemfire.properties文件中。 请参见配置多站点(WAN)系统.
使用基于自动反射的PDX序列化
您可以将缓存配置为自动序列化和反序列化域对象,而无需向其添加任何额外代码。
您可以自动序列化和反序列化域对象,而无需编写PdxSerializer类。 您可以通过使用名为ReflectionBasedAutoSerializer的自定义PdxSerializer注册域对象来执行此操作,该自定义PdxSerializer使用Java反射来推断要序列化的字段。
您还可以扩展ReflectionBasedAutoSerializer以自定义其行为。 例如,您可以为BigInteger和BigDecimal类型添加优化的序列化支持。 有关详细信息,请参阅扩展ReflectionBasedAutoSerializer 。
注意: 您的自定义PDX autoserializable类不能使用org.apache.geode包。 如果是这样,PDX自动序列化器将忽略这些类。
先决条件
- 一般了解如何配置Geode缓存。
- 了解PDX序列化的工作原理以及如何配置应用程序以使用
PdxSerializer。
步骤
在从缓存管理数据的应用程序中,根据需要提供以下配置和代码:
在您希望自动化的域类中,确保每个类都有一个零参数构造函数。 例如:
public PortfolioPdx(){}使用以下方法之一,将PDX序列化程序设置为
ReflectionBasedAutoSerializer。在gfsh中,在启动托管数据的任何成员之前执行以下命令:
gfsh>configure pdx --auto-serializable-classes=com\.company\.domain\..*通过使用gfsh,此配置可以通过[Cluster Configuration Service]在群集中传播(https://geode.apache.org/docs/guide/17/configuring/cluster_config/gfsh_persist.html).
或者,在
cache.xml中:<!-- Cache configuration configuring auto serialization behavior --> <cache> <pdx> <pdx-serializer> <class-name> org.apache.geode.pdx.ReflectionBasedAutoSerializer </class-name> <parameter name="classes"> <string>com.company.domain.DomainObject</string> </parameter> </pdx-serializer> </pdx> ... </cache>参数
classes采用逗号分隔的类模式列表来定义要序列化的域类。 如果您的域对象是其他域类的聚合,则需要明确注册域对象和每个域类,以便完全序列化域对象。使用 Java API:
Cache c = new CacheFactory() .setPdxSerializer(new ReflectionBasedAutoSerializer("com.company.domain.DomainObject")) .create();
使用以下机制之一自定义
ReflectionBasedAutoSerializer的行为:- 通过使用类模式字符串来指定要自动序列化的类,并自定义类的序列化方式。 可以通过将字符串传递给
ReflectionBasedAutoSerializer构造函数或在cache.xml中指定类模式字符串来指定类模式字符串。 有关详细信息,请参阅使用类模式字符串自定义序列化。 - 通过创建
ReflectionBasedAutoSerializer的子类并覆盖特定方法。 有关详细信息,请参阅扩展ReflectionBasedAutoSerializer。
- 通过使用类模式字符串来指定要自动序列化的类,并自定义类的序列化方式。 可以通过将字符串传递给
如果需要,配置
ReflectionBasedAutoSerializer以检查它在尝试自动化之前传递的对象的可移植性。 当此标志设置为true时,ReflectionBasedAutoSerializer将在尝试自动化非可移植对象时抛出NonPortableClassException错误。 要设置此项,请使用以下配置:在gfsh中,使用以下命令:
gfsh>configure pdx --portable-auto-serializable-classes=com\.company\.domain\..*通过使用gfsh,此配置可以通过Cluster Configuration Service在群集中传播。
在cache.xml中:
<!-- Cache configuration configuring auto serialization behavior --> <cache> <pdx> <pdx-serializer> <class-name> org.apache.geode.pdx.ReflectionBasedAutoSerializer </class-name> <parameter name="classes"> <string>com.company.domain.DomainObject</string> </parameter> <parameter name="check-portability"> <string>true</string> </parameter> </pdx-serializer> </pdx> ... </cache>使用 Java API:
Cache c = new CacheFactory() .setPdxSerializer(new ReflectionBasedAutoSerializer(true,"com.company.domain.DomainObject")) .create();
对于您提供的每个域类,除了那些定义为static或transient的字段以及使用类模式字符串明确排除的字段外,所有字段都被视为序列化。
注意: ReflectionBasedAutoSerializer遍历给定域对象的类层次结构,以检索要考虑进行序列化的所有字段。 因此,如果DomainObjectB继承自DomainObjectA,则只需注册DomainObjectB即可将所有DomainObjectB序列化。
使用类模式字符串自定义序列化
使用类模式字符串命名要使用Geode基于反射的自动传感器序列化的类,并指定对象标识字段并指定要从序列化中排除的字段。
用于配置ReflectionBasedAutoSerializer的类模式字符串是标准正则表达式。 例如,此表达式将选择com.company.domain包及其子包中定义的所有类:
com\.company\.domain\..*
您可以使用特殊符号扩充模式字符串,以定义要从序列化中排除的字段,并定义要标记为PDX标识字段的字段。 模式字符串的完整语法是:
<class pattern> [# (identity|exclude) = <field pattern>]... [, <class pattern>...]
以下示例模式字符串设置这些PDX序列化条件:
- 名称与模式
com.company.DomainObject.*匹配的类被序列化。 在这些类中,以id开头的字段标记为标识字段,名为creationDate的字段未标记为序列化。 - 类
com.company.special.Patient被序列化。 在类中,字段ssn被标记为标识字段
com.company.DomainObject.*#identity=id.*#exclude=creationDate,
com.company.special.Patient#identity=ssn
注意: identity和exclude选项之间没有关联,因此上面的模式也可以表示为:
com.company.DomainObject.*#identity=id.*, com.company.DomainObject.*#exclude=creationDate,
com.company.special.Patient#identity=ssn
注意: 模式的顺序无关紧要。 在确定字段是应该被视为标识字段还是应该被排除时,使用所有定义的类模式。
例子:
此XML使用上面显示的示例模式:
<parameter name="classes"> <string>com.company.DomainObject.*#identity=id.*#exclude=creationDate, com.company.special.Patient#identity=ssn</string> </parameter>此应用程序代码设置相同的模式:
classPatterns.add("com.company.DomainObject.*#identity=id.*#exclude=creationDate, com.company.special.Patient#identity=ssn");此应用程序代码具有相同的效果:
Cache c = new CacheFactory().set("cache-xml-file", cacheXmlFileName) .setPdxSerializer(new ReflectionBasedAutoSerializer("com.foo.DomainObject*#identity=id.*", "com.company.DomainObject.*#exclude=creationDate","com.company.special.Patient#identity=ssn")) .create();
扩展ReflectionBasedAutoSerializer
您可以扩展ReflectionBasedAutoSerializer以自定义方式处理序列化。 本节概述了可用的基于方法的自定义选项以及扩展序列化程序以支持BigDecimal和BigInteger类型的示例。
扩展ReflectionBasedAutoSerializer的原因
扩展ReflectionBasedAutoSerializer的主要用例之一是,您希望它处理当前需要由标准Java序列化处理的对象。 必须使用标准Java序列化有几个问题,可以通过扩展PDXReflectionBasedAutoSerializer来解决。
- 每次我们从Geode序列化对象转换为将被Java I/O序列化的对象时,必须序列化额外数据。 这可能会导致大量的序列化开销。 这就是为什么值得扩展
ReflectionBasedAutoSerializer以处理通常必须是Java I/O序列化的任何类的原因。 - 当遇到对象图时,扩展可以使用
ReflectionBasedAutoSerializer的类的数量是有益的。 在对象上使用Java I/O序列化之后,对象图中该对象下的任何对象也必须是Java I/O序列化的。 这包括通常使用PDX或DataSerializable序列化的对象。 - 如果在对象上完成标准Java I/O序列化并且您启用了检查可移植性,则将引发异常。 即使您不关心对象的可移植性,也可以使用此标志来查找哪些类将使用标准Java序列化(通过获取它们的异常),然后增强自动序列化程序来处理它们。
覆盖ReflectionBasedAutoSerializer行为
您可以通过覆盖以下方法来自定义ReflectionBasedAutoSerializer中的特定行为:
- isClassAutoSerialized 自定义要自动化的类。
- isFieldIncluded 指定要自动化的类的哪些字段。
- getFieldName 定义将在autoserialization期间生成的特定字段名称。
- isIdentifyField 控制哪个字段标记为标识字段。 当PdxInstance计算其哈希码以确定它是否等于另一个对象时,将使用标识字段。
- getFieldType 确定自动化给定字段时将使用的字段类型。
- transformFieldValue 控制是否可以在序列化期间转换PDX对象的特定字段值。
- writeTransform 控制在自动序列化期间写入的字段值。
- readTransform 控制在自动反序列化期间读取的字段值。
这些方法仅在ReflectionBasedAutoSerializer第一次看到新类时调用。 结果会被记住和使用的下一次同样的类被看见。
有关这些方法及其默认行为的详细信息,请参阅[ReflectionBasedAutoSerializer]上的JavaDocs(https://geode.apache.org/releases/latest/javadoc/org/apache/geode/pdx/ReflectionBasedAutoSerializer.html) 以获取详细信息。
优化BigInteger和BigDecimal类型的自动化的示例
本节提供了扩展ReflectionBasedAutoSerializer以优化BigInteger和BigDecimal类型的自动序列化的示例。
下面的代码示例说明了ReflectionBasedAutoSerializer的子类,它优化了BigInteger和BigDecimal autoserialization:
public static class BigAutoSerializer extends ReflectionBasedAutoSerializer {
public BigAutoSerializer(Boolean checkPortability, string… patterns) {
super(checkPortability, patterns);
}
@Override
public FieldType get FieldType(Field f, Class<?> clazz) {
if (f.getType().equals(BigInteger.class)) {
return FieldType.BYTE_ARRAY;
} else if (f.getType().equals(BigDecimal.class)) {
return FieldType.STRING;
} else {
return super.getFieldType(f, clazz);
}
}
@Override
public boolean transformFieldValue(Field f, Class<?> clazz) {
if (f.getType().equals(BigInteger.class)) {
return true;
} else if (f.getType().equals(BigDecimal.class)) {
return true;
} else {
return super.transformFieldValue(f, clazz);
}
}
@Override
public Object writeTransform(Field f, Class<?> clazz, Object originalValue) {
if (f.getType().equals(BigInteger.class)) {
byte[] result = null;
if (originalValue != null) {
BigInteger bi = (BigInteger)originalValue;
result = bi.toByteArray();
}
return result;
} else if (f.getType().equals(BigDecimal.class)) {
Object result = null;
if (originalValue != null) {
BigDecimal bd = (BigDecimal)originalValue;
result = bd.toString();
}
return result;
} else {
return super.writeTransform(f, clazz, originalValue);
}
}
@Override
public Object readTransform(Field f, Class<?> clazz, Object serializedValue) {
if (f.getType().equals(BigInteger.class)) {
BigInteger result = null;
if (serializedValue != null) {
result = new BigInteger((byte[])serializedValue);
}
return result;
} else if (f.getType().equals(BigDecimal.class)) {
BigDecimal result = null;
if (serializedValue != null) {
result = new BigDecimal((String)serializedValue);
}
return result;
} else {
return super.readTransform(f, clazz, serializedValue);
}
}
}
使用PdxSerializer序列化您的域对象
对于您不能或不想修改的域对象,请使用PdxSerializer类来序列化和反序列化对象的字段。 您对整个缓存使用一个PdxSerializer实现,为您以这种方式处理的所有域对象编程。
使用PdxSerializer,您可以按原样保留域对象,并在单独的序列化程序中处理序列化和反序列化。 您在缓存PDX配置中注册序列化程序。 对序列化程序进行编程以处理所需的所有域对象。
如果您编写自己的PdxSerializer并且还使用ReflectionBasedAutoSerializer,那么PdxSerializer需要拥有ReflectionBasedAutoSerializer并委托给它。 Cache只能有一个PdxSerializer实例。
注意: PdxSerializer的toData和fromData方法与PdxSerializable的方法不同。 它们具有不同的参数和结果。
步骤
在您希望PDX序列化的域类中,确保每个类都有一个零参数构造函数。 例如:
public PortfolioPdx(){}如果您还没有为其他域对象实现
PdxSerializer,请执行以下步骤:创建一个新类作为缓存范围的序列化程序,并使其实现
PdxSerializer。 如果要在cache.xml文件中声明新类,请让它实现Declarable。例子:
import org.apache.geode.cache.Declarable; import org.apache.geode.pdx.PdxReader; import org.apache.geode.pdx.PdxSerializer; import org.apache.geode.pdx.PdxWriter; public class ExamplePdxSerializer implements PdxSerializer, Declarable { ...在高速缓存pdx配置中,在高速缓存的
<pdx><pdx-serializer><class-name>属性中注册序列化器类。例子:
// Configuration setting PDX serializer for the cache <cache> <pdx> <pdx-serializer> <class-name>com.company.ExamplePdxSerializer</class-name> </pdx-serializer> </pdx> ... </cache>或者使用
CacheFactory.setPdxSerializerAPI。Cache c = new CacheFactory .setPdxSerializer(new ExamplePdxSerializer()) .create();
注意: 您不能使用gfsh指定自定义
pdx-serializer类,但configure pdx命令会自动配置org.apache.geode.pdx.ReflectionBasedAutoSerializer类。 见configure pdx.编程
PdxSerializer.toData来识别,强制转换和处理你的域对象:- 使用
PdxWriter写入方法编写域类的每个标准Java数据字段。 - 为你希望Geode用来识别你的对象的每个字段调用
PdxWritermarkIdentityField方法。 把它放在字段的写方法之后。 Geode使用此信息来比较不同查询等操作的对象。 如果你没有设置至少一个身份字段,那么equals和hashCode方法将使用所有PDX字段来比较对象,因此也不会执行。 重要的是,equals和hashCode实现使用的字段与您标记为标识字段的字段相同。 - 对于类的特定版本,您需要每次始终写入相同的命名字段。 对于相同的类版本,字段名称或字段数不得从一个实例更改为另一个实例。
- 为获得最佳性能,首先是固定宽度字段,然后是可变长度字段。
- 如果需要,可以在序列化之前检查对象的可移植性,方法是在使用
ppxWriterwriteObject,writeObjectArray和writeField方法时添加checkPortability参数。
示例
toData代码:public boolean toData(Object o, PdxWriter writer) { if(!(o instanceof PortfolioPdx)) { return false; } PortfolioPdx instance = (PortfolioPdx) o; writer.writeInt("id", instance.id) //identity field .markIdentityField("id") .writeDate("creationDate", instance.creationDate) .writeString("pkid", instance.pkid) .writeObject("positions", instance.positions) .writeString("type", instance.type) .writeString("status", instance.status) .writeStringArray("names", instance.names) .writeByteArray("newVal", instance.newVal) return true; }编写
PdxSerializer.fromData来创建类的实例,使用PdxReader读取方法将序列化表单中的数据字段读入对象的字段,并返回创建的对象。提供与
toData中相同的名称,并以与调用toData实现中的写操作相同的顺序调用读操作。Geode为
fromData方法提供了域类类型和PdxReader。示例
fromData代码:public Object fromData(Class<?> clazz, PdxReader reader) { if(!clazz.equals(PortfolioPdx.class)) { return null; } PortfolioPdx instance = new PortfolioPdx(); instance.id = reader.readInt("id"); instance.creationDate = reader.readDate("creationDate"); instance.pkid = reader.readString("pkid"); instance.positions = (Map<String, PositionPdx>)reader.readObject("positions"); instance.type = reader.readString("type"); instance.status = reader.readString("status"); instance.names = reader.readStringArray("names"); instance.newVal = reader.readByteArray("newVal"); return instance; }
- 使用
如果需要,您还可以在使用
PdxWriter时启用额外验证。 您可以通过将系统属性gemfire.validatePdxWriters设置为true来设置此项。 请注意,如果要调试新代码,则只应设置此选项,因为此选项会降低系统性能。
在域对象中实现PdxSerializable
对于可以修改源的域对象,在对象中实现PdxSerializable接口,并使用其方法序列化和反序列化对象的字段。
步骤
在您的域类中,实现
PdxSerializable,导入所需的org.apache.geode.pdx类。例如:
import org.apache.geode.pdx.PdxReader; import org.apache.geode.pdx.PdxSerializable; import org.apache.geode.pdx.PdxWriter; public class PortfolioPdx implements PdxSerializable { ...如果您的域类没有零参数构造函数,请为其创建一个。
例如:
public PortfolioPdx(){}程序
PdxSerializable.toData使用
PdxWriter写入方法编写域类的每个标准Java数据字段。 Geode自动为PdxSerializable对象的toData方法提供PdxWriter。为你希望Geode用来识别你的对象的每个字段调用
PdxWritermarkIdentifyField方法。 把它放在字段的写方法之后。 Geode使用此信息来比较不同查询等操作的对象。 如果你没有设置至少一个身份字段,那么equals和hashCode方法将使用所有PDX字段来比较对象,因此也不会执行。 重要的是,equals和hashCode实现使用的字段与您标记为标识字段的字段相同。对于类的特定版本,您需要每次始终写入相同的命名字段。 对于相同的类版本,字段名称或字段数不得从一个实例更改为另一个实例。
为获得最佳性能,首先是固定宽度字段,然后是可变长度字段。
示例
toData代码:// PortfolioPdx fields private int id; private String pkid; private Map<String, PositionPdx> positions; private String type; private String status; private String[] names; private byte[] newVal; private Date creationDate; ... public void toData(PdxWriter writer) { writer.writeInt("id", id) // The markIdentifyField call for a field must // come after the field's write method .markIdentityField("id") .writeDate("creationDate", creationDate) //fixed length field .writeString("pkid", pkid) .writeObject("positions", positions) .writeString("type", type) .writeString("status", status) .writeStringArray("names", names) .writeByteArray("newVal", newVal) }
编程
PdxSerializable.fromData使用PdxReader读取方法将序列化形式的数据字段读入对象的字段。提供与
toData中相同的名称,并以与调用toData实现中的写操作相同的顺序调用读操作。Geode自动为
PdxSerializableobjects的fromData方法提供PdxReader。示例
fromData代码:public void fromData(PdxReader reader) { id = reader.readInt("id"); creationDate = reader.readDate("creationDate"); pkid = reader.readString("pkid"); position1 = (PositionPdx)reader.readObject("position1"); position2 = (PositionPdx)reader.readObject("position2"); positions = (Map<String, PositionPdx>)reader.readObject("positions"); type = reader.readString("type"); status = reader.readString("status"); names = reader.readStringArray("names"); newVal = reader.readByteArray("newVal"); arrayNull = reader.readByteArray("arrayNull"); arrayZeroSize = reader.readByteArray("arrayZeroSize"); }
接下来做什么
- 根据需要,配置和编程Geode应用程序以使用
PdxInstance进行选择性对象反序列化。 请参阅编写应用程序以使用Pdx实例.
编写应用程序以使用PdxInstances
PdxInstance是PDX序列化字节周围的轻量级包装器。 它为应用程序提供对PDX序列化对象字段的运行时访问。
您可以将缓存配置为在反序列化PDX序列化对象时返回PdxInstance,而不是将对象反序列化为域类。 然后,您可以编写读取条目的应用程序代码,以处理从缓存中获取的PdxInstance。
注意: 这仅适用于使用诸如EntryEvent.getNewValue和Region.get之类的方法显式编码的条目检索,就像在函数内部或缓存侦听器代码中一样。 这不适用于查询,因为查询引擎会检索条目并为您处理对象访问。
如果将高速缓存配置为允许PDX序列化读取,则从高速缓存中获取将以找到的形式返回数据。 如果对象未序列化,则fetch返回域对象。 如果对象是序列化的,则fetch返回对象的PdxInstance。
注意: 如果您使用的是PdxInstance,则无法使用增量传播将更改应用于PDX序列化对象。
例如,在编程和配置为处理来自客户端的所有数据活动的客户端/服务器应用程序中,在服务器端完成的PDX序列化读取将始终返回PdxInstance。 这是因为所有数据都被序列化以便从客户端传输,并且您没有执行任何服务器端活动来反序列化服务器缓存中的对象。
在混合情况下,例如从客户端操作填充服务器缓存以及在服务器端完成的数据加载,在服务器上完成的提取可以返回PdxInstance和域对象的混合。
在启用PDX序列化读取的高速缓存中获取数据时,最安全的方法是编码以处理这两种类型,从获取操作接收对象,检查类型并在适当时进行转换。 但是,如果您知道该类在JVM中不可用,则可以避免执行类型检查。
PdxInstance会覆盖您为对象的equals和hashcode方法编写的任何自定义实现。 编写PDX序列化对象时,请确保至少标记了一个标识字段。 如果您没有设置至少一个标识字段,那么PdxInstanceequals和hashCode方法将使用所有PDX字段来比较对象,因此也不会执行。
先决条件
- 一般了解如何配置Geode缓存。 参见基本配置和编程.
步骤
在从缓存中获取数据的应用程序中,根据需要提供以下配置和代码:
在运行条目提取的成员的cache.xml文件中,将
<pdx>read-serialized属性设置为true。 不必在您为其编码的成员上访问数据。 例如,如果客户端应用程序在服务器上运行某个函数,则实际的数据访问是在服务器上完成的,因此您在服务器上将read-serialized设置为true。例如:
// Cache configuration setting PDX read behavior <cache> <pdx read-serialized="true" /> ... </cache>编写从缓存中获取数据的应用程序代码来处理
PdxInstance。 如果您确定只从缓存中检索PdxInstance,则只能为此编码。 在许多情况下,可能会从缓存条目检索操作返回PdxInstance或域对象,因此您应检查对象类型并处理每种可能的类型。例如:
// put/get code with serialized read behavior // put is done as normal myRegion.put(myKey, myPdxSerializableObject); // get checks Object type and handles each appropriately Object myObject = myRegion.get(myKey); if (myObject instanceof PdxInstance) { // get returned PdxInstance instead of domain object PdxInstance myPdxInstance = (PdxInstance)myObject; // PdxInstance.getField deserializes the field, but not the object String fieldValue = myPdxInstance.getField("stringFieldName"); // Update a field and put it back into the cache // without deserializing the entire object WritablePdxInstance myWritablePdxI = myPdxInstance.createWriter(); myWritablePdxI.setField("fieldName", fieldValue); region.put(key, myWritablePdxI); // Deserialize the entire object if needed, from the PdxInstance DomainClass myPdxObject = (DomainClass)myPdxInstance.getObject(); } else if (myObject instanceof DomainClass) { // get returned instance of domain object // code to handle domain object instance ... } ...注意: 由于PDX的限制,如果启用PDX的缓存包含TreeSet域对象,则应实现可以处理域对象和PdxInstance对象的Comparator。 您还需要在服务器上提供域类。
将JSON文档添加到Geode缓存
JSONFormatter API允许您将JSON格式的文档放入区域,然后通过将文档作为PdxInstances存储在内部来检索它们。
Geode本身支持使用JSON格式的文档。 将JSON文档添加到Geode缓存时,可以调用JSONFormatter API将它们转换为PDX格式(作为PdxInstance),这使Geode能够在字段级别理解JSON文档。
在查询和索引方面,由于文档在内部存储为PDX,因此应用程序可以对JSON文档中包含的任何字段(包括任何嵌套字段(在JSON对象或JSON数组中)进行索引。)对这些存储文档运行的任何查询都将返回PdxInstances 作为结果。 要更新存储在Geode中的JSON文档,可以在PdxInstance上执行一个函数。
然后,您可以使用JSONFormatter将PdxInstance结果转换回JSON文档。
JSONFormatter使用流解析器(Jackson,JSON处理器)将JSON文档转换为优化的PDX格式。 要使用JSONFormatter,请确保应用程序的CLASSPATH中有lib/geode-dependencies.jar。
JSONFormatter类有四个静态方法,用于将JSON文档转换为PdxInstances,然后将这些PdxInstances转换回JSON文档。
在将任何JSON文档放入Geode区域之前,需要调用以下方法:
fromJSON. 从JSON字节数组创建PdxInstance。 返回PdxInstance。fromJSON. 从JSON字符串创建PdxInstance。 返回PdxInstance。
将JSON文档作为PdxInstance放入区域后,您可以执行标准Geode查询并在JSON文档上创建索引,方法与查询或索引任何其他Geode PdxInstance的方式相同。
执行Geode查询或调用region.get后,您可以使用以下方法将PdxInstance转换回JSON格式:
toJSON. 读取PdxInstance并返回JSON字符串。toJSONByteArray. 读取PdxInstance并返回JSON字节数组。
有关使用JSONFormatter的更多信息,请参阅org.apache.geode.pdx.JSONFormatter的Java API文档。
序列化JSON字段的排序行为
默认情况下,Geode序列化为每个唯一的JSON文档创建唯一的pdx typeID,即使JSON文档之间的唯一区别是其字段的指定顺序。
如果您希望仅按指定字段顺序不同的JSON文档映射到相同的typeID,请将属性gemfire.pdx.mapper.sort-json-field-names设置为“true”。 这告诉系统在序列化之前对JSON字段进行排序,允许系统识别匹配的条目,并有助于减少序列化机制生成的pdx typeID的数量。
使用PdxInstanceFactory创建PdxInstances
当域类在服务器上不可用时,您可以使用PdxInstanceFactory接口从原始数据创建PdxInstance。
当您需要一个域类的实例来插入代码(如函数或加载器)时,这可能特别有用。 如果您拥有域对象的原始数据(类名和每个字段的类型和数据),那么您可以显式创建PdxInstance。 PdxInstanceFactory与PdxWriter非常相似,只是在写完每个字段后,需要调用create方法返回创建的PdxInstance。
创建工厂调用RegionService.createPdxInstanceFactory。 工厂只能创建单个实例。 要创建多个实例,请创建多个工厂或使用PdxInstance.createWriter()来创建后续实例。 使用PdxInstance.createWriter()通常更快。
创建PdxInstance时,使用markIndentityField方法设置至少一个标识字段。 如果不标记标识字段,则PdxInstanceequals和hashCode方法将使用所有PDX字段来比较对象,因此也不会执行。 重要的是,equals和hashCode实现使用的字段与您标记为标识字段的字段相同。
以下是使用PdxInstanceFactory的代码示例:
PdxInstance pi = cache.createPdxInstanceFactory("com.company.DomainObject")
.writeInt("id", 37)
.markIdentityField("id")
.writeString("name", "Mike Smith")
.writeObject("favoriteDay", cache.createPdxEnum("com.company.Day", "FRIDAY", 5))
.create();
有关更多信息,请参阅Java API文档中的PdxInstanceFactory。
枚举对象为PdxInstances
您现在可以使用枚举对象作为PdxInstances。 从缓存中获取枚举对象时,现在可以将其反序列化为PdxInstance。 要检查PdxInstance是否为枚举,请使用PdxInstance.isEnum方法。 枚举PdxInstance将有一个名为name的字段,其值是与枚举常量名称对应的String。
枚举PdxInstance不可写; 如果你调用createWriter它将抛出异常。
RegionService有一个方法,允许你创建一个表示枚举的PdxInstance。 请参阅Java API文档中的RegionService.createPdxEnum。
将PDX元数据保留到磁盘
Geode允许您将PDX元数据持久保存到磁盘并指定要使用的磁盘存储。
先决条件
步骤
- 在缓存配置中将
<pdx>属性persistent设置为true。 对于将PDX与持久区域一起使用的缓存以及使用网关发送方通过WAN分发事件的区域,这是必需的。否则,它是可选的。 - (可选)如果要使用不是Geode默认磁盘存储的磁盘存储,请将
<pdx>属性disk-store-name设置为非默认磁盘存储的名称。 注意:如果您使用PDX序列化对象作为区域条目键并且您使用的是持久区域,则必须将PDX磁盘存储配置为与持久区域使用的磁盘存储不同。 - (可选)如果以后要重命名持久保存到磁盘的PDX类型,则可以通过执行
pdx rename命令在脱机磁盘存储上执行此操作。 见pdx 重命名.
示例cache.xml:
此示例cache.xml启用PDX持久性并在服务器缓存配置中设置非默认磁盘存储:
<pdx read-serialized="true"
persistent="true" disk-store-name="SerializationDiskStore">
<pdx-serializer>
<class-name>pdxSerialization.defaultSerializer</class-name>
</pdx-serializer>
</pdx>
<region ...
使用PDX对象作为区域输入键
强烈建议不要将PDX对象用作区域条目键。
创建区域条目键的最佳做法是使用简单的键; 例如,使用String或Integer。 如果key必须是域类,则应使用非PDX序列化类。
如果必须使用PDX序列化对象作为区域条目键,请确保不要将read-serialized设置为true。 此配置设置将导致分区区域出现问题,因为分区区域要求key的哈希码在分布式系统中的所有JVM上都相同。 当键是PdxInstance对象时,其哈希码可能与域对象的哈希码不同。
如果您使用PDX序列化对象作为区域条目键并且您使用的是持久区域,则必须将PDX磁盘存储配置为与持久区域使用的磁盘存储不同。
Geode数据序列化(DataSerializable和DataSerializer)
Geode的DataSerializable接口为您提供了对象的快速序列化。
使用DataSerializable接口进行数据序列化
Geode的DataSerializable接口为您提供比标准Java序列化或Geode PDX序列化更快,更紧凑的数据序列化。 然而,虽然GeodeDataSerializable接口通常比Geode的'PdxSerializable`更高性能,但它需要在服务器上进行完全反序列化,然后再进行重新序列化以将数据发送回客户端。
您可以通过Instantiator注册DataSerializable类的实例化器来进一步加速序列化,从而无需反射来找到正确的序列化器。 您可以通过API提供自己的序列化。
注册自定义Instantiator的推荐方法是在cache.xml的serialization-registration元素中指定它。
有关更多信息,请参阅DataSerializable和DataSerializer的在线Java文档。
例子 cache.xml:
以下提供了如何使用cache.xml注册实例化器的示例。
<serialization-registration>
<instantiator id="30">
<class-name>com.package.MyClass</class-name>
</instantiator>
</serialization-registration>
除了加速标准对象序列化之外,您还可以使用DataSerializable接口来序列化存储在缓存中的任何自定义对象。
使用DataSerializer序列化您的域对象
您还可以使用DataSerializer来序列化域对象。 它以与DataSerializable相同的方式序列化数据,但允许您在不修改域类代码的情况下序列化类。
请参阅[DataSerializable]上的JavaDocs(https://geode.apache.org/releases/latest/javadoc/org/apache/geode/DataSerializable.html)和[DataSerializer](https://geode.apache.org/releases/latest/javadoc/org/apache/geode/DataSerializer.html) 了解更多信息。
标准Java序列化
您可以对仅在Java应用程序之间分发的数据使用标准Java序列化。 如果在非Java客户端和Java服务器之间分发数据,则需要执行其他编程以获取各种类格式之间的数据。
根据定义,标准Java类型是可序列化的。 对于您的域类,实现java.io.Serializable,然后确保根据对象标记瞬态和静态变量。 有关信息,请参阅Java版本的java.io.Serializable的联机文档。
将DataSerializable与Serializable或PdxSerializable混合使用在相同的数据上会导致内存使用量增加,吞吐量低于仅对整个数据使用Serializable,特别是如果Serializable条目在集合中。 数据收集越大,吞吐量越低,因为使用DataSerializable时不会共享集合条目的元数据。
事件和事件处理
Geode为缓存的数据和系统成员事件提供了通用且可靠的事件分发和处理。
事件是如何工作
集群中的成员通过缓存事件从其他成员接收缓存更新。 其他成员可以是成员,客户端或服务器或其他集群的对等成员。
实现Geode事件处理程序
您可以为区域和区域条目操作以及管理事件指定事件处理程序。
配置点对点事件消息
您可以从集群对等方接收非本地区域的任何区域的事件。 本地区域仅接收本地缓存事件。
配置客户端/服务器事件消息
您可以从服务器接收服务器端缓存事件和查询结果更改的事件。
配置多站点(WAN)事件队列
在多站点(WAN)安装中,Geode使用网关发件人队列来为使用网关发件人配置的区域分发事件。 AsyncEventListeners还使用异步事件队列来分配已配置区域的事件。 本节介绍用于配置网关发件人或AsyncEventListener实现使用的事件队列的其他选项。
事件是如何工作
Geode集群中的成员通过缓存事件从其他成员接收缓存更新。 其他成员可以是成员,客户端或服务器或其他集群的对等成员。
事件特征
这些是Geode事件的主要特征:
- 基于内容的事件
- 带有混合的异步事件通知
- 低延迟的同步事件通知
- 通过冗余消息队列实现高可用性
- 事件排序和一次且仅一次交付
- 分布式事件通知
- 持久的订阅
- 持续查询
事件类型
有两类事件和事件处理程序。
- 缓存API中的缓存事件由具有缓存的应用程序使用。 缓存事件为数据更改提供详细级别的通知。 连续查询事件属于此类别。
- 管理API中的管理事件由没有缓存的管理应用程序使用。
两种事件都可以由单个成员操作生成。
注意: 您可以在单个系统成员中处理这些类别的事件之一。 您无法在单个成员中处理缓存和管理事件。
由于Geode分别维护管理事件的顺序和缓存事件的顺序,因此在单个进程中使用缓存事件和管理事件可能会导致意外结果。
事件周期
以下步骤描述了事件周期:
- 操作开始,例如数据放入或缓存关闭。
- 操作执行生成以下对象:
Operation类型的对象,描述触发事件的方法。- 描述事件的事件对象,例如操作源自的成员和区域。
- 可以处理事件的事件处理程序被调用并传递事件对象。 不同的事件类型需要不同位置的不同处理程序类型 如果没有匹配的事件处理程序,则不会改变操作的效果,这通常会发生。
- 当处理程序收到事件时,它会触发此事件的处理程序的回调方法。 回调方法可以将事件对象作为另一个方法的输入切换。 根据事件处理程序的类型,可以在操作之前或之后触发回调。 时间取决于事件处理程序,而不是事件本身。 注意:对于事务,事务后监听器在事务提交后收到事件。
- 如果操作是分布式的,那么它会导致其他成员的后续操作,那些操作会生成他们自己的事件,这些事件可以由他们的侦听器以相同的方式处理。
事件对象
事件对象有多种类型,具体取决于操作。 某些操作会生成多个不同类型的对象。 所有事件对象都包含描述事件的数据,每个事件类型都包含适合其匹配操作的略微不同类型的数据。 事件对象是稳定的。 例如,如果将其传递给另一个线程上的方法,则其内容不会更改。
对于缓存事件,事件对象描述在本地缓存中执行的操作。 如果事件是远程发起的,则它描述远程输入操作的本地应用程序,而不是远程操作本身。 唯一的例外是本地区域有空数据策略; 然后事件携带远程(始发)高速缓存操作的信息。
事件分发
成员在其本地缓存中处理事件后,会根据成员的配置和远程缓存的配置将其分发到远程缓存。 例如,如果客户端更新其缓存,则更新将转发到客户端的服务器。 服务器将更新分发给其对等方,并根据它们对数据条目的兴趣将其转发给任何其他客户端。 如果服务器系统是多站点部署的一部分并且数据区域配置为使用网关发送方,则网关发送方还将更新转发到远程站点,在该站点中进一步分发和传播更新。
事件处理程序和区域数据存储
您可以为没有本地数据存储的区域配置区域,并仍然发送和接收该区域的事件。 相反,如果您在区域中存储数据,则无论您是否安装了任何事件处理程序,都会使用事件中的数据更新缓存。
多个监听器
安装多个侦听器时,可以使用缓存侦听器,按照添加到区域或缓存的顺序依次调用侦听器。 监听器一次执行一个。 因此,除非您将侦听器编程为将处理传递给另一个线程,否则您可以在以后的侦听器中使用一个侦听器的工作。
事件排序
在高速缓存操作期间,在操作的各个阶段调用事件处理程序。 在区域更新之前调用一些事件处理程序,在区域更新操作之后调用一些事件处理程序。 根据被调用的事件处理程序的类型,事件处理程序可以按顺序或无序接收它们在Region上应用的事件。
CacheWriter和AsyncEventListener总是按照它们在区域上应用的顺序接收事件。CacheListener和CqListener可以按照与在区域上应用它们的顺序不同的顺序接收事件。
注意: EntryEvent包含条目的旧值和新值,这有助于指示由特定键上的缓存操作替换的值。
点对点事件分发
执行区域或条目操作时,Geode会根据系统和缓存配置在集群中分配关联的事件。
为每个系统成员中需要接收区域和条目更改通知的区域安装缓存侦听器。
分区区域中的事件
分布式操作遵循此序列在分区区域中:
- 如果适用,将操作应用于具有主数据条目的缓存。
- 根据其他成员的订阅属性兴趣策略进行分发。
- 在接收分发的缓存中调用任何侦听器。
- 使用主数据条目在缓存中调用侦听器。
在下图中:
- 成员M1中的API调用创建一个条目。
- 分区区域在M2中的缓存中创建新条目。 M2,主副本的持有者,驱动程序的其余部分。
- 这两个操作同时发生:
- 分区区域在M3中的高速缓存中创建条目的辅助副本。 创建辅助副本不会调用M3上的侦听器。
- M2将事件分发给M4。 向其他成员的分配基于他们的利益政策。 M4拥有所有人的利益政策,因此它接收该地区任何地方的所有事件的通知。 由于M1和M3具有缓存内容的兴趣策略,并且此事件不会影响其本地缓存中的任何预先存在的条目,因此它们不会收到该事件。
- M4上的缓存侦听器处理M2上的远程事件的通知。
- 一旦其他成员上的所有内容都成功完成,M2上的原始创建操作就会成功并调用M2上的缓存侦听器。
分布式区域中的事件
分布式操作遵循此序列在分布式区域中:
- 如果适用,将操作应用于本地缓存。
- 调用本地侦听器。
- 做分发。
- 接收分发的每个成员在响应中执行其自己的操作,其调用任何本地侦听器。
在下图中:
- 通过成员M1上的直接API调用创建条目。
- create在M1上调用缓存侦听器。
- M1将事件分发给其他成员。
- M2和M3通过自己的本地操作应用远程更改。
- M3执行创建,但M2执行更新,因为该条目已存在于其缓存中。
- M2上的缓存侦听器接收本地更新的回调。 由于M3上没有缓存侦听器,因此不会处理来自M3上的create的回调。 成员M1中的API调用创建一个条目。
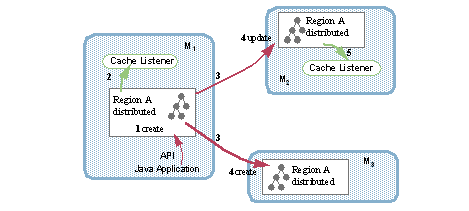
管理多线程应用程序中的事件
对于分区区域,Geode保证跨线程排序事件,但对于分布式区域,它不会。 对于创建分布式区域的多线程应用程序,您需要使用应用程序同步以确保在下一个操作开始之前完成一个操作。 如果将conserve-sockets属性设置为true,则通过distributed-no-ack队列进行分发可以使用多个线程。 然后线程共享一个队列,保留分布区域中事件的顺序。 不同的线程可以调用相同的侦听器,因此如果允许不同的线程发送事件,则可能导致侦听器的并发调用。 仅当线程具有某种共享状态时才会出现此问题 - 例如,如果它们正在递增序列号,或者将其事件添加到日志队列中。 然后,您需要使您的代码线程安全。
客户端到服务器事件分发
客户端和服务器根据客户端活动并根据客户端在服务器端缓存更改中注册的兴趣来分发事件。
当客户端更新其缓存时,对客户端区域的更改会自动转发到服务器端。 然后,服务器端更新将传播到已连接的其他客户端并启用订阅。 服务器不会将更新返回给发送客户端。
更新将传递到服务器,然后通过该值传递给已注册对条目key感兴趣的其他每个客户端。 此图显示了如何传播客户端的条目更新。

该图显示了以下过程:
- 通过Client1上的直接API调用在区域A中更新或创建条目X.
- 对该区域的更新将传递到该区域中指定的池。
- 池将事件传播到缓存服务器,更新区域。
- 服务器成员将事件分发给其对等体,并将其放入Client2的预订队列中,因为该客户端先前已注册对条目X的兴趣。
- 条目X的事件从队列发送到Client2。 当这种情况发生时是不确定的。
客户端到服务器分发使用客户端池连接将更新发送到服务器。 具有命名池的任何区域都会自动将更新转发给服务器。 客户端缓存修改首先通过客户端CacheWriter(如果已定义),然后通过客户端池传递到服务器,最后传递到客户端缓存本身。 客户端或服务器端的缓存写入器可能会中止操作。
| 更改客户端缓存 | 对服务器缓存的影响 |
|---|---|
| 条目创建或更新 | 创建或更新条目。 |
| 分布式条目销毁 | 条目销毁。 即使条目不在客户端缓存中,destroy调用也会传播到服务器。 |
| 分布式区域销毁/清除(仅分布式) | 区域销毁/清除 |
注意: 客户端的失效不会转发到服务器。
服务器到客户端事件分发
服务器仅针对客户端已注册的key自动发送条目修改事件。 在兴趣注册中,客户端指示是为服务器端条目创建和更新发送新值还是仅发送无效。 如果使用了无效,则客户端会根据需要懒惰地更新值。
此图显示了兴趣注册的完整事件订阅事件分发,请求了值收据(receiveValues = true)且没有。

| 更改服务器缓存 | 对客户端缓存的影响 |
|---|---|
| 条目创建/更新 | 对于receiveValues设置为true的订阅,条目创建或更新。对于receiveValues设置为false的订阅,如果条目已存在于客户端缓存中,则条目无效; 否则,没有效果。 下一个客户端获取的条目将转发到服务器。 |
| 条目无效/销毁(仅限分布式) | 条目无效/销毁 |
| 区域销毁/清除(仅限分布式) | 区域破坏或局部区域清除 |
服务器端分布式操作是在服务器或其中一个对等体中作为分布式操作发起的所有操作。 服务器中的区域失效不会转发到客户端。
注意: 要在服务器中维护统一的数据集,请不要在服务器区域中执行本地条目失效。
服务器到客户端的消息跟踪
服务器使用异步消息传递队列将事件发送到其客户端。 队列中的每个事件都源自客户端,服务器中的线程或服务器或某个其他集群中的应用程序执行的操作。 事件消息具有唯一标识符,该标识符由始发线程的ID与其成员的分布式系统成员ID以及操作的顺序ID组成。 因此,源自任何单个线程的事件消息可以按时间从最低序列ID到最高序列进行分组和排序。 服务器和客户端跟踪每个成员线程ID的最高顺序ID。
单个客户端线程接收并处理来自服务器的消息,跟踪收到的消息以确保它不处理重复发送。 它使用来自原始线程的进程ID来完成此操作。
![]()
客户端的消息跟踪列表保存为每个始发线程接收的任何消息的最高序列ID。 在有许多不同线程进出并在缓存上工作的系统中,该列表可能变得非常大。 线程死亡后,不需要跟踪条目。 为了避免维护已经死亡的线程的跟踪信息,客户端会使没有活动的条目超过subscription-message-tracking-timeout。
在服务器上注册客户端兴趣
系统按照以下步骤处理客户兴趣注册:
- 客户区域中可能受此注册影响的条目将被静默销毁。 其他key是独自留下的。
- 对于
registerInterest方法,系统会销毁所有指定的key,只留下客户区域中的其他key。 因此,如果您有一个带有键A,B和C的客户区,并且您在registerInterest操作开始时注册了对键列表A,B的兴趣,系统会破坏客户端缓存中的键A和B,但是 不要碰键C. - 对于
registerInterestRegex方法,系统以静默方式销毁客户区域中的所有key。
- 对于
- 兴趣规范被发送到服务器,并将其添加到客户端的兴趣列表中。 该列表可以指定在注册兴趣时不在服务器区域中的条目。
- 如果在调用的
InterestResultPolicy参数中请求批量加载,则在将控制返回到调用方法之前,服务器将发送当前满足兴趣规范的所有数据。 使用下载的数据自动更新客户端的区域。 如果服务器区域已分区,则整个分区区域将用于批量加载。 否则,仅使用服务器的本地缓存区域。 兴趣结果政策选项包括:- KEYS—客户端接收与兴趣注册标准匹配的所有可用key的批量加载。
- KEYS_VALUES—客户端接收所有可用key的批量加载和与兴趣注册标准匹配的值。 这是默认的兴趣结果政策。
- NONE—客户端没有立即收到批量加载。
一旦注册了兴趣,服务器就会持续监控区域活动并将事件发送给符合兴趣的客户。
- 注册器兴趣调用不会生成任何事件,即使它们将值加载到客户端缓存中也是如此。
- 服务器维护所有兴趣注册的联合,因此如果客户注册对密钥'A'的兴趣,然后注册对正则表达式“B*”的兴趣,服务器将发送带有key'A'或以字母'B'开头key的所有条目的更新 。
- 服务器将兴趣注册列表与区域分开。 该列表可以包含当前不在服务器区域中的条目的规范。
registerInterestRegex方法使用标准的java.util.regex方法来解析key规范。
服务器故障转移
当托管订阅队列的服务器失败时,排队职责将传递给另一台服务器。 如何发生这取决于新服务器是否是辅助服务器。 在任何情况下,所有故障转移活动都由Geode系统自动执行。
非HA故障转移: 如果未配置冗余,或者在初始化新辅助节点之前所有辅助节点都失败,则客户端在没有高可用性的情况下进行故障转移。只要它可以连接到服务器,客户端就会进行自动重新初始化过程。在此过程中,客户端上的故障转移代码以静默方式销毁客户端感兴趣的所有条目,并从新服务器中重新获取它们,实质上是从新服务器的缓存中重新初始化客户端缓存。对于notify all配置,这将清除并重新加载连接到服务器的客户端区域的所有条目。对于按订阅通知,它仅清除并重新加载区域兴趣列表中的条目。为了减少故障转移噪声,由本地条目销毁和重新获取引起的事件被故障转移代码阻止,并且不会到达客户端缓存侦听器。因此,您的客户端可能会在服务器故障转移期间和之后收到一些无序事件。例如,故障转移期间,故障服务器上存在而不是其替换的条目将被销毁,并且永远不会重新创建。由于销毁事件被阻止,因此客户端最终会从其缓存中删除条目而没有关联的销毁事件。
HA 故障转移: 如果客户端池配置了冗余,并且主服务器出现故障时辅助服务器可用,则客户端将无法访问故障转移。 一旦检测到主要丢失,辅助服务器就会恢复排队活动。 辅助节点可能会重新发送一些事件,这些事件会被客户端邮件跟踪活动自动丢弃。
注意: 在HA服务器故障转移期间,消息丢失的可能性非常小。 故障转移到已完全初始化其订阅队列数据的辅助节点的风险不存在。 在使用至少两台辅助服务器的健康系统中,风险极低。 在服务器经常出现故障的不稳定系统中,以及辅助设备在成为初选之前没有时间初始化其订阅队列数据的风险更高。 为了最小化风险,故障转移逻辑选择寿命最长的辅助节点作为新的主节点。
注意: 冗余管理由客户端处理,因此当持久客户端与服务器断开连接时,不会维护客户端事件冗余。 即使服务器一次失败一个,以便运行的客户端有时间进行故障转移并选择新的辅助服务器,脱机持久客户端也无法进行故障转移。 结果,客户端丢失其排队的消息。
多站点(WAN)事件分发
Geode在集群之间分配缓存事件的子集,对每个系统的性能影响最小。 仅为您配置为使用网关发件人进行分发的区域分发事件。
为分发排队事件
在使用一个或多个网关发件人(gateway-sender-ids属性)配置的区域中,事件会自动添加到网关发件人队列以分发到其他站点。 放置在网关发送方队列中的事件将异步分发到远程站点。 对于串行网关队列,可以使用order-policy属性保留站点之间发送的事件的顺序。
如果队列变得太满,它会溢出到磁盘以防止成员内存不足。 您可以选择将队列配置为持久保存到磁盘(使用enable-persistence gateway-sender属性)。 使用持久性,如果管理队列的成员发生故障,成员将在重新启动后从中断处继续。
来自网关发件人的操作分配
多站点安装旨在最大限度地降低对群集性能的影响,因此只有最远的入口操作才会在站点之间分配。
这些操作分布在:
- 条目创建
- 条目放置
- 条目分布式销毁,提供的操作不是到期操作
这些操作不分发:
- 获取
- 作废
- 当地销毁
- 任何类型的到期行为
- 区域操作
网关发件人如何处理其队列
每个主网关发送器都包含一个处理器线程,该线程从队列中读取消息,对其进行批处理,并将批处理分发到远程站点中的网关接收器。 要处理队列,网关发送方线程将执行以下操作:
- 从队列中读取消息
- 创建一批消息
- 同步将批处理分发到其他站点并等待回复
- 在另一个站点成功回复后,从队列中删除批处理
因为在其他站点回复之前,批处理不会从队列中删除,所以该消息不会丢失。 另一方面,在此模式下,可以多次处理消息。 如果站点在处理一批消息的过程中脱机,则一旦站点重新联机,将再次发送该批次。
您可以配置消息的批处理大小以及批处理时间间隔设置。 当达到批量大小或时间间隔时,网关发件人处理来自队列的一批消息。 在活动网络中,很可能在时间间隔之前达到批量大小。 在空闲网络中,最有可能在批量大小之前达到时间间隔。 这可能导致一些与时间间隔相对应的网络延迟。
网关发件人如何处理批处理失败
批处理期间的不同点可能会发生异常:
- 网关接收器可能会因确认而失败。 如果在网关接收器处理批处理时处理失败,则接收方将回复包含异常的失败确认,包括失败消息的标识以及成功处理的最后一条消息的ID。 然后,网关发件人从队列中删除成功处理的消息和失败的消息,并使用失败的消息信息记录异常。 然后,发送方继续处理队列中剩余的消息。
- 网关接收器可能无法确认而失败。 如果网关接收方未确认已发送的批次,则网关发件人不知道哪些消息已成功处理。 在这种情况下,网关发件人重新发送整批。
- 没有网关接收器可用于处理。 如果由于没有可用的远程网关接收器而发生批处理异常,则批处理仍保留在队列中。 网关发件人等待一段时间,然后尝试重新发送批次。 尝试之间的时间间隔为五秒。 现有服务器监视器不断尝试连接到网关接收器,以便可以建立连接并继续进行队列处理。 消息在队列中累积,并可能在等待连接时溢出到磁盘。
事件处理程序和事件列表
Geode提供了许多类型的事件和事件处理程序,可帮助您管理不同的数据和应用程序需求。
事件处理程序
在任何单个应用程序中使用缓存处理程序或成员资格处理程序。 不要同时使用两者。 除非另有说明,否则此表中的事件处理程序是缓存处理程序。
| 处理程序API | 收到的事件 | 描述 |
|---|---|---|
AsyncEventListener |
AsyncEvent |
跟踪区域中的更改以进行后写处理。 扩展CacheCallback接口。 您将回写缓存侦听器安装到AsyncEventQueue实例。 然后,您可以将“AsyncEventQueue”实例添加到一个或多个区域以进行后写处理。 请参阅实现用于后写高速缓存事件处理的AsyncEventListener。 |
CacheCallback |
所有缓存事件侦听器的超级接口。 仅用于清除回调分配的资源的函数。 | |
CacheListener |
RegionEvent, EntryEvent |
跟踪区域及其数据条目的更改。 同步响应。 扩展CacheCallback接口。 安装在地区。 仅接收本地缓存事件。 在您希望此侦听器处理事件的每个成员中安装一个。 在分区区域中,缓存侦听器仅在主数据存储中触发。 辅助听众不会被解雇。 |
CacheWriter |
RegionEvent, EntryEvent |
接收该区域及其成员或其中一个对等方中的区域及其数据条目的待定更改事件。 是否有能力中止有问题的操作。 扩展CacheCallback接口。 安装在地区。 从分布式区域中的任何位置接收事件,因此您可以为整个分布式区域安装一个成员。 仅在分区区域中的主数据存储中接收事件,因此在每个数据存储中安装一个事件。 |
ClientMembershipListener |
ClientMembershipEvent |
替换已弃用的Admin API的接口之一。 您可以使用ClientMembershipListener仅接收有关客户端的成员资格事件。 当此进程检测到客户端的连接更改时,将调用此侦听器的回调方法。 回调方法包括memberCrashed,memberJoined,memberLeft(graceful exit)。 |
CqListener |
CqEvent |
从服务器缓存接收满足客户端指定查询的事件。 扩展CacheCallback接口。 安装在CqQuery里面的客户端。 |
GatewayConflictResolver |
TimestampedEntryEvent |
决定是否将可能存在冲突的事件应用于通过WAN配置分发的区域。 仅当更新事件的分布式系统ID与上次更新区域条目的ID不同时,才会调用此事件处理程序。 |
MembershipListener |
MembershipEvent |
使用此接口仅接收有关对等方的成员资格事件。 当对等成员加入或离开集群时,将调用此侦听器的回调方法。 回调方法包括memberCrashed,memberJoined和memberLeft(graceful exit)。 |
RegionMembershipListener |
RegionEvent |
当在另一个成员中创建了具有相同名称的区域以及托管该区域的其他成员加入或离开集群时,提供事件后通知。 扩展CacheCallback和CacheListener。 作为CacheListener安装在区域中。 |
TransactionListener |
TransactionEvent with embedded list of EntryEvent |
跟踪事务的结果和事务中数据条目的更改。注意:同一缓存上的多个事务可能导致并发调用TransactionListener方法,因此实现为多个线程进行适当同步以进行线程安全操作的方法。扩展CacheCallback接口。 使用事务管理器安装在缓存中。 如果需要,可以使用区域级侦听器。 |
TransactionWriter |
TransactionEvent with embedded list of EntryEvent |
接收 pending 事务提交的事件。 有能力中止交易。 扩展CacheCallback接口。 使用事务管理器安装在缓存中。 每个事务最多调用一个编写器。 在每个事务主机中安装writer。 |
UniversalMembershipListenerAdapter |
MembershipEvent and ClientMembershipEvent |
替换已弃用的Admin API的接口之一。 为客户端和对等端的MembershipListener和ClientMembershipListener回调提供包装器。 |
事件
除非另有说明,否则此表中的事件是缓存事件。
| 事件 | 传递给处理程序 … | 描述 |
|---|---|---|
AsyncEvent |
AsyncEventListener |
提供有关异步,后写处理的高速缓存中单个事件的信息。 |
CacheEvent |
超级接口到RegionEvent和EntryEvent。 这定义了常见的事件方法,并包含诊断事件环境所需的数据,包括正在执行的操作的描述,有关事件源自何处的信息,以及传递给生成此事件的方法的任何回调参数。 |
|
ClientMembershipEvent |
ClientMembershipListener |
当此进程检测到对服务器或客户端的连接更改时,会将事件传递给ClientMembershipListener。 |
CqEvent |
CqListener |
提供有关代表客户端在服务器上运行的连续查询结果的更改的信息。 CqEvents在客户端上处理。 |
EntryEvent |
CacheListener, CacheWriter, TransactionListener(inside the TransactionEvent) |
为入口事件扩展CacheEvent。 包含有关影响缓存中数据条目的事件的信息。 信息包括key,此事件之前的值以及此事件之后的值。 EntryEvent.getNewValue返回数据条目的当前值。 EntryEvent.getOldValue返回此事件之前的值(如果可用)。 对于分区区域,如果本地缓存包含条目的主副本,则返回旧值。 EntryEvent提供Geode事务ID(如果可用)。您可以使用getSerialized *方法从EntryEvent检索序列化值。 如果从一个区域的事件中获取值只是为了将它们放入单独的缓存区域,这将非常有用。 没有对应的put函数,因为put识别该值被序列化并绕过序列化步骤。 |
MembershipEvent(membership event) |
MembershipListener |
描述发起此事件的成员的事件。 当成员加入或离开集群时,会将此实例传递给MembershipListener。 |
RegionEvent |
CacheListener, CacheWriter, RegionMembershipListener |
为区域事件扩展CacheEvent。 提供有关影响整个区域的操作的信息,例如在销毁后重新初始化该区域。 |
TimestampedEntryEvent |
GatewayConflictResolver |
扩展EntryEvent以包括与事件关联的时间戳和分布式系统ID。 冲突解决程序可以将事件中的时间戳和ID与存储在条目中的值进行比较,以确定本地系统是否应该应用潜在冲突的事件。 |
TransactionEvent |
TransactionListener, TransactionWriter |
描述事务中完成的工作。 此事件可能用于挂起或已提交的事务,也可能用于显式回滚或失败提交放弃的工作。 该工作由EntryEvent实例的有序列表表示。 条目事件按事务中执行操作的顺序列出。在执行事务操作时,条目事件被混合,每个条目的最后一个事件仅保留在列表中。 因此,如果修改了条目A,然后是条目B,那么条目A,该列表将包含条目B的事件,后面是条目A的第二个事件。 |
实现Geode事件处理程序
您可以为区域和区域条目操作以及管理事件指定事件处理程序。
实现缓存事件处理程序
根据您的安装和配置,缓存事件可以来自本地操作,对等方,服务器和远程站点。 事件处理程序在一个或多个事件中注册其兴趣,并在事件发生时得到通知。
为Write-Behind Cache事件处理实现AsyncEventListener
AsyncEventListener”在将批量事件应用于区域后异步处理这些事件。 您可以使用AsyncEventListener实现作为后写缓存事件处理程序,以将区域更新与数据库同步。如何从事件处理程序回调安全地修改缓存
事件处理程序是同步的。 如果需要更改缓存或从事件处理程序回调执行任何其他分布式操作,请小心避免可能阻止并影响整体系统性能的活动。
缓存事件处理程序示例
缓存事件处理程序的一些示例。
实现缓存事件处理程序
根据您的安装和配置,缓存事件可以来自本地操作,对等方,服务器和远程站点。 事件处理程序在一个或多个事件中注册其兴趣,并在事件发生时得到通知。
对于每种类型的处理程序,Geode为接口回调方法提供了一个带有空存根的便捷类。
注意: 通过扩展AsyncEventListener接口创建后写高速缓存侦听器,并且它们配置有您分配给一个或多个区域的AsyncEventQueue。
步骤
确定应用程序需要处理哪些事件。 对于每个区域,确定要处理的事件。 对于缓存,决定是否处理事务事件。
对于每个事件,决定使用哪些处理程序。
org.apache.geode.cache.util中的*Listener和*Adapter类显示选项。编程每个事件处理程序:
扩展处理程序的适配器类。
如果要在
cache.xml中声明处理程序,也要实现org.apache.geode.cache.Declarable接口。根据应用程序的需要实现处理程序的回调方法。
注意: 编程不正确的事件处理程序可能会阻止您的分布式系统。 缓存事件是同步的。 要根据事件修改缓存或执行分布式操作,请遵循如何从事件处理程序回调安全地修改缓存中的准则来避免阻塞系统.
例子:
package myPackage; import org.apache.geode.cache.Declarable; import org.apache.geode.cache.EntryEvent; import org.apache.geode.cache.util.CacheListenerAdapter; import java.util.Properties; public class MyCacheListener extends CacheListenerAdapter implements Declarable { /** Processes an afterCreate event. * @param event The afterCreate EntryEvent received */ public void afterCreate(EntryEvent event) { String eKey = event.getKey(); String eVal = event.getNewValue(); ... do work with event info } ... process other event types }
通过API或
cache.xml安装事件处理程序。XML Region事件处理程序安装:
<region name="trades"> <region-attributes ... > <!-- Cache listener --> <cache-listener> <class-name>myPackage.MyCacheListener</class-name> <cache-listener> </region-attributes> </region>Java Region事件处理程序安装:
tradesRegion = cache.createRegionFactory(RegionShortcut.PARTITION) .addCacheListener(new MyCacheListener()) .create("trades");XML事务编写器和监听器安装:
<cache search-timeout="60"> <cache-transaction-manager> <transaction-listener> <class-name>com.company.data.MyTransactionListener</class-name> <parameter name="URL"> <string>jdbc:cloudscape:rmi:MyData</string> </parameter> </transaction-listener> <transaction-listener> . . . </transaction-listener> <transaction-writer> <class-name>com.company.data.MyTransactionWriter</class-name> <parameter name="URL"> <string>jdbc:cloudscape:rmi:MyData</string> </parameter> <parameter ... </parameter> </transaction-writer> </cache-transaction-manager> . . . </cache>
启动成员时,在区域创建期间会自动初始化事件处理程序。
在区域上安装多个侦听器
XML:
<region name="exampleRegion">
<region-attributes>
. . .
<cache-listener>
<class-name>myCacheListener1</class-name>
</cache-listener>
<cache-listener>
<class-name>myCacheListener2</class-name>
</cache-listener>
<cache-listener>
<class-name>myCacheListener3</class-name>
</cache-listener>
</region-attributes>
</region>
API:
CacheListener listener1 = new myCacheListener1();
CacheListener listener2 = new myCacheListener2();
CacheListener listener3 = new myCacheListener3();
Region nr = cache.createRegionFactory()
.initCacheListeners(new CacheListener[]
{listener1, listener2, listener3})
.setScope(Scope.DISTRIBUTED_NO_ACK)
.create(name);
为Write-Behind Cache事件处理实现AsyncEventListener
AsyncEventListener在将批量事件应用于区域后异步处理这些事件。 您可以使用AsyncEventListener实现作为后写缓存事件处理程序,以将区域更新与数据库同步。
AsyncEventListener的工作原理
AsyncEventListener实例由其自己的专用线程提供服务,其中调用了一个回调方法。 更新区域的事件放在内部的AsyncEventQueue中,并且一个或多个线程一次将一批事件分派给侦听器实现。
您可以将AsyncEventQueue配置为串行或并行。 串行队列部署到一个Geode成员,它按发生顺序将所有区域事件传递给已配置的AsyncEventListener实现。 并行队列部署到多个Geode成员,并且队列的每个实例都可以同时将区域事件传递给本地的AsyncEventListener实现。
虽然并行队列为写入事件提供了最佳吞吐量,但它对订购这些事件提供的控制较少。 使用并行队列时,您无法保留整个区域的事件排序,因为多个Geode服务器会同时排队并传递区域的事件。 但是,可以保留给定分区(或分布式区域的给定队列)的事件顺序。
对于串行和并行队列,您可以控制每个队列使用的最大内存量,以及处理队列中批次的批量大小和频率。 您还可以将队列配置为持久保存到磁盘(而不是简单地溢出到磁盘),以便后续缓存可以在成员关闭并稍后重新启动时从中断处获取。
(可选)队列可以使用多个线程来分派排队事件。 为串行队列配置多个线程时,Geode成员上托管的逻辑队列将分为多个物理队列,每个队列都有一个专用的调度程序线程。 然后,您可以配置线程是按键,按线程还是按照将事件添加到队列的相同顺序来调度排队事件。 为并行队列配置多个线程时,托管在Geode成员上的每个队列都由调度程序线程处理; 创建的队列总数取决于托管该区域的成员数。
可以在AsyncEventQueue上放置一个GatewayEventFilter来控制是否将特定事件发送到选定的AsyncEventListener。 例如,可以检测与敏感数据相关联的事件而不排队。 有关更多详细信息,请参阅GatewayEventFilter的Javadoc。
GatewayEventSubstitutionFilter可以指定事件是完整传输还是以更改的表示形式传输。 例如,要减小要序列化的数据的大小,仅通过其键表示完整对象可能更有效。 有关更多详细信息,请参阅GatewayEventSubstitutionFilter的Javadoc。
来自AsyncEventQueue的分布式操作
AsyncEventQueue分发这些操作:
- Entry 创建
- Entry 放置
- Entry 分布式销毁,提供的操作不是到期操作
- 如果
forward-expiration-destroy属性设置为'true,则到期销毁。 默认情况下,此属性为false,但您可以使用cache.xml或gfsh将其设置为true。 要在Java API中设置此属性,请使用AsyncEventQueueFactory.setForwardExpirationDestroy()`。 有关详细信息,请参阅javadocs。
这些操作不是分布式的:
- 获取
- 失效
- 本地销毁
- 区域操作
- 过期操作
- 如果
forward-expiration-destroy属性设置为false,则到期销毁。 默认值为false。
使用AsyncEventListener的准则
在使用AsyncEventListener之前,请查看以下准则:
- 如果使用
AsyncEventListener来实现后写缓存侦听器,则代码应检查由于先前的异常而可能已关闭现有数据库连接的可能性。 例如,在catch块中检查Connection.isClosed()并在执行进一步操作之前根据需要重新创建连接。 - 如果在向侦听器实现传递事件时需要保留线程中区域事件的顺序,请使用序列
AsyncEventQueue。 当线程内的事件顺序不重要时,以及处理事件时需要最大吞吐量时,请使用并行队列。 在串行和并行两种情况下,给定键的操作顺序都保留在线程的范围内。 - 您必须在承载要处理其事件的区域的Geode成员上安装
AsyncEventListener实现。 - 如果配置并行
AsyncEventQueue,请在承载该区域的每个Geode成员上部署队列。 - 如果具有活动
AsyncEventListener的成员关闭,您可以在多个成员上安装侦听器以提供高可用性并保证事件的传递。 在任何给定时间,只有一个成员具有用于调度事件的主动侦听器。 其他成员的监听器仍处于备用状态以实现冗余。 为了获得最佳性能和最有效的内存使用,请仅安装一个备用侦听器(最多一个冗余)。 - 出于性能和内存原因,安装不超过一个备用侦听器(最多一个冗余)。
- 要通过成员关闭保留挂起事件,请将Geode配置为将
AsyncEventListener的内部队列持久保存到可用磁盘存储中。 默认情况下,如果活动侦听器的成员关闭,则驻留在AsyncEventListener的内部队列中的任何挂起事件都将丢失。 - 要确保事件的高可用性和可靠传递,请将事件队列配置为持久和冗余。
实现AsyncEventListener
要接收要处理的区域事件,可以创建一个实现AsyncEventListener接口的类。 侦听器中的processEvents方法接收每个批处理中排队的AsyncEvent对象的列表。
每个AsyncEvent对象都包含有关区域事件的信息,例如事件发生的区域的名称,区域操作的类型以及受影响的键和值。
实现后写事件处理程序的基本框架包括迭代批处理事件并将每个事件写入数据库。 例如:
class MyAsyncEventListener implements AsyncEventListener {
public boolean processEvents(List<AsyncEvent> events) {
// Process each AsyncEvent
for(AsyncEvent event: events) {
// Write the event to a database
}
}
}
处理AsyncEvents
使用AsyncEventListener.processEvents方法处理AsyncEvents。 当事件排队等待处理时,将异步调用此方法。 列表的大小反映了在AsyncEventQueueFactory中定义批量大小的批处理事件的数量。 processEventsmethod返回一个布尔值; 如果正确处理了AsyncEvents,则为true;如果任何事件处理失败,则为false。 只要processEvents返回false,Geode就会继续重新尝试处理事件。
您可以使用getDeserializedValue方法获取已更新或创建的条目的缓存值。 由于getDeserializedValue方法将为已销毁的条目返回null值,因此应使用getKey方法获取对已销毁的缓存对象的引用。 这是处理AsyncEvents的示例:
public boolean processEvents(@SuppressWarnings("rawtypes") List<AsyncEvent> list)
{
logger.log (Level.INFO, String.format("Size of List<GatewayEvent> = %s", list.size()));
List<JdbcBatch> newEntries = new ArrayList<JdbcBatch>();
List<JdbcBatch> updatedEntries = new ArrayList<JdbcBatch>();
List<String> destroyedEntries = new ArrayList<String>();
int possibleDuplicates = 0;
for (@SuppressWarnings("rawtypes") AsyncEvent ge: list)
{
if (ge.getPossibleDuplicate())
possibleDuplicates++;
if ( ge.getOperation().equals(Operation.UPDATE))
{
updatedEntries.add((JdbcBatch) ge.getDeserializedValue());
}
else if ( ge.getOperation().equals(Operation.CREATE))
{
newEntries.add((JdbcBatch) ge.getDeserializedValue());
}
else if ( ge.getOperation().equals(Operation.DESTROY))
{
destroyedEntries.add(ge.getKey().toString());
}
}
配置AsyncEventListener
要配置后写高速缓存侦听器,首先要配置异步队列以分派区域事件,然后使用侦听器实现创建队列。 然后,您可以将队列分配给某个区域,以便处理该区域的事件。
步骤
使用侦听器实现的名称配置唯一的
AsyncEventQueue。 您可以选择为并行操作,持久性,批量大小和最大内存大小配置队列。 有关详细信息,请参阅WAN配置 。gfsh配置
gfsh>create async-event-queue --id=sampleQueue --persistent --disk-store=exampleStore --listener=com.myCompany.MyAsyncEventListener --listener-param=url#jdbc:db2:SAMPLE,username#gfeadmin,password#admin1The parameters for this command uses the following syntax:
create async-event-queue --id=value --listener=value [--group=value] [--batch-size=value] [--persistent(=value)?] [--disk-store=value] [--max-queue-memory=value] [--listener-param=value(,value)*]有关更多信息,请参阅create async-event-queue.
cache.xml 配置
<cache> <async-event-queue id="sampleQueue" persistent="true" disk-store-name="exampleStore" parallel="false"> <async-event-listener> <class-name>MyAsyncEventListener</class-name> <parameter name="url"> <string>jdbc:db2:SAMPLE</string> </parameter> <parameter name="username"> <string>gfeadmin</string> </parameter> <parameter name="password"> <string>admin1</string> </parameter> </async-event-listener> </async-event-queue> ... </cache>Java 配置
Cache cache = new CacheFactory().create(); AsyncEventQueueFactory factory = cache.createAsyncEventQueueFactory(); factory.setPersistent(true); factory.setDiskStoreName("exampleStore"); factory.setParallel(false); AsyncEventListener listener = new MyAsyncEventListener(); AsyncEventQueue asyncQueue = factory.create("sampleQueue", listener);如果您使用并行的
AsyncEventQueue,则上面的gfsh示例不需要更改,因为gfsh适用于所有成员。 如果使用cache.xml或Java API来配置AsyncEventQueue,请在将托管该区域的每个Geode成员中重复上述配置。 为每个队列配置使用相同的ID和配置设置。 注意:您可以使用gfsh中提供的群集配置服务确保其他成员使用示例配置。 请参见群集配置服务概述.在托管
AsyncEventQueue的每个Geode成员上,将队列分配给要与AsyncEventListener实现一起使用的每个区域。gfsh 配置
gfsh>create region --name=Customer --async-event-queue-id=sampleQueue请注意,您可以在逗号分隔的列表中的命令行上指定多个队列。
cache.xml 配置
<cache> <region name="Customer"> <region-attributes async-event-queue-ids="sampleQueue"> </region-attributes> </region> ... </cache>Java 配置
RegionFactory rf1 = cache.createRegionFactory(); rf1.addAsyncEventQueue(sampleQueue); Region customer = rf1.create("Customer"); // Assign the queue to multiple regions as needed RegionFactory rf2 = cache.createRegionFactory(); rf2.addAsyncEventQueue(sampleQueue); Region order = rf2.create("Order");使用Java API,您还可以向已创建的区域添加和删除队列:
AttributesMutator mutator = order.getAttributesMutator(); mutator.addAsyncEventQueueId("sampleQueue");有关详细信息,请参阅Geode API文档。
(可选)为队列配置持久性和混合。注意: 如果使用持久数据区域,则必须将AsyncEventQueue配置为持久性。 不支持使用具有持久区域的非持久队列。
(可选)使用配置调度程序线程和事件分发的顺序策略中的说明配置多个调度程序线程和队列的排序策略。
AsyncEventListener从配置有关联的AsyncEventQueue的每个区域接收事件。
如何从事件处理程序回调安全地修改缓存
事件处理程序是同步的。 如果需要更改缓存或从事件处理程序回调执行任何其他分布式操作,请小心避免可能阻止并影响整体系统性能的活动。
在事件处理程序中避免的操作
不要直接从事件处理程序执行任何类型的分布式操作。 Geode是一个高度分布式的系统,许多操作似乎在本地调用分布式操作。
这些是常见的分布式操作,可能会让您陷入麻烦:
- 在事件的区域或任何其他区域调用
Region方法。 - 使用Geode
DetributedLockService。 - 修改区域属性。
- 通过Geode
FunctionService执行一个函数。
为了安全起见,请不要直接从事件处理程序中调用Geode API。 从单独的线程或执行程序中进行所有Geode API调用。
如何基于事件执行分布式操作
如果您需要使用处理程序中的Geode API,请使您的工作与事件处理程序异步。 您可以生成一个单独的线程或使用像java.util.concurrent.Executor接口这样的解决方案。
此示例显示了一个串行执行程序,其中回调创建一个Runnable,可以从队列中拉出并由另一个对象运行。 这保留了事件的顺序。
public void afterCreate(EntryEvent event) {
final Region otherRegion = cache.getRegion("/otherRegion");
final Object key = event.getKey();
final Object val = event.getNewValue();
serialExecutor.execute(new Runnable() {
public void run() {
try {
otherRegion.create(key, val);
}
catch (org.apache.geode.cache.RegionDestroyedException e) {
...
}
catch (org.apache.geode.cache.EntryExistsException e) {
...
}
}
});
}
有关Executor的其他信息,请参阅Oracle Java Web站点上的SerialExecutor示例。
缓存事件处理程序示例
缓存事件处理程序的一些示例。
使用参数声明和加载事件处理程序
这为cache.xml中的区域声明了一个事件处理程序。 处理程序是一个缓存侦听器,旨在将更改传递给DB2数据库。 声明包括侦听器的参数,即数据库路径,用户名和密码。
<region name="exampleRegion">
<region-attributes>
. . .
<cache-listener>
<class-name>JDBCListener</class-name>
<parameter name="url">
<string>jdbc:db2:SAMPLE</string>
</parameter>
<parameter name="username">
<string>gfeadmin</string>
</parameter>
<parameter name="password">
<string>admin1</string>
</parameter>
</cache-listener>
</region-attributes>
</region>
此代码清单显示了cache.xml中声明的JDBCListener的部分实现。 这个监听器实现了Declarable接口。 在缓存中创建条目时,将触发此侦听器的afterCreate回调方法以更新数据库。 这里,cache.xml中提供的监听器属性被传递到Declarable.init方法并用于创建数据库连接。
. . .
public class JDBCListener
extends CacheListenerAdapter
implements Declarable {
public void afterCreate(EntryEvent e) {
. . .
// Initialize the database driver and connection using input parameters
Driver driver = (Driver) Class.forName(DRIVER_NAME).newInstance();
Connection connection =
DriverManager.getConnection(_url, _username, _password);
System.out.println(_connection);
. . .
}
. . .
public void init(Properties props) {
this._url = props.getProperty("url");
this._username = props.getProperty("username");
this._password = props.getProperty("password");
}
}
通过API安装事件处理程序
此清单使用RegionFactory方法addCacheListener定义缓存侦听器。
Region newReg = cache.createRegionFactory()
.addCacheListener(new SimpleCacheListener())
.create(name);
You can create a cache writer similarly, using the RegionFactory method setCacheWriter, like this:
Region newReg = cache.createRegionFactory()
.setCacheWriter(new SimpleCacheWriter())
.create(name);
Installing Multiple Listeners on a Region
XML:
<region name="exampleRegion">
<region-attributes>
. . .
<cache-listener>
<class-name>myCacheListener1</class-name>
</cache-listener>
<cache-listener>
<class-name>myCacheListener2</class-name>
</cache-listener>
<cache-listener>
<class-name>myCacheListener3</class-name>
</cache-listener>
</region-attributes>
</region>
API:
CacheListener listener1 = new myCacheListener1();
CacheListener listener2 = new myCacheListener2();
CacheListener listener3 = new myCacheListener3();
Region nr = cache.createRegionFactory()
.initCacheListeners(new CacheListener[]
{listener1, listener2, listener3})
.setScope(Scope.DISTRIBUTED_NO_ACK)
.create(name);
安装Write-Behind 缓存 监听器
//AsyncEventQueue with listener that performs WBCL work
<cache>
<async-event-queue id="sampleQueue" persistent="true"
disk-store-name="exampleStore" parallel="false">
<async-event-listener>
<class-name>MyAsyncListener</class-name>
<parameter name="url">
<string>jdbc:db2:SAMPLE</string>
</parameter>
<parameter name="username">
<string>gfeadmin</string>
</parameter>
<parameter name="password">
<string>admin1</string>
</parameter>
</async-event-listener>
</async-event-queue>
// Add the AsyncEventQueue to region(s) that use the WBCL
<region name="data">
<region-attributes async-event-queue-ids="sampleQueue">
</region-attributes>
</region>
</cache>
配置点对点事件消息
您可以从集群对等方接收任何非本地区域的事件。 本地区域仅接收本地缓存事件。
对等分发根据区域的配置完成。
复制区域始终从对等方接收所有事件,无需进一步配置。 使用
REPLICATE区域快捷方式设置配置复制区域。对于非复制区域,请确定是要从分布式缓存接收所有条目事件,还是仅接收本地存储的数据的事件。 要配置:
要接收所有事件,请将
subscription-attributesintece-policy设置为all:<region-attributes> <subscription-attributes interest-policy="all"/> </region-attributes>要仅为本地存储的数据接收事件,请将
subscription-attributesinterest-policy设置为cache-content或不设置它(cache-content是默认值):<region-attributes> <subscription-attributes interest-policy="cache-content"/> </region-attributes>
对于分区区域,这仅影响事件的接收,因为数据是根据区域分区存储的。 具有
all的兴趣策略的分区区域可以创建网络瓶颈,因此如果可以,则在托管分区区域数据的每个成员中运行侦听器并使用cache-content兴趣策略。
注意: 您还可以使用gfsh命令行界面配置区域。 参见区域命令.
配置客户端服务器事件消息
您可以从服务器接收服务器端缓存事件和查询结果更改的事件。
对于缓存更新,您可以配置为接收条目键和值,或只是输入键,并在请求时懒惰地检索数据。 查询针对服务器缓存事件持续运行,服务器发送查询结果集的增量。
在开始之前,请设置客户端/服务器安装并配置和编写基本事件消息。
服务器接收客户端客户区域中所有条目事件的更新。
要从服务器接收客户端中的条目事件:
对客户进行编程以注册您所需条目的兴趣。
注意: 这必须通过API完成。
注册对所有键,键列表,单个键或通过将键字符串与正则表达式进行比较的兴趣。 默认情况下,未注册任何条目来接收更新。 指定服务器是否要发送带有条目更新事件的值。 兴趣注册仅通过API提供。
获取您要注册兴趣的区域的实例。
使用区域的
registerInterest*方法指定所需的条目。 例子:// Register interest in a single key and download its entry // at this time, if it is available in the server cache Region region1 = . . . ; region1.registerInterest("key-1"); // Register Interest in a List of Keys but do not do an initial bulk load // do not send values for creater/update events - just send key with invalidation Region region2 = . . . ; List list = new ArrayList(); list.add("key-1"); list.add("key-2"); list.add("key-3"); list.add("key-4"); region2.registerInterestForKeys(list, InterestResultPolicy.NONE, false); // Register interest in all keys and download all available keys now Region region3 = . . . ; region3.registerInterestForAllKeys(InterestResultPolicy.KEYS); // Register Interest in all keys matching a regular expression Region region1 = . . . ; region1.registerInterestRegex("[a-zA-Z]+_[0-9]+");您可以为单个区域多次调用注册兴趣方法。 每个兴趣注册都会添加到服务器的客户注册兴趣标准列表中。 因此,如果客户注册对键'A'的兴趣,然后注册对正则表达式“B*”的兴趣,服务器将发送所有带有键'A'或以字母'B'开头的键的更新。
对于高可用性事件消息,请配置服务器冗余。 请参阅配置高可用性服务器.
要在客户端停机期间为客户端排队事件,请配置持久的客户端/服务器消息传递。
编写要运行的任何连续查询(CQs),以持续接收客户端查询的流式更新。 CQ事件不更新客户端缓存。 如果您在CQ和/或兴趣注册之间存在依赖关系,那么您希望两种类型的订阅事件在客户端上紧密地一起到达,请为所有内容使用单个服务器池。 使用不同的池可能会导致事件传递的时间差异,因为池可能使用不同的服务器来处理和传递事件消息。
配置高可用服务器
- 实施持久的客户端/服务器消息传递
- 调整客户端/服务器事件消息
配置高可用性服务器
使用高可用性服务器,如果客户端的主服务器崩溃,其中一个备份将介入并接管消息,而不会中断服务。
要配置高可用性,请在客户端池配置中设置subscription-redundancy。 此设置指示要使用的辅助服务器的数量。 例如:
<!-- Run one secondary server -->
<pool name="red1" subscription-enabled="true" subscription-redundancy="1">
<locator host="nick" port="41111"/>
<locator host="nora" port="41111"/>
</pool>
<!-- Use all available servers as secondaries. One is primary, the rest are secondaries -->
<pool name="redX" subscription-enabled="true" subscription-redundancy="-1">
<locator host="nick" port="41111"/>
<locator host="nora" port="41111"/>
</pool>
启用冗余后,辅助服务器会在主服务器将事件推送到客户端时维护队列备份。 如果主服务器发生故障,其中一个辅助服务器将作为主服务器进入,以向客户端提供不间断的事件消息传递。
下表描述了subscription-redundancy设置的不同值:
| subscription-redundancy | 描述 |
|---|---|
| 0 | 未配置辅助服务器,因此禁用高可用性。 |
| > 0 | 设置用于备份到主服务器的辅助服务器的精确数量。 |
| -1 | 每个不是主服务器的服务器都将用作辅助服务器。 |
- 高度可用的客户端/服务器事件消息
高度可用的客户端服务器事件消息
使用服务器冗余,每个池都有一个主服务器和一些辅助服务器。 初选和辅助是基于每个池分配的,并且通常分散用于负载平衡,因此具有多个池的单个客户端可以在多个服务器中具有主队列。
主服务器将事件推送到客户端,辅助服务器维护队列备份。 如果主服务器发生故障,其中一个辅助服务器将成为主服务器以提供不间断的事件消息传递。
例如,如果有六台服务器正在运行且subscription-redundancy设置为2,则一台服务器是主服务器,两台服务器是辅助服务器,其余三台服务器不主动参与客户端的HA。 如果主服务器出现故障,系统会将其中一个辅助服务器指定为新主服务器,并尝试将另一个服务器添加到辅助池以保留初始冗余级别。 如果未找到新的辅助服务器,则不满足冗余级别,但故障转移过程成功完成。 只要有另一个辅助辅助设备,就会添加辅助辅助设备。
启用高可用性时:
- 主服务器将事件消息发送到客户端。
- 客户端定期将收到的消息发送到服务器,服务器从队列中删除发送的消息。
- 主服务器定期与其辅助服务器同步,通知它们可以丢弃的消息,因为它们已经被发送和接收。 通知存在延迟,因此辅助服务器仅与主服务器保持大致同步。 辅助队列包含主队列中包含的所有消息以及可能已发送到客户端的一些消息。
- 在主服务器发生故障的情况下,其中一个辅助服务器成为主服务器,并开始从其队列向客户端发送事件消息。 故障转移后,新主服务器通常会重新发送旧主服务器已发送的一些消息。 客户端将这些视为重复项并将其丢弃。
在该图的阶段1中,主设备向客户端发送事件消息,并向其辅助设备发送同步消息。 在阶段2,辅助和客户端已更新其队列和消息跟踪信息。 如果主服务器在第二阶段失败,则辅助服务器将从消息A10开始从其队列开始发送事件消息。 客户端将丢弃重新发送消息A10,然后照常处理后续消息。 
更改服务器队列同步频率
默认情况下,主服务器每秒向辅助节点发送队列同步消息。 您可以使用gfsh alter runtime命令更改此间隔
设置队列同步消息的时间间隔如下:
gfsh:
gfsh>alter runtime --message-sync-interval=2XML:
<!-- Set sync interval to 2 seconds --> <cache ... message-sync-interval="2" />Java:
cache = CacheFactory.create(); cache.setMessageSyncInterval(2);
此间隔的理想设置在很大程度上取决于您的应用程序行为。 这些是更短和更长间隔设置的好处:
- 较短的间隔在辅助服务器中需要较少的内存,因为它减少了同步之间的队列建立。 此外,辅助队列中较少的旧消息意味着在故障转移后减少重新发送的消息。 对于具有高数据更新速率的系统,这些考虑因素最为重要。
- 较长的间隔需要较少的主要和次要之间的分发消息,这有利于整体系统性能。
设置从辅助队列中删除孤立的频率
通常,根据主要的同步消息从辅助订阅队列中删除所有事件消息。 但是,有时候,某些消息在辅助队列中是孤立的。 例如,如果主节点在向其辅助节点发送同步消息的过程中失败,则某些辅助节点可能会收到该消息,而某些辅助节点可能不会。 如果故障转移到达确实收到消息的辅助服务器,则系统将具有包含不再位于主队列中的消息的辅助队列。 新主服务器永远不会在这些消息上同步,将它们孤立在辅助队列中。
为了确保最终删除这些消息,辅助节点使所有已排队的消息超过服务器的message-time-live所指示的时间。
设置生存时间如下:
XML:
<!-- Set message ttl to 5 minutes --> <cache-server port="41414" message-time-to-live="300" />Java:
Cache cache = ...; CacheServer cacheServer = cache.addCacheServer(); cacheServer.setPort(41414); cacheServer.setMessageTimeToLive(200); cacheServer.start();
实施持久的客户端服务器消息传递
即使客户端关闭或断开连接,也需要为客户端维护的订阅使用持久消息传递。 您可以将任何事件订阅配置为持久。 当客户端断开连接时,持久查询和订阅的事件将保存在队列中,并在客户端重新连接时播放。 其他查询和订阅将从队列中删除。
对使用事件订阅的客户端/服务器安装使用持久消息传递。
这些是本主题中描述的高级任务:
- 将您的客户端配置为持久
- 确定哪些订阅应该是持久的并相应地进行配置
- 对客户端进行编程,以管理断开连接,重新连接和事件处理的持久消息传递
将客户端配置为持久
使用以下方法之一:
gemfire.properties文件:durable-client-id=31 durable-client-timeout=200Java:
Properties props = new Properties(); props.setProperty("durable-client-id", "31"); props.setProperty("durable-client-timeout", "" + 200); CacheFactory cf = new CacheFactory(props);
durable-client-id表示客户端是持久的,并为服务器提供一个标识符,用于将客户端与其持久消息相关联。 对于非持久客户端,此id是空字符串。 ID可以是连接到同一群集中的服务器的客户端中唯一的任何数字。
durable-client-timeout告诉服务器等待客户端重新连接多长时间。 达到此超时后,服务器将停止存储到客户端的消息队列并丢弃所有存储的消息。 默认值为300秒。 这是一个调整参数。 如果更改它,请考虑应用程序的正常活动,消息的平均大小以及可以处理的风险级别,包括丢失的消息和服务器存储排队消息的容量。 假设没有消息从队列中删除,服务器在队列达到最大容量之前可以运行多长时间? 服务器可以处理多少持久客户端? 为了协助调整,请通过断开连接和重新连接周期为持久客户端使用Geode消息队列统计信息。
配置持久订阅和连续查询
注册器兴趣和查询创建方法都有一个可选的布尔参数,用于指示持久性。 默认情况下,所有都是非持久的。
// Durable registration
// Define keySpecification, interestResultPolicy, durability
exampleRegion.registerInterest(keySpecification, interestResultPolicySpecification, true);
// Durable CQ
// Define cqName, queryString, cqAttributes, durability
CqQuery myCq = queryService.newCq(cqName, queryString, cqAttributes, true);
通过仅指示关键订阅和CQ的持久性,在客户端断开连接时仅保存关键消息。 当客户端连接到其服务器时,它会接收所有键和已重新注册的查询的消息。 当客户端断开连接时,非持久兴趣注册和CQ将停止,但队列中已存在的所有消息仍然存在。
注意: 对于单个持久客户端ID,您必须在客户端运行之间保持相同的注册和查询持久性。
对客户端进行编程以管理持久消息传递
将持久客户端编程为在断开连接,重新连接和处理来自服务器的事件时具有持久消息感知能力。
通过使用带有布尔值
keepalive参数的Pool.close或ClientCache.close来断开与队列保持活动的请求。clientCache.close(true);要在客户端停机期间保留,必须在断开连接时执行持久连续查询(CQ)。
将持久客户端的重新连接编程为:
如果需要,检测先前注册的订阅队列是否在持久客户端重新连接时可用以及队列中的挂起事件计数。 根据结果,您可以决定是否接收剩余事件,或者如果数字太大则关闭缓存。
例如,对于仅创建了默认池的客户端:
int pendingEvents = cache.getDefaultPool().getPendingEventCount(); if (pendingEvents == -2) { // client connected for the first time … // continue } else if (pendingEvents == -1) { // client reconnected but after the timeout period … // handle possible data loss } else { // pendingEvents >= 0 … // decide to invoke readyForEvents() or ClientCache::close(false)/pool.destroy() }对于具有多个池的客户端:
int pendingEvents = 0; int pendingEvents1 = PoolManager.find(“pool1”).getPendingEventCount(); pendingEvents += (pendingEvents1 > 0) ? pendingEvents1 : 0; int pendingEvents2 = PoolManager.find(“pool2”).getPendingEventCount(); pendingEvents += (pendingEvents2 > 0) ? pendingEvents2 : 0; // process individual pool counts separately.getPendingEventCountAPI可以返回以下可能的值:- 表示服务器上待处理事件计数的值。 请注意,此计数是基于持久客户端池连接或重新连接到服务器的时间的近似值。 任意数量的调用都将返回相同的值。
- 如果此服务器池的服务器上没有待处理事件,则为零值
- 负值表示服务器上没有可用于客户端池的队列。
-1表示客户端池在持久性客户端超时期限过后已重新连接到服务器。 池的订阅队列已被删除,可能导致数据丢失。- 值
-2表示此客户端池第一次连接到服务器。
连接,初始化客户端缓存,区域和任何缓存侦听器,并创建和执行任何持久的连续查询。
运行所有兴趣注册调用。
注意: 使用
InterestResultPolicy.KEYS_VALUES注册兴趣会使用指定键的current值初始化客户端缓存。 如果为区域启用了并发检查,则会忽略重播到客户端的任何早期(较旧)区域事件,并且不会将其发送到已配置的侦听器。 如果您的客户端必须处理区域的所有重播事件,请在重新连接时注册InterestResultPolicy.KEYS或InterestResultPolicy.NONE。 或者,禁用客户端缓存中区域的并发检查。 请参阅区域更新的一致性.调用
ClientCache.readyForEvents,以便服务器重放存储的事件。 如果先前发送就绪消息,则客户端可能会丢失事件。
ClientCache clientCache = ClientCacheFactory.create(); // Here, create regions, listeners that are not defined in the cache.xml . . . // Here, run all register interest calls before doing anything else clientCache.readyForEvents();编写持久客户端
CacheListener时:- 实现回调方法,以便在重放存储的事件时正常运行。 持久客户端的
CacheListener必须能够处理事后播放的事件。 通常,侦听器在事件发生时接收非常接近的事件,但持久客户端可能会接收事件发生在几分钟之前并且与当前缓存状态无关的事件。 - 考虑是否使用
CacheListener回调方法afterRegionLive,它专门用于持久事件重放的结束。 您可以在恢复正常事件处理之前使用它来执行特定于应用程序的操作。 如果您不希望使用此回调,并且您的侦听器是CacheListener(而不是CacheListenerAdapter)的实例,则将afterRegionLive实现为空方法。
- 实现回调方法,以便在重放存储的事件时正常运行。 持久客户端的
初步操作
持久客户端的初始启动类似于任何其他客户端的启动,除了当客户端上的所有区域和侦听器都准备好处理来自服务器的消息时,它专门调用ClientCache.readyForEvents方法。
断开
客户端和服务器断开连接时,其操作会根据具体情况而有所不同。
- 正常断开. 当客户端关闭其连接时,服务器停止向客户端发送消息并释放其连接。 如果客户端请求它,则服务器会维护队列和持久兴趣列表信息,直到客户端重新连接或超时。 非持久兴趣列表将被丢弃。 服务器继续为持久兴趣列表上的条目排队传入消息。 客户端断开连接时队列中的所有消息都保留在队列中。 如果客户端请求不维护其订阅,或者没有持久订阅,则服务器取消注册客户端并执行与非持久客户端相同的清理。
- 异常断开. 如果客户端崩溃或丢失与所有服务器的连接,则服务器会自动维护其消息队列和持久订阅,直到它重新连接或超时。
- 客户断开但运营正常. 如果客户端在断开连接时运行,它将从本地客户端缓存中获取数据。 由于不允许更新,因此数据可能会过时。 如果尝试更新,则会发生
UnconnectedException。 - 客户端在超时期限内保持断开状. 服务器根据
durable-client-timeout设置跟踪保持持久订阅队列活动的时间。 如果客户端保持断开连接的时间超过超时,则服务器将注销客户端并执行为非持久客户端执行的相同清理。 服务器还会记录警报。 当超时客户端重新连接时,服务器将其视为新客户端进行初始连接。
重新连接
在初始化期间,不会阻止客户端缓存执行操作,因此您可能会在更多当前事件更新客户端缓存的同时从服务器接收旧的存储事件。 这些是可以同时作用于缓存的事情:
- 服务器返回的结果以响应客户的兴趣注册。
- 应用程序的客户端缓存操作。
- 通过从队列重放旧事件触发的回调
Geode处理应用程序和兴趣注册之间的冲突,因此它们不会创建缓存更新冲突。 但是您必须对事件处理程序进行编程,以使它们不与当前操作冲突。 这适用于所有事件处理程序,但对于持久客户端中使用的那些事件尤为重要。 您的处理程序可能会在事后很好地接收事件,您必须确保您的编程考虑到这一点。
该图显示了初始化过程中的三个并发过程。 应用程序立即在客户端上开始操作(步骤1),而客户端的缓存就绪消息(也是步骤1)在服务器上触发一系列队列操作(从主服务器上的步骤2开始)。 同时,客户端注册兴趣(客户端上的步骤2)并从服务器接收响应。 消息B2适用于区域A中的条目,因此缓存侦听器处理B2的事件。 由于B2位于标记之前,因此客户端不会将更新应用于缓存。
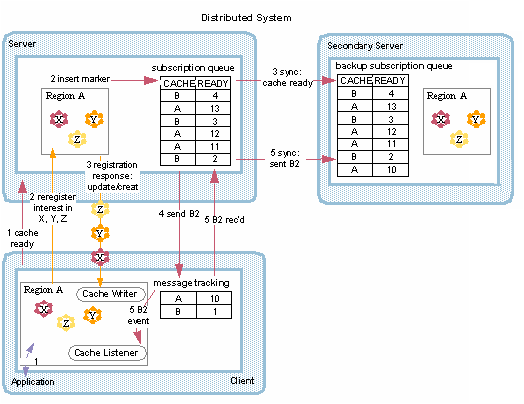
持久的事件重播
当持久客户端在超时期限之前重新连接时,服务器会重放客户端消失时存储的事件,然后将正常的事件消息传递回客户端。 为避免使用旧数据覆盖当前条目,存储的事件不会应用于客户端缓存。 通过在重放所有旧事件后发送到客户端的标记将存储事件与新正常事件区分开。
- 当客户端重新连接时,具有此客户端队列的所有服务器都会在其队列中放置标记。
- 主服务器将排队的消息发送到客户端,直到标记。
- 客户端接收消息但不对其高速缓存应用通常的自动更新。 如果安装了缓存侦听器,它们将处理事件。
- 客户端接收标记消息,指示已经播放了所有过去的事件。
- 服务器发送当前活动区域列表。
- 对于客户端上每个活动区域中的每个
CacheListener,标记事件触发afterRegionLive回调。 在回调之后,客户端开始从服务器正常处理事件并将更新应用于其缓存。
即使新客户端第一次启动,客户端缓存就绪标记也会插入队列中。 如果消息在服务器插入标记之前开始进入新队列,则在客户端断开连接时会认为这些消息已发生,并且它们的事件的重放方式与重新连接情况相同。
兴趣注册期间的申请操作
应用程序操作优先于兴趣注册响应。 客户端可以在收到其兴趣注册响应时执行操作。 将注册兴趣响应添加到客户端缓存时,将应用以下规则:
- 如果条目已存在于具有有效值的缓存中,则不会更新。
- 如果条目无效,并且寄存器兴趣响应有效,则将有效值放入缓存中。
- 如果条目被标记为已销毁,则不会更新。 在注册兴趣响应完成后,将从系统中删除被破坏的条目。
- 如果兴趣响应不包含任何结果,因为服务器缓存中不存在所有这些键,则客户端的缓存可以从空开始。 如果队列包含与这些键相关的旧消息,则事件仍在客户端的缓存中重播。
调整客户端服务器事件消息
服务器使用异步消息传递队列将事件发送到其客户端。 队列中的每个事件都源自客户端,服务器中的线程或服务器或某个其他集群中的应用程序执行的操作。 事件消息具有唯一标识符,该标识符由始发线程的ID与其成员的分布式系统成员ID以及操作的顺序ID组成。 因此,源自任何单个线程的事件消息可以按时间从最低序列ID到最高序列进行分组和排序。 服务器和客户端跟踪每个成员线程ID的最高顺序ID。
单个客户端线程接收并处理来自服务器的消息,跟踪收到的消息以确保它不处理重复发送。 它使用来自原始线程的进程ID来完成此操作。

客户端的消息跟踪列表保存为每个始发线程接收的任何消息的最高序列ID。 在有许多不同线程进出并在缓存上工作的系统中,该列表可能变得非常大。 线程死亡后,不需要跟踪条目。 为了避免维护已经死亡的线程的跟踪信息,客户端会使没有活动的条目超过subscription-message-tracking-timeout。
- 配置服务器订阅队列
- 限制服务器的订阅队列内存使用
- 调整客户端的订阅邮件跟踪超时
配置服务器订阅队列
配置服务器订阅队列可以节省服务器空间和消息处理时间。
在服务器区域配置中的服务器级别启用协调:
<region ... >
<region-attributes enable-subscription-conflation="true" />
</region>
根据需要,在客户端的gemfire.properties中覆盖服务器设置:
conflate-events=false
有效的conflate-events设置是: - server,它使用服务器设置 - true,它将发送给客户端的所有内容混为一起 - false,它不会混淆发送给该客户端的任何内容
通过配置可以提高性能并减少服务器上排队所需的内存量。 客户端仅接收队列中针对特定条目键的最新可用更新。 默认情况下禁用配置。
当经常更新单个条目并且中间更新不需要客户端处理时,配置特别有用。 通过合并,如果条目已更新且队列中已存在其键更新,则会删除现有更新,并将新更新置于队列末尾。 仅在未发送到客户端的消息上进行协调。
注意: 这种合并方法与用于多站点网关发送方队列合并的方法不同。 它与用于在单个集群内合并对等分发消息的方法相同。
限制服务器的订阅队列内存使用
这些是用于限制订阅队列消耗的服务器内存量的选项。
可选的: 合并订阅队列消息。
可选的: 增加队列同步的频率。 这仅适用于将服务器冗余用于高可用性的配置。 增加客户端的池配置,
subscription-ack-interval。 客户端定期向服务器发送批量消息确认,而不是单独确认每条消息。 较低的设置可以加快邮件传递速度,并且通常可以减少服 较高的设置有助于包含服务器队列大小。 例:<!-- Set subscription ack interval to 3 seconds --> <cache> <pool ... subscription-enabled="true" subscription-ack-interval="3000"> ... </pool>如果您的系统非常繁忙,并且希望减少订阅队列服务器所需的空间,则可能需要降低时间间隔。 更频繁的确认意味着等待确认的服务器队列中保存的事件更少。
可选的: 限制队列大小。 使用溢出或阻塞来限制服务器队列大小。 这些选项有助于避免在客户端较慢的情况下服务器上出现内存不足错误。 慢速客户端会降低服务器发送消息的速率,从而导致消息在队列中备份,从而可能导致服务器内存不足。 您可以使用这些选项中的一个或另一个,但不能同时使用两者:
可选的: 溢出到磁盘。 通过设置服务器的
client-subscription属性来配置订阅队列溢出。 通过溢出,最近使用的(MRU)事件被写入磁盘,保留最旧的事件,即下一行发送到客户端的事件,在内存中可用。 例:<!-- Set overflow after 10K messages are enqueued --> <cache-server port="40404"> <client-subscription eviction-policy="entry" capacity="10000" disk-store-name="svrOverflow"/> </cache-server>可选的: 队列满时阻止。 将服务器的
maximum-message-count设置为阻止传入消息之前任何单个订阅队列中允许的最大事件消息数。 您只能限制消息计数,而不是为消息分配的大小。 例子:XML:
<!-- Set the maximum message count to 50000 entries --> <cache-server port="41414" maximum-message-count="50000" />API:
Cache cache = ...; CacheServer cacheServer = cache.addCacheServer(); cacheServer.setPort(41414); cacheServer.setMaximumMessageCount(50000); cacheServer.start();注意: 使用此设置,一个慢速客户端可以减慢服务器及其所有其他客户端的速度,因为这会阻止写入队列的线程。 将消息添加到队列块的所有操作,直到队列大小降至可接受的水平。 如果为这些队列提供的区域被分区或具有
distributed-ack或global范围,则对它们的操作将保持阻塞状态,直到它们的事件消息可以添加到队列中。 如果您使用此选项并且看到服务器区域操作停滞,则您的队列容量可能太低而不适合您的应用程序行为。
调整客户端的订阅消息跟踪超时
如果客户端池的subscription-message-tracking-timeout设置得太低,您的客户端将丢弃实时线程的跟踪记录,从而增加处理来自这些线程的重复事件的可能性。
此设置对于避免或大大减少重复事件至关重要的系统尤其重要。 如果您检测到客户端正在处理重复的消息,则增加超时可能会有所帮助。 设置subscription-message-tracking-timeout可能无法完全消除重复条目,但仔细配置可以帮助最小化出现次数。
通过跟踪来自操作源的源线程的消息序列ID来监视重复项。 对于长时间运行的系统,您不希望长时间跟踪此信息,或者信息可能保留足够长的时间以便回收线程ID。 如果发生这种情况,来自新线程的消息可能被错误地丢弃为来自具有相同ID的旧线程的消息的重复。 此外,为旧线程维护此跟踪信息会使用可能为其他事物释放的内存。
要最大限度地减少重复项并减小邮件跟踪列表的大小,请将客户端subscription-message-tracking-timeout设置为高于这些时间总和的两倍:
- 原始线程可能在操作之间等待的最长时间
- 对于冗余服务器添加:
- 服务器的
message-sync-interval - 故障转移所需的总时间(通常为7-10秒,包括检测故障的时间)
- 服务器的
如果将值设置为低于此值,则可能会丢失活动线程跟踪记录。 这可能导致客户端将重复的事件消息处理到其关联线程的高速缓存中。 值得努力将subscription-message-tracking-timeout设置为合理的最低值。
<!-- Set the tracking timeout to 70 seconds -->
<pool name="client" subscription-enabled="true" subscription-message-tracking-timeout="70000">
...
</pool>
配置多站点(WAN)事件队列
在多站点(WAN)安装中,Geode使用网关发件人队列来分配使用网关发件人配置的区域的事件。 AsyncEventListeners还使用异步事件队列来分配已配置区域的事件。 本节介绍用于配置网关发件人或AsyncEventListener实现使用的事件队列的其他选项。
在开始之前,请设置多站点(WAN)安装或配置异步事件队列和AsyncEventListener实现。 请参阅配置多站点(WAN)系统 或为后写缓存事件实现AsyncEventListener处理。
持久化事件队列
您可以配置网关发件人队列或异步事件队列以将数据持久保存到磁盘,类似于复制区域的持久方式。
为事件分发配置Dispatcher线程和顺序策略
默认情况下,Geode使用多个调度程序线程在网关发送方队列中同时处理区域事件,以便在站点之间进行分配,或者在异步事件队列中用于分发事务以进行后写式高速缓存。 使用串行队列,您还可以配置用于分派这些事件的排序策略。
配置队列中的事件
配置队列可提高分发性能。 启用合并后,仅为特定键发送最新排队值。
持久化事件队列
您可以配置网关发件人队列或异步事件队列以将数据持久保存到磁盘,类似于复制区域的持久方式。
保留队列可为发件人执行的事件消息传递提供高可用性。 例如,如果持久网关发送方队列因任何原因退出,则当承载发送方的成员重新启动它时,它会自动重新加载队列并继续发送消息。 如果异步事件队列因任何原因退出,则回写缓存可以在队列重新联机时从中断处继续。 如果将enable-persistence属性设置为true,Geode会持久保存事件队列。 队列将持久保存到队列的disk-store-name属性中指定的磁盘存储区,如果未指定存储名称,则保留到默认磁盘存储区。
如果使用持久性区域,则必须将事件队列配置为使用持久性。 不支持使用具有持久区域的非持久性事件队列。
为队列启用持久性时,maximum-queue-memory属性确定队列在溢出到磁盘之前可以消耗多少内存。 默认情况下,此值设置为100MB。
注意: 如果配置并行队列和/或为队列配置多个调度程序线程,则maximum-queue-memory和disk-store-name属性中定义的值将应用于队列的每个实例。
在下面的示例中,网关发送方队列使用“diskStoreA”进行持久性和溢出,并且队列的最大队列内存为100MB:
XML 例子:
<cache> <gateway-sender id="persistedsender1" parallel="false" remote-distributed-system-id="1" enable-persistence="true" disk-store-name="diskStoreA" maximum-queue-memory="100"/> ... </cache>API 例子:
Cache cache = new CacheFactory().create(); GatewaySenderFactory gateway = cache.createGatewaySenderFactory(); gateway.setParallel(false); gateway.setPersistenceEnabled(true); gateway.setDiskStoreName("diskStoreA"); gateway.setMaximumQueueMemory(100); GatewaySender sender = gateway.create("persistedsender1", "1"); sender.start();gfsh:
gfsh>create gateway-sender --id="persistedsender1 --parallel=false --remote-distributed-system-id=1 --enable-persistence=true --disk-store-name=diskStoreA --maximum-queue-memory=100
如果要为串行网关发送方配置10个调度程序线程,则每个承载发送方的Geode成员的网关发送方队列的总最大内存为1000MB,因为Geode会为每个线程创建一个单独的队列副本。
以下示例显示了异步事件队列的类似配置:
XML 例子:
<cache> <async-event-queue id="persistentAsyncQueue" persistent="true" disk-store-name="diskStoreA" parallel="true"> <async-event-listener> <class-name>MyAsyncEventListener</class-name> <parameter name="url"> <string>jdbc:db2:SAMPLE</string> </parameter> <parameter name="username"> <string>gfeadmin</string> </parameter> <parameter name="password"> <string>admin1</string> </parameter> </async-event-listener> </async-event-queue> ... </cache>API 例子:
Cache cache = new CacheFactory().create(); AsyncEventQueueFactory factory = cache.createAsyncEventQueueFactory(); factory.setPersistent(true); factory.setDiskStoreName("diskStoreA"); factory.setParallel(true); AsyncEventListener listener = new MyAsyncEventListener(); AsyncEventQueue persistentAsyncQueue = factory.create("customerWB", listener);gfsh:
gfsh>create async-event-queue --id="persistentAsyncQueue" --persistent=true --disk-store="diskStoreA" --parallel=true --listener=MyAsyncEventListener --listener-param=url#jdbc:db2:SAMPLE --listener-param=username#gfeadmin --listener-param=password#admin1
为事件分发配置Dispatcher线程和顺序策略
默认情况下,Geode使用多个调度程序线程在网关发送方队列中同时处理区域事件,以便在站点之间进行分配,或者在异步事件队列中用于分发事务以进行后写式高速缓存。 使用串行队列,您还可以配置用于分派这些事件的排序策略。
默认情况下,网关发送方队列或异步事件队列每个队列使用5个调度程序线程。 这为那些能够同时处理排队事件以便分发给另一个Geode站点或监听器的应用程序提供支持。 如果您的应用程序不需要并发分发,或者您没有足够的资源来支持多个调度程序线程的要求,那么您可以配置单个调度程序线程来处理队列。
使用多个Dispatcher线程来处理队列
当为并行队列配置多个调度程序线程时,Geode只使用多个线程来处理每个单独队列的内容。 创建的队列总数仍由托管该区域的Geode成员数决定。
为串行队列配置多个调度程序线程时,Geode会为承载队列的每个成员上的每个线程创建一个队列的附加副本。 要获得最大吞吐量,请增加调度程序线程数,直到网络饱和为止。
下图说明了使用多个调度程序线程配置的串行网关发送方队列。 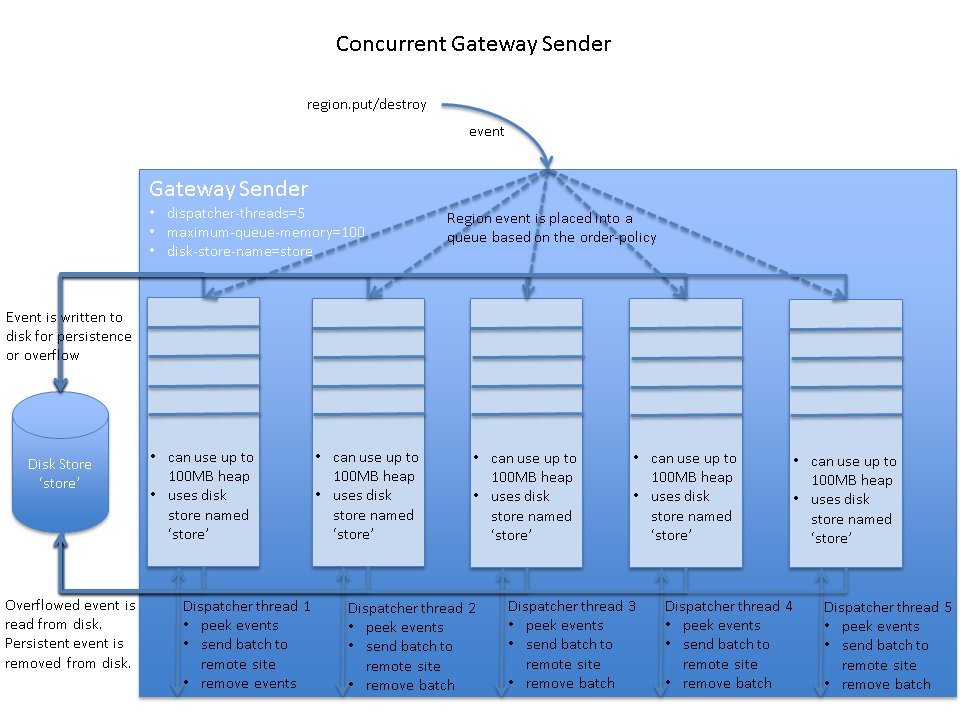
性能和内存注意事项
当串行网关发送方或异步事件队列使用多个调度程序线程时,请考虑以下事项:
- 对于为调度程序线程创建的队列的每个副本,都会重复队列属性。 也就是说,每个并发队列指向同一磁盘存储,因此使用相同的磁盘目录。 如果启用了持久性并发生溢出,则将条目插入队列的线程将竞争磁盘。 这适用于应用程序线程和调度程序线程,因此它可能会影响应用程序性能。
maximum-queue-memory设置适用于串行队列的每个副本。 如果配置10个调度程序线程并且最大队列内存设置为100MB,则队列队列的每个成员上队列的总最大队列内存为1000MB。
配置串行队列的排序策略
当使用带有串行事件队列的多个dispatcher-threads(大于1)时,您还可以配置这些线程用于从队列分发事件的order-policy。 有效的排队策略值为:
- key (default). 对同一key的所有更新都按顺序分发。 Geode通过将相同key的所有更新放在同一个调度程序线程队列中来保留key排序。 当条目更新彼此没有关系时,通常使用key排序,例如对于使用单个馈送器将库存更新分发给其他几个系统的应用程序。
- thread. 来自给定线程的所有区域更新按顺序分布。 Geode通过将来自同一线程的所有区域更新放入同一个调度程序线程队列来保留线程排序。 通常,当对一个区域条目的更新影响对另一个区域条目的更新时,请使用线程排序。
- partition. 共享相同分区键的所有区域事件按顺序分布。 当应用程序使用PartitionResolver实现自定义分区时,指定分区顺序。 使用分区排序,共享相同“分区键”(RoutingObject)的所有条目都放在同一个调度程序线程队列中。
您无法为并行事件队列配置order-policy,因为并行队列无法保留区域的事件排序。 只能保留给定分区(或分布式区域的给定队列)中事件的顺序。
示例 - 为串行网关发送器队列配置Dispatcher线程和排序策略
要增加调度程序线程数并为串行网关发送方设置排序策略,请使用以下机制之一。
cache.xml 配置
<cache> <gateway-sender id="NY" parallel="false" remote-distributed-system-id="1" enable-persistence="true" disk-store-name="gateway-disk-store" maximum-queue-memory="200" dispatcher-threads=7 order-policy="key"/> ... </cache>Java API 配置
Cache cache = new CacheFactory().create(); GatewaySenderFactory gateway = cache.createGatewaySenderFactory(); gateway.setParallel(false); gateway.setPersistenceEnabled(true); gateway.setDiskStoreName("gateway-disk-store"); gateway.setMaximumQueueMemory(200); gateway.setDispatcherThreads(7); gateway.setOrderPolicy(OrderPolicy.KEY); GatewaySender sender = gateway.create("NY", "1"); sender.start();gfsh:
gfsh>create gateway-sender -d="NY" --parallel=false --remote-distributed-system-id="1" --enable-persistence=true --disk-store-name="gateway-disk-store" --maximum-queue-memory=200 --dispatcher-threads=7 --order-policy="key"
以下示例显示如何为异步事件队列设置调度程序线程和排序策略:
cache.xml 配置
<cache> <async-event-queue id="sampleQueue" persistent="true" disk-store-name="async-disk-store" parallel="false" dispatcher-threads=7 order-policy="key"> <async-event-listener> <class-name>MyAsyncEventListener</class-name> <parameter name="url"> <string>jdbc:db2:SAMPLE</string> </parameter> <parameter name="username"> <string>gfeadmin</string> </parameter> <parameter name="password"> <string>admin1</string> </parameter> </async-event-listener> </async-event-queue> ... </cache>Java API 配置
Cache cache = new CacheFactory().create(); AsyncEventQueueFactory factory = cache.createAsyncEventQueueFactory(); factory.setPersistent(true); factory.setDiskStoreName("async-disk-store"); factory.setParallel(false); factory.setDispatcherThreads(7); factory.setOrderPolicy(OrderPolicy.KEY); AsyncEventListener listener = new MyAsyncEventListener(); AsyncEventQueue sampleQueue = factory.create("customerWB", listener);Entry updates in the current, in-process batch are not eligible for conflation.
gfsh:
gfsh>create async-event-queue --id="sampleQueue" --persistent=true --disk-store="async-disk-store" --parallel=false --dispatcher-threads=7 order-policy="key" --listener=myAsycEventListener --listener-param=url#jdbc:db2:SAMPLE --listener-param=username#gfeadmin --listener-param=password#admin1
合并队列中的事件
配置队列可提高分发性能。 启用合并后,仅为特定key发送最新排队值。
注意: 如果您的接收应用程序依赖于条目修改的特定顺序,或者如果需要通知他们对条目的每次更改,请不要使用合并。
当频繁更新单个条目时,合并最有用,但其他站点只需要知道条目的当前值(而不是每个更新的值)。 将更新添加到启用了混淆的队列时,如果条目队列中已存在更新消息,则现有消息将采用新更新的值并删除新更新,如下所示 键A.
注意: 这种合并方法不同于用于服务器到客户端订阅队列协调和群集内对等分发的方法。
示例 - 为网关发件人队列配置合并
要为网关发件人队列启用合并,请使用以下机制之一:
cache.xml 配置
<cache> <gateway-sender id="NY" parallel="true" remote-distributed-system-id="1" enable-persistence="true" disk-store-name="gateway-disk-store" enable-batch-conflation="true"/> ... </cache>Java API 配置
Cache cache = new CacheFactory().create(); GatewaySenderFactory gateway = cache.createGatewaySenderFactory(); gateway.setParallel(true); gateway.setPersistenceEnabled(true); gateway.setDiskStoreName("gateway-disk-store"); gateway.setBatchConflationEnabled(true); GatewaySender sender = gateway.create("NY", "1"); sender.start();当前进程中批处理中的条目更新不符合合并条件。
gfsh:
gfsh>create gateway-sender --id="NY" --parallel=true --remote-distributed-system-id="1" --enable-persistence=true --disk-store-name="gateway-disk-store" --enable-batch-conflation=true
以下示例显示如何为异步事件队列配置conflation:
cache.xml 配置
<cache> <async-event-queue id="sampleQueue" persistent="true" disk-store-name="async-disk-store" parallel="false" enable-batch-conflation="true"> <async-event-listener> <class-name>MyAsyncEventListener</class-name> <parameter name="url"> <string>jdbc:db2:SAMPLE</string> </parameter> <parameter name="username"> <string>gfeadmin</string> </parameter> <parameter name="password"> <string>admin1</string> </parameter> </async-event-listener> </async-event-queue> ... </cache>Java API 配置
Cache cache = new CacheFactory().create(); AsyncEventQueueFactory factory = cache.createAsyncEventQueueFactory(); factory.setPersistent(true); factory.setDiskStoreName("async-disk-store"); factory.setParallel(false); factory.setBatchConflationEnabled(true); AsyncEventListener listener = new MyAsyncEventListener(); AsyncEventQueue sampleQueue = factory.create("customerWB", listener);当前进程中批处理中的条目更新不符合合并条件。
gfsh:
gfsh>create async-event-queue --id="sampleQueue" --persistent=true --disk-store="async-disk-store" --parallel="false" --listener=myAsyncEventListener --listener-param=url#jdbc:db2:SAMPLE --listener-param=username#gfeadmin --listener-param=password#admin1
增量传播
增量传播允许您通过仅包括对象而不是整个对象的更改来减少通过网络发送的数据量。
增量传播如何工作
增量传播减少了您通过网络发送的数据量。 您只需发送有关对象的更改或增量信息,而不是发送整个更改的对象。 如果在应用增量时不使用克隆,则还可以期望在接收JVM中生成更少的垃圾。
何时避免增量传播
通常,对象越大,增量越小,使用增量传播的好处就越大。 具有较高冗余级别的分区区域通常受益于增量传播。 但是,在某些应用场景中,增量传播并未显示任何显着优势。 有时它会导致性能下降。
增量传播属性
本主题描述可用于配置增量传播的属性。
实施增量传播
默认情况下,集群中启用了增量传播。 启用时,增量传播用于实现
org.apache.geode.Delta的对象。 您可以对方法进行编程,以存储和提取条目的增量信息,并应用收到的增量信息。增量传播中的错误
本主题列出了使用增量传播时可能发生的错误。
增量传播示例
本主题提供了增量传播的示例。
增量传播如何工作
增量传播减少了您通过网络发送的数据量。 您只需发送有关对象的更改或增量信息,而不是发送整个更改的对象。 如果在应用增量时不使用克隆,则还可以期望在接收JVM中生成更少的垃圾。
在大多数分布式数据管理系统中,存储在系统中的数据往往会被创建一次,然后经常更新。 这些更新通常会发送给其他成员,以实现事件传播,冗余管理和缓存一致性。 仅跟踪更新对象中的更改并仅发送增量意味着更低的网络传输成本和更低的对象序列化/反序列化成本。 性能改进可能很重要,尤其是当对象的更改相对于其整体大小较小时。
Geode使用您编程的方法传播对象增量。 这些方法位于Delta接口中,您可以在缓存对象的类中实现。 如果您的任何类是普通的旧Java对象,则需要将它们包装为此实现。
此图显示了使用键,k和值对象v更改条目的增量传播。
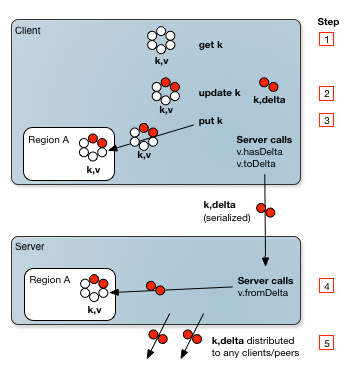
- get 操作.
get像往常一样工作:缓存从本地缓存返回完整的条目对象,如果在那里不可用,则从远程缓存或加载器返回。 - update 方法. 您需要向对象的更新方法添加代码,以便除了已经完成的工作外,还可以保存对象更新的增量信息。
- put 操作.
put在本地缓存中照常工作,使用完整值,然后调用hasDelta查看是否有增量和toDelta来序列化信息。 根据成员和区域配置,分配与完整值相同。 - 收到远程成员的delta.
fromDelta提取由toDelta序列化的delta信息,并将其应用于本地缓存中的对象。 增量将直接应用于现有值或克隆,具体取决于您为区域配置它的方式。 - 额外的分布式. 与完整分布式一样,接收成员根据其配置和与其他成员的连接转发增量。 例如,如果VM1是客户端而VM2是服务器,则VM2根据需要将增量转发给其对等端及其他客户端。 接收成员不会重新创建增量;
toDelta只在原始成员中调用。
增量传播的一般特征
要使用增量传播功能,区域中键的所有更新都必须具有实现Delta接口的值类型。 您不能为某些类型实现delta的条目键混合对象类型,而有些类型则不能。 这是因为,当接收到实现增量接口的类型以进行更新时,将键的现有值强制转换为Delta类型以应用接收的增量。 如果现有类型也没有实现Delta接口,则操作会抛出ClassCastException。
注意: 只有放置在缓存中的对象本身才能实现Delta接口并传播更改。 缓存对象的任何子对象都不会传播其更改。
有时fromDelta无法调用,因为没有对象将delta应用于接收缓存。 发生这种情况时,系统会自动对接收器进行完整的值分配。 以下是可能的情况:1。如果系统可以事先确定接收方没有本地副本,则会发送带有完整值的初始消息。 当区域配置为没有本地数据存储时,例如区域快捷方式设置为PARTITION_PROXY和REPLICATE_PROXY,这是可能的。 这些配置用于完成诸如向侦听器提供数据更新信息以及将更新传递给客户端之类的事情。 2.在不太明显的情况下,例如当一个条目被本地删除时,首先发送增量,然后接收方请求一个完整的值并发送。 每当收到完整值时,对接收者的对等体或客户端的任何进一步分发都使用完整值。
Geode也不会传播增量:
- 事务提交
putAll操作- 运行不支持增量传播的Geode版本的JVM(6.0及更早版本)
支持的拓扑和限制
以下拓扑支持增量传播(有一些限制):
Peer-to-peer(点对点)
. Geode系统成员使用delta传播来分发和接收条目更改,具有以下要求和注意事项:
- 必须对区域进行分区或将其范围设置为
distributed-ack或global。 分布式区域的区域快捷方式设置使用distributed-ack``范围。 Delta传播对于具有`distributed-no-ack``范围的区域不起作用,因为如果在应用delta时发生异常,则接收器无法恢复。 - 对于分区区域,如果接收对等方未保留条目的主副本或副本,但仍需要值,则系统会自动发送完整值。
- 要接收增量,区域必须是非空的。 系统自动将完整值发送到空白区域。 空区域可以发送增量。
- 必须对区域进行分区或将其范围设置为
Client/server(客户端/服务器)
. Geode客户端总是可以向服务器发送增量,服务器通常可以向客户端发送增量。 这些配置要求服务器将完整值发送到客户端,而不是增量:
- 当客户端的
gemfire.properties设置conflate-events设置为true时,服务器会为所有区域发送完整值。 - 当服务器区域属性
enable-subscription-conflation设置为true并且客户端gemfire.properties设置conflate-events设置为server时,服务器会发送该区域的完整值。 - 当客户端区域配置了
PROXY客户端区域快捷方式设置(空客户端区域)时,服务器将发送完整值。
- 当客户端的
多站点(WAN). 网关发件人不发送Deltas。 始终发送完整值。
何时避免增量传播
通常,对象越大,增量越小,使用增量传播的好处就越大。 具有较高冗余级别的分区区域通常受益于增量传播。 但是,在某些应用场景中,增量传播并未显示任何显着优势。 有时它会导致性能下降。
默认情况下,集群中启用了增量传播。
这些是可能降低使用增量传播的性能优势的主要因素:
- 反序列化对象以增加应用增量的成本。 应用增量需要反序列化条目值。 完成此操作后,对象将以反序列化的形式存储在缓存中。 如果由于其他原因(例如索引和查询或侦听器操作)尚未对对象进行反序列化,则delta传播的这一方面仅会对您的系统产生负面影响。 一旦以反序列化的形式存储,就会有将对象发送到成员之外的操作的重新编码成本,例如来自网关发送者的分发,响应于
netSearch或客户端请求而发送的值以及存储到磁盘。 需要重新编译的操作越多,反序列化对象的开销就越高。 与所有序列化工作一样,您可以通过为对象提供DataSerializable的自定义实现来提高序列化和反序列化的性能。 - 应用delta时克隆。 使用克隆会影响性能并产生额外的垃圾。 但是,不使用克隆是有风险的,因为您正在修改缓存值。 如果没有克隆,请确保同步您的条目访问权限以防止缓存变得不一致。
- 应用delta的问题导致系统返回到发起者的完整条目值。 发生这种情况时,整体操作的成本高于首先发送完整的条目值。 如果将delta发送给多个收件人,其中全部或大部分请求完整值,并且完整值发送需要将对象序列化,则可能会进一步加剧这种情况。
- 与溢出区域相关的磁盘I / O开销。 如果使用带有溢出到磁盘的驱逐,则必须将磁盘上的值带入内存才能应用增量。 这比仅删除对磁盘副本的引用要昂贵得多,就像对缓存中的完整值分配一样。
增量传播属性
本主题描述可用于配置增量传播的属性。
增量传播属性可以通过API和gemfire.properties和cache.xml文件进行配置。
delta-propagation(增量传播)
一个gemfire.properties布尔值,用于启用或禁用增量传播。 如果为false,则为每次更新发送完整的条目值。 默认设置为true,启用增量传播。
禁用增量传播如下:
gemfire.properties:delta-propagation=falseAPI:
Properties props = new Properties(); props.setProperty("delta-propagation", false); this.cache = new ClientCacheFactory(props).create();
cloning-enabled(启用克隆)
区域属性boolean影响fromDelta如何将增量应用于本地缓存。 如果为true,则将更新应用于值的克隆,然后将克隆保存到缓存中。 如果为false,则在缓存中就地修改该值。 默认值为false。
此行为的例外情况:
- 如果
Cache属性copy-on-read为true,则启用克隆,无论该属性设置为什么。 - 如果
Region属性off-heap为true,则启用克隆,无论此属性设置为什么。
克隆可能很昂贵,但它确保在任何应用程序代码看到之前,使用delta完全初始化新对象。
启用克隆后,默认情况下,Geode使用序列化对对象执行深层复制。 您可以通过实现java.lang.Cloneable然后实现clone方法来提高性能,对可以应用delta的任何内容进行深层复制。 目标是显着减少复制对象的开销,同时仍保留增量所需的隔离。
没有克隆:
- 应用程序代码可以在修改时读取条目值,可能会看到处于中间不一致状态的值,只应用部分delta。 您可以选择通过使应用程序代码在读取和写入上同步来解决此问题。
- Geode丢失对旧值的任何引用,因为旧值已在适当位置转换为新值。 因此,你的
CacheListener看到了为EntryEvent.getOldValue和EntryEvent.getNewValue返回的相同新值。 - 从
fromDelta抛出的异常可能会使缓存处于不一致状态。 如果没有克隆,delta应用程序的任何中断都可能使您的缓存对象中的某些字段发生更改而其他字段保持不变。 如果您不使用克隆,请在编译fromDelta实现中的错误处理时记住这一点。
伴随着克隆:
fromDelta方法在内存中生成更多垃圾。- 性能降低。
启用克隆如下:
cache.xml:<region name="region_with_cloning"> <region-attributes refid="REPLICATE" cloning-enabled="true"> </region-attributes> </region>API:
RegionFactory rf = cache.createRegionFactory(REPLICATE); rf.setCloningEnabled(true); custRegion = rf.create("customer");gfsh:
gfsh>create region --name="region_with_cloning" --type=REPLICATE --enable-cloning=true
实施增量传播
默认情况下,集群中启用了增量传播。 启用时,增量传播用于实现org.apache.geode.Delta的对象。 您可以对方法进行编程,以存储和提取条目的增量信息,并应用收到的增量信息。
使用以下过程在集群中实现增量传播。
研究对象类型和预期的应用程序行为,以确定哪些区域可以从使用增量传播中受益。 增量传播不会提高所有数据和数据修改方案的性能。 参见何时避免Delta传播.
对于使用增量传播的每个区域,选择是否使用增量传播属性
cloning-enabled启用克隆。 默认情况下禁用克隆。 参见Delta传播属性.如果您不启用克隆,请查看所有关联的侦听器代码以查看
EntryEvent.getOldValue的依赖项。 如果没有克隆,Geode就会修改条目,因此失去对旧值的引用。 对于delta事件,EntryEvent方法getOldValue和getNewValue都返回新值。对于您想要增量传播的每个类,请实现下面的接口
org.apache.geode.Delta
并更新您的方法以支持增量传播。 具体如何执行此操作取决于您的应用程序和对象需求,但这些步骤描述了基本方法:
- 如果该类是普通的旧Java对象(POJO),请将其包装为此实现并更新代码以使用包装类。
- 将用于管理增量状态的任何额外对象字段定义为瞬态。 这可以在分发完整对象时提高性能。 每当使用标准Java序列化时,transient关键字指示Java不对该字段进行序列化。
- 研究对象内容以决定如何处理增量变化。 Delta传播与分布式并发控制具有相同的问题,就像完整对象的分布一样,但是在更详细的层面上。 对象的某些部分可能能够彼此独立地更改,而其他部分可能总是需要一起更改。 发送足够大的增量以保持数据在逻辑上一致。 例如,如果字段A和字段B相互依赖,则delta分布应更新两个字段或两者都不更新。 与常规更新一样,数据区域上的生产者越少,并发问题的可能性就越低。
- 在放置条目的应用程序代码中,将完全填充的对象放入本地缓存中。 即使您计划仅发送增量,接收端上的错误也可能导致Geode请求完整对象,因此您必须将其提供给原始put方法。 即使在空的生产者中也要这样做,区域配置为没有本地数据存储。 这通常意味着要进行输入,除非您确定它在分布式区域中的任何位置都不存在。
- 更改每个字段的更新方法以记录有关更新的信息。 该信息必须足以让
toDelta在调用delta时对delta和任何其他所需的delta信息进行编码。 - 写
hasDelta告知delta是否可用。 - 编写
toDelta来创建一个带有对象更改的字节流,并且任何其他信息fromDelta将需要应用更改。 在从toDelta返回之前,重置delta状态以指示没有等待发送的delta更改。 - 写
fromDelta来解码'toDelta`创建的字节流并更新对象。 - 确保为对象提供足够的同步以维持一致的对象状态。 如果不使用克隆,则可能需要同步读取和写入以避免从缓存中读取部分写入的更新。此同步可能涉及
toDelta,fromDelta,toData,fromData和其他方法 访问或更新对象。 此外,您的实现应考虑并发调用fromDelta和一个或多个对象的更新方法的可能性。
增量传播中的错误
本主题列出了使用增量传播时可能发生的错误。
增量传播中的错误根据系统处理方式分为两类:
应用delta的问题可以通过请求全部值代替delta来补救。 您的
put操作没有看到与此类delta传播失败相关的错误或异常。 系统会自动执行从发送方到发生问题的接收方的完整值分配。 此类错误包括:- 接收缓存中的条目值不可用,原因是条目缺失或其值为null。 在这两种情况下,都没有应用delta的任何内容,必须发送完整值。 如果您通过应用程序调用或通过驱逐或条目到期等已配置的操作在本地销毁或使您的条目无效,则最有可能发生这种情况。
fromDelta方法抛出的InvalidDeltaException,由你编程。 此异常使您可以避免应用违反数据一致性检查或其他应用程序要求的增量。- 在服务器到客户端传播中在客户端中应用增量的任何错误。 除了从服务器检索完整值之外,客户端还会记录警告。
创建或分发无法通过分配完整值来修复的增量的问题。 在这些情况下,您的
put操作会失败并出现异常。 此类错误包括:hasDelta或toDelta中的错误或异常。- 服务器或对等接收器中的错误或异常超出上述第一类中描述的情况。
增量传播示例
本主题提供了增量传播的示例。
在此示例中,馈线客户端连接到第一服务器,接收器客户端连接到第二服务器。 服务器彼此对等。
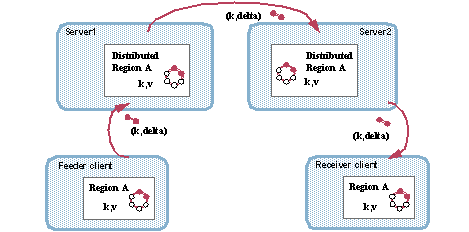
该示例演示了以下操作:
- 在Feeder客户端中,应用程序更新条目对象并放入条目。 响应
put,Geode调用hasDelta,返回true,因此Geode调用toDelta并将提取的delta转发给服务器。 如果hasDelta返回false,Geode将分配完整的条目值。 - 在Server1中,Geode将增量应用于缓存,将收到的增量分发给服务器的对等体,并将其转发给对该条目感兴趣的任何其他客户端(在此示例中没有其他客户端到Server1)
- 在Server2中,Geode将增量应用于缓存并将其转发给感兴趣的客户端,在这种情况下,客户端只是接收客户端。
此示例显示了编写Delta实现的基本方法。
package delta;
import org.apache.geode.Delta;
import org.apache.geode.InvalidDeltaException;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.io.Serializable;
/**
* Sample implementation of Delta
*
* @author GemStone Systems, Inc.
* @since 6.1
*/
public class SimpleDelta implements Delta, Serializable {
// Original object fields
private int intVal;
private double doubleVal;
// Added for delta - one boolean per field to track changed status
private transient boolean intFldChd = false;
private transient boolean dblFldChd = false;
public SimpleDelta(){}
public SimpleDelta(int i, double d){
this.intVal = i;
this.doubleVal = d;
}
public boolean hasDelta() {
return this.intFldChd || this.dblFldChd;
}
public void toDelta(DataOutput out) throws IOException {
System.out.println("Extracting delta from " + this.toString());
// Write information on what has changed to the
// data stream, so fromDelta knows what it's getting
out.writeBoolean(intFldChd);
if (intFldChd) {
// Write just the changes into the data stream
out.writeInt(this.intVal);
// Once the delta information is written, reset the delta status field
this.intFldChd = false;
System.out.println(" Extracted delta from field 'intVal' = "
+ this.intVal);
}
out.writeBoolean(dblFldChd);
if (dblFldChd) {
out.writeDouble(this.doubleVal);
this.dblFldChd = false;
System.out.println(" Extracted delta from field 'doubleVal' = "
+ this.doubleVal);
}
}
public void fromDelta(DataInput in) throws IOException, InvalidDeltaException {
System.out.println("Applying delta to " + this.toString());
// For each field, read whether there is a change
if (in.readBoolean()) {
// Read the change and apply it to the object
this.intVal = in.readInt();
System.out.println(" Applied delta to field 'intVal' = "
+ this.intVal);
}
if (in.readBoolean()) {
this.doubleVal = in.readDouble();
System.out.println(" Applied delta to field 'doubleVal' = "
+ this.doubleVal);
}
}
// In the setter methods, add setting of delta-related
// fields indicating what has changed
public void setIntVal(int anIntVal) {
this.intFldChd = true;
this.intVal = anIntVal;
}
public void setDoubleVal(double aDoubleVal) {
this.dblFldChd = true;
this.doubleVal = aDoubleVal;
}
public String toString() {
return "SimpleDelta [ hasDelta = " + hasDelta() + ", intVal = " +
this.intVal + ", doubleVal = {" + this.doubleVal + "} ]";
}
}
查询
Geode提供了一种类似SQL的查询语言OQL,允许您访问存储在Geode区域中的数据。
由于Geode区域是键值存储,其值可以从简单字节数组到复杂嵌套对象,因此Geode使用基于OQL(对象查询语言)的查询语法来查询区域数据。 OQL与SQL非常相似,但OQL允许您查询复杂对象,对象属性和方法。
查询常见问题和示例
本主题回答有关查询功能的一些常见问题。 它提供了一些示例来帮助您开始使用Geode查询。
使用OQL查询
本节提供Geode查询的高级介绍,例如构建查询字符串和描述查询语言功能。
高级查询
本节包括高级查询主题,例如使用查询索引,使用查询绑定参数,查询分区区域和查询调试。
使用索引
Geode查询引擎支持索引。 索引可以为查询执行提供显着的性能提升。
查询常见问题和示例
本主题回答有关查询功能的一些常见问题。 它提供了一些示例来帮助您开始使用Geode查询。
有关Geode查询的其他信息,请参阅查询.
- 如何针对Geode区域编写和执行查询?
- 我可以查看按查询类型列出的查询字符串示例吗?
- 我应该使用哪些API来编写查询?
- 如何在查询中调用对象的方法?
- 我可以在查询中的对象上调用静态方法吗?
- 如何编写可重用的查询?
- 我应该何时创建要在查询中使用的索引?
- 如何创建索引?
- 我可以查询分区区域吗? 我可以在分区区域上执行连接查询吗?
- 如何提高分区区域查询的性能?
- Geode支持哪些查询语言元素?
- 我如何调试查询?
- 我可以在查询中使用隐式属性或方法吗?
- 如何在OQL中对字段执行不区分大小写的搜索?
如何针对Geode区域编写和执行查询?
要在Geode中编写和执行查询,可以使用以下任何机制。 示例查询代码如下。
- Geode查询API
- gfsh 命令行界面; 特别是查询 命令
- REST API query endpoints
示例Geode查询代码(Java)
// Identify your query string.
String queryString = "SELECT * FROM /exampleRegion";
// Get QueryService from Cache.
QueryService queryService = cache.getQueryService();
// Create the Query Object.
Query query = queryService.newQuery(queryString);
// Execute Query locally. Returns results set.
SelectResults results = (SelectResults)query.execute();
// Find the Size of the ResultSet.
int size = results.size();
// Iterate through your ResultSet.
Portfolio p = (Portfolio)results.iterator().next(); /* Region containing Portfolio object. */
我可以查看按查询类型列出的查询字符串示例吗?
以下示例查询字符串使用/exampleRegion,其键是项目组合ID,其值对应于以下类定义中显示的汇总数据:
class Portfolio implements DataSerializable {
int ID;
String type;
String status;
Map positions;
}
class Position implements DataSerializable {
String secId;
double mktValue;
double qty;
}
基本WHERE子句示例
在以下示例中,status字段的类型为String,ID字段的类型为int。 有关Geode查询支持的文字的完整列表,请参阅支持的文字 。
选择所有有效投资组合
SELECT * FROM /exampleRegion WHERE status = 'active'选择状态以
activ开头的所有投资组合。SELECT * FROM /exampleRegion p WHERE p.status LIKE 'activ%'选择ID大于100的所有投资组合。
SELECT * from /exampleRegion p WHERE p.ID > 100
使用 DISTINCT
从满足status ='active'的where子句条件的区域中选择不同的对象。
SELECT DISTINCT * FROM /exampleRegion WHERE status = 'active'
别名和同义词
在查询字符串中,可以使用别名定义路径表达式(区域及其对象)。 可以在查询的其他位置使用或引用此别名。
SELECT DISTINCT * FROM /exampleRegion p WHERE p.status = 'active'
SELECT p.ID, p.status FROM /exampleRegion p WHERE p.ID > 0
使用NOT运算符
有关支持的运算符的完整列表,请参阅运算符 。
SELECT DISTINCT * FROM /exampleRegion WHERE NOT (status = 'active') AND ID = 2
SELECT * FROM /exampleRegion WHERE NOT (ID IN SET(1,2))
使用AND和OR运算符
有关支持的运算符的完整列表,请参阅运算符。
SELECT * FROM /exampleRegion WHERE ID > 4 AND ID < 9
SELECT * FROM /exampleRegion WHERE ID = 0 OR ID = 1
SELECT DISTINCT p.status FROM /exampleRegion p
WHERE (p.createTime IN SET (10|) OR p.status IN SET ('active')) AND p.ID > 0
使用不等于
SELECT * FROM /exampleRegion portfolio WHERE portfolio.ID <> 2
SELECT * FROM /exampleRegion portfolio WHERE portfolio.ID != 2
投影属性示例
SELECT p.get('account') FROM /exampleRegion p
查询嵌套集合
以下查询使用HashMap类型的位置。
SELECT p, pos FROM /exampleRegion p, p.positions.values pos WHERE pos.secId = 'VMW'
使用 LIMIT
SELECT * FROM /exampleRegion p WHERE p.ID > 0 LIMIT 2
使用 COUNT
有关详细信息,请参阅COUNT。
SELECT COUNT(*) FROM /exampleRegion WHERE ID > 0
SELECT COUNT(*) FROM /exampleRegion WHERE ID > 0 LIMIT 50
SELECT COUNT(*) FROM /exampleRegion WHERE ID > 0 AND status LIKE 'act%'
SELECT COUNT(*) FROM /exampleRegion WHERE ID IN SET(1,2,3,4,5)
SELECT COUNT(*) FROM /exampleRegion p, p.positions.values pos
WHERE p.ID > 0 AND pos.secId 'IBM'
SELECT DISTINCT COUNT(*) FROM /exampleRegion p, p.positions.values pos
WHERE p.ID > 0 OR p.status = 'active' OR pos.secId OR pos.secId = 'IBM'
使用 LIKE
SELECT * FROM /exampleRegion ps WHERE ps.pkid LIKE '_bc'
SELECT * FROM /exampleRegion ps WHERE ps.status LIKE '_b_' OR ps.pkid = '2'
SELECT * FROM /exampleRegion ps WHERE ps.status LIKE '%b%
使用区域输入键和值
SELECT * FROM /exampleRegion.keys k WHERE k.ID = 1
SELECT entry.value FROM /exampleRegion.entries entry WHERE entry.key = '1'
SELECT key, positions FROM /exampleRegion.entrySet, value.positions.values positions
WHERE positions.mktValue >= 25.00
SELECT DISTINCT entry.value FROM /exampleRegion.entries entry WHERE entry.key = '1'
SELECT * FROM /exampleRegion.entries entry WHERE entry.value.ID > 1
SELECT * FROM /exampleRegion.keySet key WHERE key = '1'
SELECT * FROM /exampleRegion.values portfolio
WHERE portfolio.status = 'active'
嵌套查询
IMPORT "query".Portfolio;
SELECT * FROM /exampleRegion, (SELECT DISTINCT * FROM /exampleRegion p TYPE Portfolio, p.positions
WHERE value!=null)
SELECT DISTINCT * FROM (SELECT DISTINCT * FROM /exampleRegion portfolios, positions pos)
WHERE pos.value.secId = 'IBM'
SELECT * FROM /exampleRegion portfolio
WHERE portfolio.ID IN (SELECT p2.ID FROM /exampleRegion2 p2 WHERE p2.ID > 1)
SELECT DISTINCT * FROM /exampleRegion p, (SELECT DISTINCT pos
FROM /exampleRegion x, x.positions.values pos WHERE x.ID = p.ID ) AS itrX
查询FROM子句表达式的结果
SELECT DISTINCT * FROM (SELECT DISTINCT * FROM /Portfolios ptf, positions pos) p
WHERE p.get('pos').value.secId = 'IBM'
Hash Map 查询
使用hashmap查询。 在以下示例中,'version'是hashmap中的键之一。
SELECT * FROM /exampleRegion p WHERE p['version'] = '1.0'
SELECT entry.key, entry.value FROM /exampleRegion.entries entry
WHERE entry.value['version'] = '100'
映射示例“map”是嵌套的HashMap对象
SELECT DISTINCT * FROM /exampleRegion p WHERE p.portfolios['key2'] >= 3
获取数组值的示例查询
SELECT * FROM /exampleRegion p WHERE p.names[0] = 'aaa'
SELECT * FROM /exampleRegion p WHERE p.collectionHolderMap.get('1').arr[0] = '0'
使用 ORDER BY (and ORDER BY with LIMIT)
必须将DISTINCT关键字与ORDER BY查询一起使用。
SELECT DISTINCT * FROM /exampleRegion WHERE ID < 101 ORDER BY ID
SELECT DISTINCT * FROM /exampleRegion WHERE ID < 101 ORDER BY ID asc
SELECT DISTINCT * FROM /exampleRegion WHERE ID < 101 ORDER BY ID desc
SELECT DISTINCT key.ID, key.status AS st FROM /exampleRegion.keys key
WHERE key.status = 'inactive' ORDER BY key.status desc, key.ID LIMIT 1
SELECT DISTINCT * FROM /exampleRegion p ORDER BY p.getP1().secId, p.ID dec, p.ID LIMIT 9
SELECT DISTINCT * FROM /exampleRegion p ORDER BY p.ID, val.secId LIMIT 1
SELECT DISTINCT e.key FROM /exampleRegion.entrySet e ORDER BY e.key.ID desc, e.key.pkid desc
SELECT DISTINCT p.names[1] FROM /exampleRegion p ORDER BY p.names[1]
连接查询
SELECT * FROM /exampleRegion portfolio1, /exampleRegion2 portfolio2
WHERE portfolio1.status = portfolio2.status
SELECT portfolio1.ID, portfolio2.status FROM /exampleRegion portfolio1, /exampleRegion2 portfolio2
WHERE portfolio1.status = portfolio2.status
SELECT * FROM /exampleRegion portfolio1, portfolio1.positions.values positions1,
/exampleRegion2 portfolio2, portfolio2.positions.values positions2 WHERE positions1.secId = positions1.secId
SELECT * FROM /exampleRegion portfolio1, portfolio1.positions.values positions1,
/exampleRegion2 portfolio2, portfolio2.positions.values positions2 WHERE portfolio1.ID = 1
AND positions1.secId = positions1.secId
SELECT DISTINCT a, b.price FROM /exampleRegoin1 a, /exampleRegion2 b WHERE a.price = b.price
使用 AS
SELECT * FROM /exampleRegion p, p.positions.values AS pos WHERE pos.secId != '1'
使用 TRUE
SELECT DISTINCT * FROM /Portfolios WHERE TRUE
使用 IN 和 SET
参见 IN 和 SET.
SELECT * FROM /exampleRegion portfolio WHERE portfolio.ID IN SET(1, 2)
SELECT * FROM /exampleRegion portfolio, portfolio.positions.values positions
WHERE portfolio.Pk IN SET ('1', '2') AND positions.secId = '1'
SELECT * FROM /exampleRegion portfolio, portfolio.positions.values positions
WHERE portfolio.Pk IN SET ('1', '2') OR positions.secId IN SET ('1', '2', '3')
SELECT * FROM /exampleRegion portfolio, portfolio.positions.values positions
WHERE portfolio.Pk IN SET ('1', '2') OR positions.secId IN SET ('1', '2', '3')
AND portfolio.status = 'active'
查询Set值
在以下查询中,sp的类型为Set。
SELECT * FROM /exampleRegion WHERE sp = set('20', '21', '22')
如果Set(sp)仅包含20和21,则查询将评估为false。 查询比较两组并查找两组中元素的存在。
对于像list这样的其他集合类型(sp是List类型),查询可以写成如下:
SELECT * FROM /exampleRegion WHERE sp.containsAll(set('20', '21', '22'))
在对象上调用方法
有关详细信息,请参阅方法调用 。
SELECT * FROM /exampleRegion p WHERE p.length > 1
SELECT DISTINCT * FROM /exampleRegion p WHERE p.positions.size >= 2
SELECT DISTINCT * FROM /exampleRegion p WHERE p.positions.isEmpty
SELECT DISTINCT * FROM /exampleRegion p WHERE p.name.startsWith('Bo')
使用查询级调试
要在查询级别设置调试,请在查询之前添加
<trace>
SELECT * from /exampleRegion, positions.values TYPE myclass
在查询中使用保留字
要访问与查询语言保留字同名的任何方法,属性或命名对象,请将该名称括在双引号内。
SELECT * FROM /exampleRegion WHERE status = 'active' AND "type" = 'XYZ'
SELECT DISTINCT "type" FROM /exampleRegion WHERE status = 'active'
使用 IMPORT
在同一个类名存在于两个不同的名称范围(包)中的情况下,需要有一种引用同名的不同类的方法。 IMPORT语句用于在查询中为类建立名称范围。
IMPORT package.Position;
SELECT DISTINCT * FROM /exampleRegion, positions.values positions TYPE Position WHERE positions.mktValue >= 25.00
使用 TYPE
指定对象类型有助于查询引擎以最佳速度处理查询。 除了在配置期间指定对象类型(使用键约束和值约束)之外,还可以在查询字符串中显式指定类型。
SELECT DISTINCT * FROM /exampleRegion, positions.values positions TYPE Position WHERE positions.mktValue >= 25.00
使用 ELEMENT
使用ELEMENT(expr)从集合或数组中提取单个元素。 如果参数不是只包含一个元素的集合或数组,则此函数抛出FunctionDomainException。
ELEMENT(SELECT DISTINCT * FROM /exampleRegion WHERE id = 'XYZ-1').status = 'active'
我应该使用哪些API来编写查询?
如果要查询Java应用程序的本地缓存或查询其他成员,请使用org.apache.geode.cache.Cache.getQueryService.
如果要将Java客户端编写到服务器查询,请使用org.apache.geode.cache.client.Pool.getQueryService.
如何在查询中调用对象的方法?
要在查询中使用方法,请使用映射到要调用的公共方法的属性名称。 例如:
/*valid method invocation*/
SELECT DISTINCT * FROM /exampleRegion p WHERE p.positions.size >= 2 - maps to positions.size()
我可以在查询中的对象上调用静态方法吗?
不,您无法在对象上调用静态方法。 例如,以下查询无效。
/*invalid method invocation*/
SELECT DISTINCT * FROM /exampleRegion WHERE aDay = Day.Wednesday
要解决此限制,请编写可重用查询,该查询使用查询绑定参数来调用静态方法。 然后在查询运行时,将参数设置为静态方法调用(Day.Wednesday)。 例如:
SELECT DISTINCT * FROM /exampleRegion WHERE aDay = $1
如何编写可重用的查询?
使用查询API,您可以设置在查询运行时传递值的查询绑定参数。 例如:
// specify the query string
String queryString = "SELECT DISTINCT * FROM /exampleRegion p WHERE p.status = $1";
QueryService queryService = cache.getQueryService();
Query query = queryService.newQuery(queryString);
// set a query bind parameter
Object[] params = new Object[1];
params[0] = "active";
// Execute the query locally. It returns the results set.
SelectResults results = (SelectResults) query.execute(params);
// use the results of the query; this example only looks at the size
int size = results.size();
如果使用查询绑定参数代替路径表达式中的区域路径,则参数值必须引用集合(而不是字符串,例如区域路径的名称)。
有关详细信息,请参阅使用查询绑定参数。
我应该何时创建要在查询中使用的索引?
确定查询的性能是否会从索引中受益。 例如,在以下查询中,pkid上的索引可以加快查询速度。
SELECT DISTINCT * FROM /exampleRegion portfolio WHERE portfolio.pkid = '123'
如何创建索引?
可以使用API或使用xml以编程方式创建索引。 这是两个例子:
示例代码
QueryService qs = cache.getQueryService();
qs.createIndex("myIndex", "status", "/exampleRegion");
qs.createKeyIndex("myKeyIndex", "id", "exampleRegion");
有关使用此API的更多信息,请参阅JavaDocs.
示例XML
<region name="portfolios">
<region-attributes . . . >
</region-attributes>
<index name="myIndex">
<functional from-clause="/exampleRegion"
expression="status"/>
</index>
<index name="myKeyIndex">
<primary-key field="id"/>
</index>
<entry>
有关索引的更多详细信息,请参阅使用索引.
我可以在溢出区域创建索引吗?
您可以在溢出区域上创建索引,但是您受到一些限制。 例如,索引本身包含的数据不能溢出到磁盘。 有关详细信息,请参阅使用具有溢出区域的索引 。
我可以查询分区区域吗? 我可以在分区区域上执行连接查询吗?
您可以查询分区区域,但存在一些限制。 您不能对分区区域执行连接查询,但是您可以通过在本地数据集上执行函数来对共置的分区区域执行等连接查询。
有关限制的完整列表,请参阅分区区域查询限制.
如何提高分区区域查询的性能?
如果您知道需要查询的数据,则可以通过使用FunctionService执行查询来定位查询中的特定节点(从而减少查询需要访问的服务器数量)。 有关详细信息,请参阅在单个节点上查询分区区域。 如果要查询已由键或特定字段分区的数据,则应首先创建键索引,然后使用FunctionService以键或字段作为过滤器执行查询。 请参阅优化对按键或字段值分区的数据的查询。
Geode支持哪些查询语言元素?
| 支持的元素 | ||
|---|---|---|
| AND | LIMIT | TO_DATE |
| AS | LIKE | TYPE |
| COUNT | NOT | WHERE |
| DISTINCT | NVL | |
| ELEMENT | OR | |
| FROM | ORDER BY | |
| SELECT | ||
| IMPORT | SET | |
| IN | ||
| IS_DEFINED | TRUE | |
| IS_UNDEFINED |
有关使用每个受支持关键字的更多信息和示例,请参阅支持的关键字.
我如何调试查询?
您可以在查询级别调试特定查询,方法是在要调试的查询字符串之前添加
<trace> SELECT * FROM /exampleRegion
你也可以写:
<TRACE> SELECT * FROM /exampleRegion
执行查询时,Geode将在$GEMFIRE_DIR/system.log中记录一条消息,其中包含以下信息:
[info 2011/08/29 11:24:35.472 PDT CqServer <main> tid=0x1] Query Executed in 9.619656 ms; rowCount = 99;
indexesUsed(0) "select * from /exampleRegion"
如果要为所有查询启用调试,可以通过在启动期间在命令行上设置System属性来启用查询执行日志记录:
gfsh>start server --name=server_name -–J=-Dgemfire.Query.VERBOSE=true
或者您可以以编程方式设置属性:
System.setProperty("gemfire.Query.VERBOSE","true");
我可以在查询中使用隐式属性或方法吗?
如果隐式属性或方法名称只能与一个无类型迭代器关联,则Geode查询处理器将假定它与该迭代器关联。 但是,如果多个非类型化迭代器在范围内,则查询将失败并出现TypeMismatchException。 以下查询失败,因为查询处理器未完全键入表达式:
select distinct value.secId from /pos , getPositions(23)
但是,以下查询成功,因为迭代器是使用变量显式命名的,或者是键入的:
select distinct e.value.secId from /pos , getPositions(23) e
我可以指示查询引擎在查询中使用特定索引吗?
使用HINT indexname可以指示查询引擎优先选择并过滤指定索引的结果。 如果提供多个索引名称,则查询引擎将使用所有可用索引,但更喜欢指定的索引。
<HINT 'IDIndex'> SELECT * FROM /Portfolios p WHERE p.ID > 10 AND p.owner = 'XYZ'
<HINT 'IDIndex', 'OwnerIndex'> SELECT * FROM /Portfolios p WHERE p.ID > 10 AND p.owner = 'XYZ' AND p.value < 100
如何在OQL中对字段执行不区分大小写的搜索?
您可以使用Java String类方法toUpperCase和toLowerCase来转换要执行不区分大小写搜索的字段。 例如:
SELECT entry.value FROM /exampleRegion.entries entry WHERE entry.value.toUpperCase LIKE '%BAR%'
或者
SELECT * FROM /exampleRegion WHERE foo.toLowerCase LIKE '%bar%'
使用OQL查询
本节提供Geode查询的高级介绍,例如构建查询字符串和描述查询语言功能。
Geode提供类似SQL的查询语言,允许您访问存储在Geode区域中的数据。 由于Geode区域是键值存储,其值可以从简单字节数组到复杂嵌套对象,因此Geode使用基于OQL(对象查询语言)的查询语法来查询区域数据。 OQL和SQL有许多语法上的相似之处,但是它们有很大的不同。 例如,虽然OQL不像聚合那样提供SQL的所有功能,但OQL允许您对复杂对象图执行查询,查询对象属性并调用对象方法。
典型的Geode OQL查询的语法是:
[IMPORT package]
SELECT [DISTINCT] projectionList
FROM collection1, [collection2, …]
[WHERE clause]
[ORDER BY order_criteria [desc]]
因此,一个简单的Geode OQL查询类似于以下内容:
SELECT DISTINCT * FROM /exampleRegion WHERE status = ‘active’
Geode查询要注意的一个重要特征是,默认情况下,Geode会查询区域的值而不是键。 要从区域获取键,必须在查询区域上使用keySet路径表达式。 例如,/exampleRegion.keySet。
对于Geode查询的新手,请参阅Geode查询常见问题和示例.
OQL的优点
以下列表描述了使用基于OQL的查询语言的一些优点:
- 您可以查询任意对象
- 您可以导航对象集合
- 您可以调用方法并访问对象的行为
- 支持数据映射
- 您不需要声明类型。 由于您不需要类型定义,因此可以使用多种语言
- 您不受架构约束
在Geode中编写和执行查询
Geode QueryService提供了创建Query对象的方法。 然后,您可以使用Query对象执行与查询相关的操作。
您应该使用的QueryService实例取决于您是查询应用程序的本地缓存还是希望应用程序查询服务器缓存。
查询本地缓存
要查询应用程序的本地缓存或查询其他成员,请使用org.apache.geode.cache.Cache.getQueryService。
示例代码
// Identify your query string.
String queryString = "SELECT DISTINCT * FROM /exampleRegion";
// Get QueryService from Cache.
QueryService queryService = cache.getQueryService();
// Create the Query Object.
Query query = queryService.newQuery(queryString);
// Execute Query locally. Returns results set.
SelectResults results = (SelectResults)query.execute();
// Find the Size of the ResultSet.
int size = results.size();
// Iterate through your ResultSet.
Portfolio p = (Portfolio)results.iterator().next(); /* Region containing Portfolio object. */
从客户端查询服务器缓存
要执行客户端到服务器查询,请使用org.apache.geode.cache.client.Pool.getQueryService。
示例代码
// Identify your query string.
String queryString = "SELECT DISTINCT * FROM /exampleRegion";
// Get QueryService from client pool.
QueryService queryService = pool.getQueryService();
// Create the Query Object.
Query query = queryService.newQuery(queryString);
// Execute Query locally. Returns results set.
SelectResults results = (SelectResults)query.execute();
// Find the Size of the ResultSet.
int size = results.size();
// Iterate through your ResultSet.
Portfolio p = (Portfolio)results.iterator().next(); /* Region containing Portfolio object. */
有关特定API,请参阅以下JavaDocs:
注意: 您还可以使用gfshquery命令执行查询。 见查询.
构建查询字符串
查询字符串是完全形成的OQL语句,可以传递给查询引擎并针对数据集执行。 要构建查询字符串,请组合支持的关键字,表达式和运算符,以创建返回所需信息的表达式。
查询字符串遵循查询语言和语法指定的规则。 它可以包括:
- Namescopes. 例如,IMPORT语句。 请参阅IMPORT声明。
- Path expressions. 例如,在查询
SELECT * FROM /exampleRegion中,/exampleRegion是路径表达式。 参见[FROM Clause](https://geode.apache.org/docs/guide/17/developing/query_select/the_from_clause.html#the_from_clause。 - Attribute names. 例如,在查询
SELECT DISTINCT * FROM /exampleRegion p WHERE p.position1.secId ='1'中,我们访问Position对象的secId属性。 请参阅WHERE子句。 - Method invocations. 例如,在查询
SELECT DISTINCT * FROM /exampleRegion p WHERE p.name.startsWith('Bo')中,我们在Name对象上调用startsWith方法。 请参阅WHERE子句。 - Operators. 例如,比较运算符(=,<,>,<>),一元运算符(NOT),逻辑运算符(AND,OR)等。 有关完整列表,请参阅操作员 。
- Literals. 例如,布尔值,日期,时间等。 有关完整列表,请参阅支持的文字 。
- Query bind parameters. 例如,在查询
SELECT DISTINCT * FROM $1 p WHERE p.status = $2中,$1和$2是可以在运行时传递给查询的参数。 有关详细信息,请参阅使用查询绑定参数。 - Preset query functions. 例如,ELEMENT(expr)和IS_DEFINED(expr)。 有关其他可用功能,请参阅SELECT Statement 。
- SELECT statements. 例如,在上面的
SELECT *或SELECT DISTINCT *的示例查询中。 有关其他可用功能,请参阅SELECT Statement 。 - Comments. OQL允许在查询字符串中附加额外的字符,而不更改字符串的定义。 通过将注释主体包含在
/ *和* /分隔符中来形成多行注释; OQL不允许嵌套注释。 单行注释正文是--(两个连字符)右边的所有字符,直到行尾。
上面列出的组件都可以是查询字符串的一部分,但不需要任何组件。 查询字符串至少包含可以根据指定数据计算的表达式。
以下部分提供了编写典型Geode查询时使用的查询语言构建块的准则。
- IMPORT Statement(IMPORT语句)
- FROM Clause(FROM子句)
- WHERE Clause(WHERE子句)
- SELECT Statement(SELECT语句)
IMPORT Statement(IMPORT语句)
有时OQL查询需要引用对象的类。 如果相同的类名存在于两个不同的名称范围(包)中,则必须能够区分具有相同名称的类。
IMPORT语句用于在查询中为类建立名称。
IMPORT package.Position;
SELECT DISTINCT * FROM /exampleRegion, positions.values positions TYPE Position WHERE positions.mktValue >= 25.00
FROM Clause(FROM子句)
使用FROM子句将所需的数据放入查询的其余部分的范围内。 FROM子句还包括对象类型和迭代器变量。
查询引擎根据查询中当前范围内的名称空间解析名称和路径表达式。
路径表达式
任何查询的初始名称空间由以下内容组成:
区域. 在查询的上下文中,区域的名称由其完整路径指定,以正斜杠(/)开头,并由区域名称之间的正斜杠分隔。 例如,/exampleRegion或/root/exampleRegion。
区域查询属性. 从区域路径,您可以访问Region对象的公共字段和方法,在查询时称为区域的属性。 例如,/exampleRegion.size。
顶级区域数据。
您可以通过区域路径访问输入键和输入数据。
/exampleRegion.keySet返回区域中的输入键集/exampleRegion.entryset返回Region.Entry对象的Set/exampleRegion.values返回条目值集合/exampleRegion返回条目值集合
新名称空间根据SELECT语句中的FROM子句进入作用域。
例子:
查询所有不同值的区域。 从区域返回一组唯一条目值:
SELECT DISTINCT * FROM /exampleRegion
使用entrySet查询顶级区域数据。 返回mktValue属性大于25.00的Region.Entry对象的键和位置:
SELECT key, positions FROM /exampleRegion.entrySet, value.positions.values positions WHERE positions.mktValue >= 25.00
查询区域的条目值。 从Region.Entry对象返回一组唯一值,这些对象的键等于1:
SELECT DISTINCT entry.value FROM /exampleRegion.entries entry WHERE entry.key = '1'
查询区域的条目值。 返回ID字段大于1000的所有条目值的集合:
SELECT * FROM /exampleRegion.entries entry WHERE entry.value.ID > 1000
查询区域中的条目键。 返回键为1的区域中的一组输入键:
SELECT * FROM /exampleRegion.keySet key WHERE key = '1'
查询区域中的值。 返回状态属性值为active的区域中的条目值集合:
SELECT * FROM /exampleRegion.values portfolio WHERE portfolio.status = 'active'
别名和同义词
在查询字符串中,您可以在路径表达式(区域及其对象)中使用别名,以便您可以引用查询中其他位置的区域或对象。
您还可以使用AS关键字为连接的路径表达式提供标签。
例子:
SELECT DISTINCT * FROM /exampleRegion p WHERE p.status = 'active'
SELECT * FROM /exampleRegion p, p.positions.values AS pos WHERE pos.secId != '1'
对象类型
在FROM子句中指定对象类型有助于查询引擎以最佳速度处理查询。 除了在配置期间指定对象类型(使用键约束和值约束)之外,还可以在查询字符串中显式指定类型。
例子:
SELECT DISTINCT * FROM /exampleRegion, positions.values positions TYPE Position WHERE positions.mktValue >= 25.00
WHERE Clause(WHERE子句)
每个FROM子句表达式必须解析为一组对象。 然后,该集合可用于WHERE子句中的查询表达式中的迭代。
例如:
SELECT DISTINCT * FROM /exampleRegion p WHERE p.status = 'active'
条目值集合由WHERE子句迭代,将状态字段与字符串'active'进行比较。 找到匹配项后,条目的值对象将添加到返回集。
在下一个示例查询中,第一个FROM子句表达式中指定的集合由SELECT语句的其余部分使用,包括第二个FROM子句表达式。
SELECT DISTINCT * FROM /exampleRegion, positions.values p WHERE p.qty > 1000.00
实现equals和hashCode方法
如果要对对象执行ORDER BY和DISTINCT查询,则必须在自定义对象中实现equals和hashCode方法。 这些方法必须符合java.lang.Object的在线Java API文档中记录的属性和行为。 如果不存在这些方法,则可能会出现查询结果不一致的情况。
如果在自定义对象中实现了equals和hashCode方法,则必须提供这些方法的详细实现,以便查询对对象正确执行。 例如,假设您已使用以下变量定义了自定义对象(CustomObject):
int ID
int otherValue
让我们将两个CustomObjects(我们称之为CustomObjectA和CustomObjectB)放入缓存中:
CustomObjectA:
ID=1
otherValue=1
CustomObjectB:
ID=1
otherValue=2
如果已实现equals方法以简单地匹配ID字段(ID == ID),则查询将产生不可预测的结果。
以下查询:
SELECT * FROM /CustomObjects c
WHERE c.ID > 1 AND c.ID < 3
AND c.otherValue > 0 AND c.otherValue < 3
返回两个对象,但对象将是CustomObjectA或CustomObjectB中的两个。
或者,以下查询:
SELECT * FROM /CustomObjects c
WHERE c.ID > 1 AND c.ID < 3
AND c.otherValue > 1 AND c.otherValue < 3
返回0结果或2个CustomObjectB结果,具体取决于最后评估的条目。
为了避免不可预测的查询行为,请实现equals和hashCode方法的详细版本。
如果要比较WHERE子句中对象的非原始字段,请使用equals方法而不是=运算符。 例如,使用nonPrimitiveObj.equals(objToBeCompared)代替nonPrimitiveObj = objToBeCompared。
查询序列化的对象
如果要查询分区区域,或者要执行客户机-服务器查询,则对象必须实现serializable。
如果使用PDX序列化,可以访问各个字段的值,而不必反序列化整个对象。 这是通过使用PdxInstance实现的,它是序列化流的包装器。 PdxInstance提供了一个助手方法,该方法接受字段名并返回值,而不反序列化对象。 在评估查询时,查询引擎将通过调用getField方法访问字段值,从而避免反序列化。
要在查询中使用pdxinstance,请确保在服务器的缓存中启用了PDX序列化读取。 在gfsh中,在启动数据成员之前执行以下命令:
gfsh>configure pdx --read-serialized=true
有关更多信息,请参见配置 pdx。
在cache.xml,设置如下:
// Cache configuration setting PDX read behavior
<cache>
<pdx read-serialized="true">
...
</pdx>
</cache>
属性可见性
您可以访问查询的当前范围内可用的任何对象或对象属性。 在查询中,对象的属性是可以映射到对象中的公共字段或方法的任何标识符。 在FROM规范中,作用域中的任何对象都是有效的。 因此,在查询开始时,所有本地缓存区域及其属性都在范围内。
对于属性的位置。secId是公共的,有getter方法“getSecId()”,查询可以写成如下:
SELECT DISTINCT * FROM /exampleRegion p WHERE p.position1.secId = '1'
SELECT DISTINCT * FROM /exampleRegion p WHERE p.position1.SecId = '1'
SELECT DISTINCT * FROM /exampleRegion p WHERE p.position1.getSecId() = '1'
查询引擎尝试使用公共字段值计算值。如果没有找到公共字段值,则使用字段名进行get调用(注意第一个字符是大写的)。
连接
如果FROM子句中的集合彼此不相关,则可以使用WHERE子句连接它们。
下面的语句从 /exampleRegion和 /exampleRegion2区域返回所有具有相同状态的投资组合。
SELECT * FROM /exampleRegion portfolio1, /exampleRegion2 portfolio2 WHERE portfolio1.status = portfolio2.status
要为区域连接创建索引,您需要为连接条件的两边创建单区域索引。这些在连接条件的查询执行期间使用。分区区域不支持区域连接。有关索引的更多信息,请参见使用索引。
例子:
查询两个区域。返回具有相同状态的投资组合的ID和状态。
SELECT portfolio1.ID, portfolio2.status FROM /exampleRegion portfolio1, /exampleRegion2 portfolio2 WHERE portfolio1.status = portfolio2.status
查询两个区域,遍历每个投资组合中的所有头寸。返回所有4元组,包括来自两个区域的值和来自位置的secId字段匹配的两个区域的位置映射的值部分。
SELECT * FROM /exampleRegion portfolio1, portfolio1.positions.values positions1, /exampleRegion2 portfolio2, portfolio2.positions.values positions2 WHERE positions1.secId = positions2.secId
与前一个示例相同的查询,具有匹配的附加约束的ID将为1。
SELECT * FROM /exampleRegion portfolio1, portfolio1.positions.values positions1, /exampleRegion2 portfolio2, portfolio2.positions.values positions2 WHERE portfolio1.ID = 1 AND positions1.secId = positions2.secId
LIKE(好像)
Geode对LIKE谓词提供了有限的支持。LIKE可以用来表示等于。如果您使用通配符(' % ')终止字符串,它的行为类似于以...开始。您还可以将通配符(%或_)放置在比较字符串中的任何其他位置。可以转义通配符来表示字符本身。
注意: 类似谓词的OQL中不支持通配符*。
当有索引时,还可以使用LIKE谓词。
例子:
查询该地区。返回status = active的所有对象:
SELECT * FROM /exampleRegion p WHERE p.status LIKE 'active'
使用通配符查询区域以进行比较。返回状态以activ开头的所有对象:
SELECT * FROM /exampleRegion p WHERE p.status LIKE 'activ%'
不区分大小写字段
您可以使用Java字符串类方法toUpperCase和toLowerCase转换要执行不区分大小写搜索的字段。例如:
SELECT entry.value FROM /exampleRegion.entries entry WHERE entry.value.toUpperCase LIKE '%BAR%'
或者
SELECT * FROM /exampleRegion WHERE foo.toLowerCase LIKE '%bar%'
方法调用
若要在查询中使用方法,请使用映射到要调用的公共方法的属性名。
SELECT DISTINCT * FROM /exampleRegion p WHERE p.positions.size >= 2 - maps to positions.size()
当通过查询处理器调用时,声明返回void evaluate为null的方法。
您不能调用静态方法。有关更多信息,请参见Enum对象。
方法没有参数
如果属性名映射到不接受参数的公共方法,只需将方法名作为属性包含在查询字符串中。例如,emps.isEmpty等价于emps.isEmpty()。
在下面的例子中,查询对position调用isEmpty,并返回没有position的所有投资组合的集合:
SELECT DISTINCT * FROM /exampleRegion p WHERE p.positions.isEmpty
带参数方法
若要使用参数调用方法,请将查询字符串中的方法名称作为属性包含,并在圆括号中提供方法参数。
这个示例将参数“Bo”传递给公共方法,并返回所有以“Bo”开头的名称。
SELECT DISTINCT * FROM /exampleRegion p WHERE p.name.startsWith('Bo')
对于重载的方法,查询处理器通过将运行时参数类型与方法所需的参数类型匹配来决定调用哪个方法。如果只有一个方法的签名与提供的参数匹配,则调用该方法。查询处理器使用运行时类型来匹配方法签名。
如果可以调用多个方法,查询处理器将选择参数类型对给定参数最特定的方法。例如,如果重载的方法包含具有相同数量参数的版本,但是一个以Person类型作为参数,另一个以从Person派生的Employee类型作为参数,则Employee是更特定的对象类型。如果传递给方法的参数与这两种类型兼容,查询处理程序将使用具有Employee参数类型的方法。
查询处理器使用参数和接收器的运行时类型来确定要调用的适当方法。由于使用了运行时类型,具有null值的参数没有类型信息,因此可以与任何对象类型参数匹配。当使用null参数时,如果查询处理器不能根据非空参数确定要调用的正确方法,它将抛出一个AmbiguousNameException。
启用SecurityManager的方法调用
当SecurityManager被启用时,Geode会在调用白名单之外的任何方法时抛出一个NotAuthorizedException:
- On a
Map,Collection, orRegionobject:keySet,entrySet,values,containsKeyorget - On a
Region.Entryobject:getKeyorgetValue - On a
DateorTimestampobject:after,before,getNanos, orgetTime - On a
Stringobject: any method - On any
Numberobject:intValue,longValue,shortValue, etc. - On any
Booleanobject:booleanValue - On any object:
equals,compareTo, ortoString
要禁用授权检查,请使用添加的系统属性gemfire.QueryService.allowUntrustedMethodInvocation启动所有服务器。例如:
gfsh>start server --name=Server1 \
--J=-Dgemfire.QueryService.allowUntrustedMethodInvocation=true
枚举对象
要基于枚举对象字段的值编写查询,必须使用枚举对象的toString方法或使用查询绑定参数。
例如,以下查询无效:
//INVALID QUERY
select distinct * from /QueryRegion0 where aDay = Day.Wednesday
它无效的原因是调用到 Day.Wednesday 涉及不支持的静态类和方法调用。
枚举类型可以通过枚举对象的toString方法或使用bind参数来查询。当您使用toString方法查询时,您必须已经知道希望查询的约束值。在下面的第一个示例中,已知值是active。
例子:
查询枚举类型使用toString方法:
// eStatus is an enum with values 'active' and 'inactive'
select * from /exampleRegion p where p.eStatus.toString() = 'active'
使用绑定参数查询枚举类型。期望的Enum字段(Day.Wednesday)的值作为执行参数传递:
select distinct * from /QueryRegion0 where aDay = $1
IN 和 SET
IN表达式是一个布尔值,指示在兼容类型的表达式集合中是否存在一个表达式。该决定基于表达式的equals语义。
如果e1和e2是表达式,e2是集合,e1是类型为e2的子类型或元素类型相同的对象或文字,那么e2中的e1是布尔类型的表达式。
表达式返回:
- 如果e1不是未定义的并且包含在集合e2中,则为TRUE
- 如果e1不是未定义的,且集合e2中不包含e1,则为FALSE
- 如果e1没有定义怎返回UNDEFINED
例如,集合(1,2,3)中的2为真。
另一个例子是,您正在查询的集合是由一个子查询定义的。这个查询寻找的公司有一个活跃的投资组合文件:
SELECT name, address FROM /company
WHERE id IN (SELECT id FROM /portfolios WHERE status = 'active')
内部SELECT语句返回状态为活动的所有/portfolio条目的id集合。外部选择在/company上迭代,将每个条目的id与此集合进行比较。对于每个条目,如果IN表达式返回TRUE,那么相关的名称和地址将添加到外部SELECT的集合中。
比较 Set 值
下面是一个集合值类型比较的例子,其中sp是集合类型:
SELECT * FROM /exampleRegion WHERE sp = set('20','21','22')
在这种情况下,如果sp只包含 '20’和'21’,那么查询将求值为false。查询比较这两个集合,并查找这两个集合中的所有元素。
对于list等其他集合类型,查询可以写成:
SELECT * FROM /exampleRegion WHERE sp.containsAll(set('20','21','22))
其中sp为List类型。
为了将其用于Set值,查询可以写成:
SELECT * FROM /exampleRegion WHERE sp IN SET (set('20','21','22'),set('10',11','12'))
在集合中搜索集合值。
一个问题是不能在集合类型或列表类型(集合类型)上创建不可比较的索引。要解决这个问题,可以在实现Comparable的自定义集合类型上创建索引。
Double.NaN 和 Float.NaN 比较
Double.NaN 和 Float.NaN的比较行为,在Geode查询中的NaN遵循JDK方法Float.compareTo和Double.compareTo的语义。
综上所述,当Java语言的数值比较运算符(<,<=,==,>= >)应用于原语double [float]值时,其比较的不同之处在于:
- Double.NaN [Float.NaN] 被认为等于它本身,并且大于所有其他double [float]值(包括Double.POSITIVE_INFINITY [Float.POSITIVE_INFINITY])。
- 该方法认为0.0d [0.0f]大于-0.0d [-0.0f]。
因此,Double.NaN[Float.NaN]被认为大于Double.POSITIVE_INFINITY[Float.POSITIVE_INFINITY]。下面是一些示例查询和预期结果。
| 如果 p.value 是 NaN, 下面的查询: | 计算结果为: | 出现在结果集中? |
|---|---|---|
SELECT * FROM /positions p WHERE p.value = 0 |
false | no |
SELECT * FROM /positions p WHERE p.value > 0 |
true | yes |
SELECT * FROM /positions p WHERE p.value >= 0 |
true | yes |
SELECT * FROM /positions p WHERE p.value < 0 |
false | no |
SELECT * FROM /positions p WHERE p.value <= 0 |
false | no |
| 如果 p.value 和 p.value1 都是 NaN, 下面的查询: | 计算结果为: | 出现在结果集中: |
SELECT * FROM /positions p WHERE p.value = p.value1 |
true | yes |
如果在代码中定义以下查询时将值组合在一起,那么在执行查询时,解析值本身被认为是未定义的,不会在结果集中返回。
String query = "SELECT * FROM /positions p WHERE p.value =" + Float.NaN
执行此查询时,解析后的值本身被认为是未定义的,不会在结果集中返回。
要检索NaN值而不需要另一个字段已经存储为NaN,可以在代码中定义以下查询:
String query = "SELECT * FROM /positions p WHERE p.value > " + Float.MAX_VALUE;
算术运算
算术运算符可以用在任何表达式中。
例如,该查询选择体重指数小于25的所有人:
String query = "SELECT * FROM /people p WHERE p.height * p.height/p.weight < 25";
SELECT Statement(SELECT语句)
SELECT语句允许您从WHERE搜索操作返回的对象集合中筛选数据。投影列表可以指定为*,也可以指定为以逗号分隔的表达式列表。
对于*,WHERE子句的临时结果将从查询中返回。
例子:
使用*查询区域中的所有对象。返回投资组合的集合(exampleRegion将投资组合包含为值)。
SELECT * FROM /exampleRegion
从位置查询secid。从活动投资组合的头寸中返回secid集合:
SELECT secId FROM /exampleRegion, positions.values TYPE Position
WHERE status = 'active'
返回活动投资组合的struct
SELECT "type", positions FROM /exampleRegion
WHERE status = 'active'
返回活动投资组合
SELECT * FROM /exampleRegion, positions.values
TYPE Position WHERE status = 'active'
返回活动投资组合
SELECT * FROM /exampleRegion portfolio, positions positions
TYPE Position WHERE portfolio.status = 'active'
SELECT语句的结果
SELECT语句的结果要么是未定义的,要么是实现SelectResults接口的集合。
从SELECT语句返回的SelectResults是:
- 为这两种情况返回的对象集合:
- 当投影列表只指定一个表达式且该表达式未使用字段名:表达式语法显式指定时
- 当SELECT列表为*且FROM子句中指定了单个集合时
- 包含对象的结构的集合
当返回结构体时,结构体中每个字段的名称按照以下优先顺序确定:
- 如果使用字段名:表达式语法显式指定字段,则使用字段名。
- 如果SELECT投影列表是*,并且FROM子句中使用显式迭代器表达式,则迭代器变量名用作字段名。
- 如果字段与区域或属性路径关联,则使用该路径中的最后一个属性名。
- 如果不能根据这些规则决定名称,查询处理器将生成任意惟一的名称。
DISTINCT(独特的)
如果希望将结果设置为唯一的行,请使用DISTINCT关键字。注意,在Geode的当前版本中,您不再需要在SELECT语句中使用DISTINCT关键字。
SELECT DISTINCT * FROM /exampleRegion
注意: 如果使用DISTINCT查询,则必须为查询的对象实现equals和hashCode方法。
LIMIT(限制)
您可以在查询字符串的末尾使用LIMIT关键字来限制返回的值的数量。
例如,这个查询最多返回10个值:
SELECT * FROM /exampleRegion LIMIT 10
ORDER BY(排序)
可以使用order by子句按升序或降序排列查询结果。在编写ORDER BY查询时,必须使用DISTINCT。
SELECT DISTINCT * FROM /exampleRegion WHERE ID < 101 ORDER BY ID
以下查询按升序对结果进行排序:
SELECT DISTINCT * FROM /exampleRegion WHERE ID < 101 ORDER BY ID asc
以下查询按降序对结果进行排序:
SELECT DISTINCT * FROM /exampleRegion WHERE ID < 101 ORDER BY ID desc
注意: 如果使用ORDER BY查询,则必须为查询的对象实现equals和hashCode方法。
预设的查询功能
Geode提供了几个内置函数来评估或过滤查询返回的数据。其中包括:
| 函数 | 描述 | 例子 |
|---|---|---|
| ELEMENT(expr) | 从集合或数组中提取单个元素。如果参数不是只有一个元素的集合或数组,则该函数抛出一个FunctionDomainException。 |
ELEMENT(SELECT DISTINCT * FROM /exampleRegion WHERE id = 'XYZ-1').status = 'active' |
| IS_DEFINED(expr) | 如果表达式的值不为UNDEFINED,则返回TRUE。不等式查询在查询结果中包含未定义的值。使用IS_DEFINED函数,您可以将结果限制为只有那些具有定义值的元素。 | IS_DEFINED(SELECT DISTINCT * FROM /exampleRegion p WHERE p.status = 'active') |
| IS_UNDEFINED (expr) | 如果表达式计算结果为UNDEFINED,则返回TRUE。除不等式查询外,大多数查询的查询结果中不包含未定义的值。IS_UNDEFINED函数允许包含未定义的值,因此可以使用未定义的值标识元素。 | SELECT DISTINCT * FROM /exampleRegion p WHERE IS_UNDEFINED(p.status) |
| NVL(expr1, expr2) | 如果expr1为空,则返回expr2。表达式可以是查询参数(绑定参数)、路径表达式或文本。 | |
| TO_DATE(date_str, format_str) | 返回一个Java数据类对象。参数必须是字符串S, date_str表示日期,format_str表示date_str使用的格式。您提供的format_str是使用java.text.SimpleDateFormat解析的。 |
COUNT
COUNT关键字返回与WHERE子句中指定的查询选择条件匹配的结果数。使用COUNT可以确定结果集的大小。COUNT语句总是返回一个整数作为结果。
以下查询是返回区域项的示例计数查询:
SELECT COUNT(*) FROM /exampleRegion
SELECT COUNT(*) FROM /exampleRegion WHERE ID > 0
SELECT COUNT(*) FROM /exampleRegion WHERE ID > 0 LIMIT 50
SELECT COUNT(*) FROM /exampleRegion WHERE ID >0 AND status LIKE 'act%'
SELECT COUNT(*) FROM /exampleRegion WHERE ID IN SET(1,2,3,4,5)
下面的COUNT查询返回与查询的选择条件匹配的结构类型的总数。
SELECT COUNT(*)
FROM /exampleRegion p, p.positions.values pos
WHERE p.ID > 0 AND pos.secId 'IBM'
下面的COUNT查询使用不同的关键字,并从结果的数量中消除重复。
SELECT DISTINCT COUNT(*)
FROM /exampleRegion p, p.positions.values pos
WHERE p.ID > 0 OR p.status = 'active' OR pos.secId
OR pos.secId = 'IBM'
OQL聚合函数
支持针对不同表达式的聚合函数MIN、MAX、AVG、AVG、SUM、COUNT和COUNT。在适当的情况下,还支持GROUP BY扩展。
MIN函数的作用是:返回所选表达式中最小的一个。表达式的类型必须计算为java.lang.Comparable。
MAX函数的作用是:返回所选表达式中最大的一个。表达式的类型必须计算为java.lang.Comparable。
AVG函数的作用是:返回所选表达式的算术平均值。表达式的类型必须计算为java.lang.Number。对于分区区域,每个节点的bucket为执行查询的节点提供一个和和元素的数量,这样就可以计算出正确的平均值。
有DISTINCT限定符的AVG函数的作用是:返回一组唯一值(不同值)的算术平均值。表达式的类型必须计算为java.lang.Number。对于分区区域,节点bucket中的不同值返回给执行查询的节点。然后,在消除来自不同节点的重复值之后,查询节点可以计算跨节点的唯一值的平均值。
SUM函数的作用是:返回选定表达式形成的集合的和。表达式的类型必须计算为java.lang.Number。对于分区区域,每个节点的bucket计算该节点上的和,并将该和返回到执行查询的节点,然后计算所有节点上的和。
将DISTINCT修饰符应用于表达式的SUM函数返回对一组惟一(不同)值的和。表达式的类型必须计算为java.lang.Number。对于分区区域,节点bucket中的不同值返回给执行查询的节点。然后,在消除来自不同节点的重复值之后,查询节点可以计算节点间惟一值的总和。
COUNT函数的作用是:返回所选表达式在集合中形成的值的数量。例如,返回销售额为正的员工数量:
SELECT count(e.sales) FROM /employees e WHERE e.sales > 0.0
应用DISTINCT修饰符的' COUNT '函数返回所选表达式形成的集合中唯一(不同)值的数量。
通过扩展对聚合函数进行GROUP BY
当聚合函数与其他选定项组合使用时,需要GROUP BY。它允许排序。例如,
SELECT ID, MAX(e.sales) FROM /employees e GROUP BY ID
OQL语法和语义
本节介绍以下查询语言特性:
- 支持的字符集
- 支持的关键字
- 区分大小写
- 查询字符串中的注释
- 查询语言语法
- 操作符
- 保留字
- 支持的文字
支持的字符集
Geode查询语言支持完整的ASCII和Unicode字符集。
支持的关键字
| 查询语言关键字 | 描述 | 例子 |
|---|---|---|
| AND | 逻辑运算符,用于通过组合两个或多个表达式来生成布尔结果来创建复杂表达式。当您使用AND运算符组合两个条件表达式时,两个条件的值都必须为true,才能使整个表达式为真。 | See Operators |
| AS | 用于为路径表达式提供标签,以便稍后可以通过标签引用路径。 | See Aliases and Synonyms |
| COUNT | 返回与提供的条件匹配的结果的数量。 | See COUNT |
| DISTINCT | 将select语句限制为唯一的结果(消除重复)。 | See DISTINCT |
| ELEMENT | 查询功能。从集合或数组中提取单个元素。如果参数不是只有一个元素的集合或数组,则该函数抛出一个FunctionDomainException。 |
See Preset Query Functions |
| FROM | 您可以访问查询的当前范围内可用的任何对象或对象属性。 | See FROM Clause |
| 指示查询引擎优先选择某些索引的关键字。 | See Using Query Index Hints | |
| IMPORT | 用于建立对象的名称库。 | See IMPORT Statement |
| IN | IN表达式是一个布尔值,指示一个表达式是否存在于兼容类型的表达式集合中。 | See IN and SET |
| IS_DEFINED | 查询功能。如果表达式的值不为UNDEFINED,则返回TRUE。不等式查询在查询结果中包含未定义的值。使用IS_DEFINED函数,您可以将结果限制为只有那些具有定义值的元素。 | See Preset Query Functions |
| IS_UNDEFINED | 查询功能。如果表达式计算结果为UNDEFINED,则返回TRUE。除不等式查询外,大多数查询的查询结果中不包含未定义的值。IS_UNDEFINED函数允许包含未定义的值,因此可以使用未定义的值标识元素。 | See Preset Query Functions |
| LIMIT | 限制返回结果的数量。如果使用limit关键字,还不能对执行任何类型的汇总活动的查询结果集运行操作。例如,试图从带有LIMIT子句的查询中运行add或addAll或SelectResult会抛出异常。 | See LIMIT |
| LIKE | LIKE可以用来表示等于,或者如果您以通配符(%)结束字符串,它的行为类似于以开头。请注意,通配符只能在比较字符串的末尾使用。可以转义通配符来表示%字符。如果有索引,还可以使用LIKE谓词。 |
See LIKE |
| NOT | 该示例返回具有头寸的投资组合集。注意NOT不能使用索引。 | See Operators |
| NVL | 如果expr1为空,则返回expr2。表达式可以是查询参数(绑定参数)、路径表达式或文本。参见预设置查询函数 | |
| OR | 如果表达式同时使用AND和OR运算符,则AND表达式的优先级高于OR。 | See Operators |
| ORDER BY | 允许您对查询结果进行排序(升序或降序)。 | See ORDER BY |
| SELECT | 允许您从WHERE搜索操作返回的对象集合中筛选数据。 | See SELECT Statement |
| SET | 指定可与查询的返回值进行比较的值的集合。 | See IN and SET |
| 启用对以下查询字符串的调试。 | See Query Debugging | |
| TO_DATE | 返回一个Java数据类对象。参数必须是字符串S, date_str表示日期,format_str表示date_str使用的格式。您提供的format_str是使用java.text.SimpleDateFormat解析的。 | See Preset Query Functions |
| TYPE | 在FROM子句中指定对象类型有助于查询引擎以最佳速度处理查询。 | See Object Typing |
| WHERE | 解析为对象的集合。然后集合可以在WHERE子句后面的查询表达式中进行迭代。 | See WHERE Clause |
区分大小写
查询语言关键字(如SELECT、NULL、DATE和
在查询字符串和区域条目匹配方面,如果希望对特定字段执行不区分大小写的搜索,可以在查询中使用Java字符串类toUpperCase和toLowerCase方法。例如:
SELECT entry.value FROM /exampleRegion.entries entry WHERE entry.value.toUpperCase LIKE '%BAR%'
或者
SELECT * FROM /exampleRegion WHERE foo.toLowerCase LIKE '%bar%'
查询字符串中的注释
注释行使用--(双破折号)。注释块以/*开头,以*/结尾。例如:
SELECT * --my comment
FROM /exampleRegion /* here is
a comment */ WHERE status = ‘active’
查询语言语法
语言的语法
语法中使用的符号:n 一种非终结符,必须出现在语法中规则左侧的某个位置。所有非终结符号都必须被派生为终结符号。
t 终端符号(以斜体粗体显示)。
x y x followed by y
x | y x or y
(x | y) x or y
[ x ] x or empty
{ x } A possibly empty sequence of x.
备注 描述性的文本
语法列表:
symbol ::= expression
query_program ::= [ imports semicolon ] query [semicolon]
imports ::= import { semicolon import }
import ::= IMPORT qualifiedName [ AS identifier ]
query ::= selectExpr | expr
selectExpr ::= SELECT DISTINCT projectionAttributes fromClause [ whereClause ]
projectionAttributes ::= * | projectionList
projectionList ::= projection { comma projection }
projection ::= field | expr [ AS identifier ]
field ::= identifier colon expr
fromClause ::= FROM iteratorDef { comma iteratorDef }
iteratorDef ::= expr [ [ AS ] identifier ] [ TYPE identifier ] | identifier IN expr [ TYPE identifier ]
whereClause ::= WHERE expr
expr ::= castExpr
castExpr ::= orExpr | left_paren identifier right_paren castExpr
orExpr ::= andExpr { OR andExpr }
andExpr ::= equalityExpr { AND equalityExpr }
equalityExpr ::= relationalExpr { ( = | <> | != ) relationalExpr }
relationalExpr ::= additiveExpr { ( < | <= | > | >= ) additiveExpr }
additiveExpr ::= multiplicativeExpr { (+ | -) multiplicativeExpr }
multiplicativeExpr ::= inExpr { (MOD | % | / | *) inExpr}
inExpr ::= unaryExpr { IN unaryExpr }
unaryExpr ::= [ NOT ] unaryExpr
postfixExpr ::= primaryExpr { left_bracket expr right_bracket }
| primaryExpr { dot identifier [ argList ] }
argList ::= left_paren [ valueList ] right_paren
qualifiedName ::= identifier { dot identifier }
primaryExpr ::= functionExpr
| identifier [ argList ]
| undefinedExpr
| collectionConstruction
| queryParam
| literal
| ( query )
| region_path
functionExpr ::= ELEMENT left_paren query right_paren
| NVL left_paren query comma query right_paren
| TO_DATE left_paren query right_paren
undefinedExpr ::= IS_UNDEFINED left_paren query right_paren
| IS_DEFINED left_paren query right_paren
collectionConstruction ::= SET left_paren [ valueList ] right_paren
valueList ::= expr { comma expr }
queryParam ::= $ integerLiteral
region_path ::= forward_slash region_name { forward_slash region_name }
region_name ::= name_character { name_character }
identifier ::= letter { name_character }
literal ::= booleanLiteral
| integerLiteral
| longLiteral
| doubleLiteral
| floatLiteral
| charLiteral
| stringLiteral
| dateLiteral
| timeLiteral
| timestampLiteral
| NULL
| UNDEFINED
booleanLiteral ::= TRUE | FALSE
integerLiteral ::= [ dash ] digit { digit }
longLiteral ::= integerLiteral L
floatLiteral ::= [ dash ] digit { digit } dot digit { digit } [ ( E | e ) [ plus | dash ] digit { digit } ] F
doubleLiteral ::= [ dash ] digit { digit } dot digit { digit } [ ( E | e ) [ plus | dash ] digit { digit } ] [ D ]
charLiteral ::= CHAR single_quote character single_quote
stringLiteral ::= single_quote { character } single_quote
dateLiteral ::= DATE single_quote integerLiteral dash integerLiteral dash integerLiteral single_quote
timeLiteral ::= TIME single_quote integerLiteral colon
integerLiteral colon integerLiteral single_quote
timestampLiteral ::= TIMESTAMP single_quote
integerLiteral dash integerLiteral dash integerLiteral integerLiteral colon
integerLiteral colon
digit { digit } [ dot digit { digit } ] single_quote
letter ::= any unicode letter
character ::= any unicode character except 0xFFFF
name_character ::= letter | digit | underscore
digit ::= any unicode digit
以下表达式均为终端字符:
dot ::= .
left_paren ::= (
right_paren ::= )
left_bracket ::= [
right_bracket ::= ]
single_quote ::= ’
underscore ::= _
forward_slash ::= /
comma ::= ,
semicolon ::= ;
colon ::= :
dash ::= -
plus ::= +
语言附录
查询语言关键字(如SELECT、NULL和DATE)不区分大小写。属性名、方法名和路径表达式等标识符是区分大小写的。
注释行以--(双破折号)开头。
注释块以/开头,以/结尾。
字符串文字由单引号分隔。嵌入单引号加倍。
例子:
'Hello' value = Hello 'He said, ''Hello''' value = He said, 'Hello'字符文字以CHAR关键字开头,后跟单引号中的字符。单引号字符本身表示为`CHAR ''''(带有四个单引号)。
在时间戳文本中,小数点后最多有9位数字。
操作符
Geode支持比较、逻辑、一元、算术、映射、索引、点和右箭头操作符。
比较运算符
比较运算符比较两个值并返回结果,要么为真,要么为假。
以下是支持的比较运算符:
| 操作符 | 含义 |
|---|---|
| < | less than |
| <= | less than or equal to |
| > | greater than |
| >= | greater than or equal to |
| = | equal to |
| != | not equal to |
| <> | not equal to |
关于等式和不等式运算符:
- 等式和不等式运算符的优先级低于其他比较运算符。
- 等式和不等式运算符可以与null一起使用。
- 不等式查询返回搜索字段为UNDEFINED。的结果
- 要执行与UNDEFINED相等或不相等的比较,使用IS_DEFINED和IS_UNDEFINED预置查询函数,而不是这些比较运算符。
逻辑运算符
逻辑运算符AND 和 OR 允许您通过组合表达式来生成布尔结果来创建更复杂的表达式。当您使用AND运算符组合两个条件表达式时,两个条件的值都必须为true,才能使整个表达式为真。当您使用OR运算符组合两个条件表达式时,如果其中一个或两个条件都为真,则表达式的计算结果为真。您可以通过使用AND和OR操作符组合多个简单条件表达式来创建复杂表达式。当表达式使用AND和或运算符时,且具有比OR更高的优先级。
一元操作符
一元运算符操作单个值或表达式,在表达式中优先级低于比较运算符。Geode不支持一元运算符。NOT是否定运算符,它将操作数的值更改为相反的值。例如,如果表达式的计算结果为TRUE,则不将其更改为FALSE。操作数必须是布尔值。
算术运算符
算术运算符操作两个值或表达式。任何预期的算术异常都可能导致溢出或除以0。QueryInvocationTargetException将被抛出,getCause()将声明ArithmeticException。
以下是支持的算术运算符:
| 操作符 | 含义 |
|---|---|
| + | addition |
| - | subtraction |
| * | multiplication |
| / | division |
| % | modulus |
| MOD | modulus |
映射和索引操作符
映射和索引操作符访问键/值集合(如映射和区域)和有序集合(如数组、列表和String)中的元素。操作符由紧挨着集合名称的一组方括号([])表示。这些括号中提供了映射或索引规范。
数组、列表和字符串元素使用索引值进行访问。索引从第一个元素的0开始,从第二个元素的1开始,依此类推。如果myList是一个数组、列表或String,而index是一个计算结果为非负整数的表达式,那么myList[index]表示myList的第(index+1)个元素。字符串的元素是组成字符串的字符列表。
Map和region值通过键使用相同的语法进行访问。关键字可以是任何对象。对于区域,map操作只在本地缓存中执行非分布式的get,不使用netSearch。因此,myRegion[keyExpression]等价于myRegion. getentry(keyExpression).getvalue。
点,右箭头和正斜杠运算符
点运算符(' . ')分隔路径表达式中的属性名,并指定通过对象属性的导航。右箭头(' -> ')是与圆点等价的另一个替代符号。当导航到子区域时,正斜杠用于分隔区域名称。
保留字
这些词是为查询语言保留的,不能用作标识符。Geode目前不使用后面带有星号(*)的单词,而是为将来的实现保留。
abs* all and andthen* any* array as asc avg* bag* boolean by byte char collection count date declare* define* desc |
dictionary distinct double element enum* except* exists* false first* flatten* float for* from group* having* import in int intersect* interval* |
is_defined is_undefined last* like limit list* listtoset* long map max* min* mod nil not null nvl octet or order |
orelse* query* select set short some* string struct* sum* time timestamp to_date true type undefine* undefined union* unique* where |
|---|---|---|---|
若要访问与查询语言保留字具有相同名称的任何方法、属性或命名对象,请将名称用双引号括起来。
例子:
SELECT DISTINCT "type" FROM /portfolios WHERE status = 'active'
SELECT DISTINCT * FROM /region1 WHERE emps."select"() < 100000
支持文字
Geode支持以下文字类型:
boolean
一个布尔值, TRUE 或者 FALSE
int 和 long
如果一个整数的后缀是ASCII字母l,那么它的类型是long,否则它的类型是int。
浮点
如果浮点文字的后缀是ASCII字母F,则它的类型为float。否则,它的类型是double。可选地,它可以有ASCII字母D的后缀。双精度字面值或浮点字面值可以选择性地包含指数后缀E或e,后跟有符号或无符号数字。
string
字符串文字由单引号分隔。嵌入的单引号加倍。例如,字符串'Hello'的值为Hello,而字符串'He said, ''Hello'''的值为He said, 'Hello'。嵌入的换行符保留为字符串文本的一部分。
char
如果一个字面值是以关键字char为前缀的字符串字面值,则它是char类型,否则它是string类型。单引号字符的 CHAR 文字是CHAR ''''(四个单引号)。
date
java.sql.Date对象,该对象使用以Date关键字DATE yyyy-mm-dd为前缀的JDBC格式。在Date中,yyyy代表年份,mm代表月份,dd代表日子。年份必须用四位数表示;不允许用两位数的缩写来表示年份。
time
java.sql.Time对象,该对象使用JDBC格式(基于24小时时钟),前缀为Time关键字:TIME hh:mm:ss。在Time中,hh代表小时,mm代表分钟,ss代表秒。
timestamp
java.sql.Timestamp对象,该对象使用带有时间戳前缀的JDBC格式:TIMESTAMP yyyy-mm-dd hh:mm:ss.fffffffff。在Timestamp中,“yyyy-mm-dd”表示日期,hh:mm:ss表示时间,fffffff表示分数秒(最多9位)。
NIL
NULL的等效替换。
NULL
与Java中的null相同。
UNDEFINED
任何数据类型的一个特殊的文本有效值,指示没有为给定的数据项指定任何值(甚至不为空)。
NULL和UNDEFINED之间的区别
与Java一样,在OQL中,NULL是指示“无值”的可分配实体(对象)。
在OQL中,UNDEFINED是一种类型。没有等效的Java。在OQL搜索结果中,可以在两种情况下返回未定义的值:
- 搜索不存在的键或值的结果
- 作为访问空值属性的属性的结果。
搜索不等式会返回结果中未定义的值。
请注意,如果您访问一个显式值为NULL的属性,那么它不是未定义的。
例如,如果查询访问address.city而address是NULL,那么结果是UNDEFINED。如果查询访问address,那么结果不是UNDEFINED,它是NULL。
与java.util.Date比较值
您可以将时态文字值DATE、TIME和TIMESTAMP与java.util.Date值进行比较。查询语言中的日期中,没有java.util.Date字面值。
类型转换
Geode查询处理器在某些情况下执行隐式类型转换和提升,以计算包含不同类型的表达式。查询处理器执行二进制数字提升、方法调用转换和时间类型转换。
二进制数字提升
查询处理器对以下运算符的操作数进行二进制数值提升:
- 比较运算符 <, <=, >, 和 >=
- 等算子 = 和 <>
- 二进制数字提升将数字表达式中的操作数扩展到任何操作数所使用的最宽表示形式。在每个表达式中,查询处理器按照规定的顺序应用以下规则,直到进行转换:
- 如果任一操作数类型为double,则另一个操作数转换为double
- 如果任一操作数类型为float,则将另一个操作数转换为float
- 如果任一操作数类型为long,则将另一个操作数转换为long
- 两个操作数都转换为类型int char
方法调用转换
查询语言中的方法调用转换遵循与Java方法调用转换相同的规则,只是查询语言使用运行时类型而不是编译时类型,并且处理空参数的方式与Java中不同。使用运行时类型的一个方面是,具有null值的参数没有类型信息,因此可以与任何类型参数匹配。当使用null参数时,如果查询处理器不能根据非空参数确定要调用的适当方法,它将抛出一个AmbiguousNameException
时间类型转换
查询语言支持的时态类型包括Java类型 java.util.Date、java.sql.Date、java.sqlTime和java.sqlTimestamp,它们都被同等对待,可以在索引中进行比较和使用。与其他类型相比,这些类型都被视为纳秒量。
枚举转换
枚举不会自动转换。要在查询中使用枚举值,必须使用枚举对象的toString方法或使用查询绑定参数。有关更多信息,请参见Enum对象。
Float.NaN 和 Double.NaN
Float.NaN and Double.NaN不作为原语计算;相反,它们的比较方式与JDK方法Float.compareTo和Double.compareTo相同。参见Double.NaN and Float.NaN Comparisons 以获取更多信息。
查询语言限制和不受支持的特性
在高级别上,Geode不支持以下查询特性:
不支持针对跨多个区域的连接的索引
静态方法调用。例如,以下查询无效:
SELECT DISTINCT * FROM /QueryRegion0 WHERE aDay = Day.Wednesday不能使用不可比较的Set/List类型(集合类型)在字段上创建索引。OQL索引实现希望字段具有可比性。要解决这个问题,可以创建实现Comparable的自定义集合类型。
ORDER BY只支持DISTINCT的查询。
此外,分区区域查询还有一些特定的限制。参见分区区域查询限制。
高级查询
本节包括高级查询主题,如使用查询索引、使用查询绑定参数、查询分区区域和查询调试。
性能考虑
本主题讨论了改进查询性能的考虑事项。
查询时监视内存不足
查询监视功能防止在执行查询或创建索引时发生内存不足异常。
长时间运行查询的超时
为长时间运行的查询配置一个超时值,以便它们不完成,当查询运行的时间超过配置的值时,Geode将抛出异常。
使用查询绑定参数
在Geode查询中使用查询绑定参数类似于在SQL中使用预置语句,在SQL中可以在查询执行期间设置参数。这允许您一次构建查询,并在运行时通过传递查询条件多次执行查询。
查询分区的区域
Geode允许您使用分区区域跨分布式节点管理和存储大量数据。分区区域的基本存储单元是bucket,它驻留在Geode节点上,包含映射到单个hashcode的所有条目。在典型的分区区域查询中,系统将查询分布到所有节点上的所有bucket中,然后合并结果集并发回查询结果。
查询调试
通过在要调试的查询字符串之前添加
<trace>关键字,可以在查询级别调试特定的查询。
性能考虑
本主题讨论了改进查询性能的考虑事项。
一些一般的性能提示:
- 通过创建索引尽可能地提高查询性能。有关使用索引的一些场景,请参见关于使用索引的提示和指南 。
- 为经常使用的查询使用绑定参数。当使用绑定参数时,查询只编译一次。这提高了查询在重新运行时的后续性能。有关详细信息,请参见使用查询绑定参数。
- 在查询分区区域时,使用FunctionService执行查询。该函数允许您针对特定的节点,这将通过避免查询分布大大提高性能。有关更多信息,请参见在单个节点上查询分区区域。
- 查询按键或字段值分区的数据时,请使用键索引。参见对按键或字段值分区的数据进行优化查询。
- 查询结果集的大小取决于查询的限制性和整个数据集的大小。分区区域可以容纳比其他类型的区域多得多的数据,因此分区区域查询的结果集更大的可能性更大。如果结果集非常大,这可能导致接收结果的成员耗尽内存。
查询时监视内存不足
查询监视功能防止在执行查询或创建索引时发生内存不足异常。
当您在cache.xml文件中给资源管理器元素设置一个critical-heap-percentage属性时,您将启用此功能。或者使用cache.getResourceManager().setCriticalHeapPercentage(float heapPercentage)的API。当启用此功能并由于运行查询或创建索引而导致堆内存使用超过阈值时,资源管理器将抛出异常并取消正在运行的查询或索引创建。
可以通过设置系统属性gemfire.cache.DISABLE_QUERY_MONITOR_FOR_LOW_MEMORY为true来显式禁用此功能。
当系统内存不足时,由cache.xml 文件中定义的临界堆百分比阈值决定。或者在getResourceManager API中,查询将抛出一个QueryExecutionLowMemoryException。正在创建的任何索引都将抛出一个InvalidIndexException,其中的消息指示原因。
分区区域查询和内存不足
分区区域查询可能是内存不足异常的原因。如果启用了查询监视,那么如果正在执行的服务器内存不足,分区区域查询将删除或忽略其他服务器正在收集的结果。
查询监视不处理在分区区域查询收集结果时展开低级收集的场景。例如,如果添加了一行,然后导致Java级别的集合或数组展开,那么可能会遇到内存不足异常。这种情况很少见,只有当集合大小本身在满足低内存条件之前扩展,然后扩展到剩余可用内存之外时,才有可能出现这种情况。作为一种变通方法,在遇到这种情况时,您可以通过降低critical-heap-percentage来优化系统。
长时间运行查询的超时
Geode可以在查询运行时间超过配置的时间时监视并抛出异常。通过设置critical-heap-percentage属性来启用该特性,该属性检测JVM的堆内存太少。
默认查询超时为5个小时。通过指定系统变量gemfire.cache.MAX_QUERY_EXECUTION_TIME来设置不同的时间量(以毫秒为单位)。值-1显式禁用超时。
当启用时,运行时间超过配置超时的查询将被取消,因此它不会完成,Geode将抛出一个QueryExecutionTimeoutException。
使用查询绑定参数
在Geode查询中使用查询绑定参数类似于在SQL中使用预置语句,在SQL中可以在查询执行期间设置参数。这允许用户一次构建查询,并在运行时通过传递查询条件多次执行查询。
查询对象是线程安全的。
在客户机到服务器的查询中,现在支持使用查询绑定参数。
查询参数由一个美元符号$标识,后面是一个数字,表示传递给execute方法的参数数组中的参数位置。计数从1开始,因此$1引用第一个绑定属性,$2引用第二个属性,依此类推。
查询接口提供了一个重载的执行方法,该方法接受对象数组中的参数。有关详细信息,请参见Query.execute JavaDocs。
对象数组的第0个元素用于第一个查询参数,等等。如果参数计数或参数类型与查询规范不匹配,则execute方法将抛出异常。具体地说,如果传入错误数量的参数,方法调用将抛出一个QueryParameterCountInvalidException。如果参数对象类型与预期的不兼容,方法调用将抛出一个TypeMismatchException。
在下面的示例中,第一个参数integer 2绑定到对象数组中的第一个元素。第二个参数active绑定到第二个元素。
示例代码
// specify the query string
String queryString = "SELECT DISTINCT * FROM /exampleRegion p WHERE p.id = $1 and p.status = $2";
QueryService queryService = cache.getQueryService();
Query query = queryService.newQuery(queryString);
// set query bind parameters
Object[] params = new Object[2];
params[0] = 2;
params[1] = "active";
// Execute the query locally. It returns the results set.
SelectResults results = (SelectResults) query.execute(params);
// use the results of the query; this example only looks at the size
int size = results.size();
在路径表达式中使用查询绑定参数
此外,查询引擎支持使用查询绑定参数代替区域路径。在查询的FROM子句中指定绑定参数时,参数的引用值必须绑定到集合。
例如,通过将集合作为查询参数值传入,可以对任何集合使用以下查询。在这个查询中,您可以以$1传入一个Region对象,但不能传入区域的字符串名称。
SELECT DISTINCT * FROM $1 p WHERE p.status = $2
查询分区的区域
Geode允许您使用分区区域跨分布式节点管理和存储大量数据。分区区域的基本存储单元是bucket,它驻留在Geode节点上,包含映射到单个hashcode的所有条目。在典型的分区区域查询中,系统将查询分布到所有节点上的所有bucket中,然后合并结果集并发回查询结果。
下面的列表总结了Geode支持的分区查询功能:
- 能够针对查询中的特定节点. 如果您知道特定的bucket包含您想要查询的数据,那么您可以使用一个函数来确保您的查询只运行保存数据的特定节点。这可以大大提高查询效率。只有在使用函数和在单个区域上执行函数时,才能查询特定节点上的数据。为此,您需要使用
Query.execute(RegionFunctionContext context)。参见Java API和查询单个节点上的分区区域 以获得更多详细信息。 - 使用关键索引优化分区区域查询性能的能力. 通过创建键索引,然后使用
Query.execute(RegionFunctionContext context)执行查询,可以提高按键或字段值分区的数据的查询性能,使用键或字段值作为筛选器.参见Java API和优化按键或字段值分区的数据查询以获得更多详细信息。 - 能够在分区区域之间以及分区区域和复制区域之间执行等连接查询. 通过函数服务支持分区区域之间以及分区区域和复制区域之间的连接查询。为了对分区区域或分区区域和复制区域执行等连接操作,必须对分区区域进行colocated,并且需要使用
Query.execute(RegionFunctionContext context)。参见Java API和在分区区域上执行等价连接查询以获得更多详细信息。 - 对分区区域使用ORDER BY
- 在单个节点上查询分区区域
- 优化按键或字段值分区的数据查询
- 对分区区域执行等连接查询
- 分区区域查询限制
对分区区域使用ORDER BY
要在分区区域上使用ORDER BY子句执行查询,ORDER BY子句中指定的字段必须是投影列表的一部分。
当将ORDER BY子句与分区区域查询一起使用时,将在每个区域主机、本地查询协调器和所有远程成员上分别执行查询。查询协调器收集所有结果。累积结果集是通过对收集到的结果应用ORDER BY来构建的。如果查询中也使用了LIMIT子句,那么在将每个节点的结果返回给协调器之前,ORDER BY和LIMIT将应用于每个节点。然后将子句应用于累积结果集以获得最终结果集,并将结果集返回给调用应用程序。
例子:
// This query works because p.status is part of projection list
select distinct p.ID, p.status from /region p where p.ID > 5 order by p.status
// This query works providing status is part of the value indicated by *
select distinct * from /region where ID > 5 order by status
在单个节点上查询分区区域
要将查询指向特定的分区区域节点,可以在函数中执行查询。使用以下步骤:
实现一个使用RegionFunctionContext执行查询的函数.
/** * This function executes a query using its RegionFunctionContext * which provides a filter on data which should be queried. * */ public class MyFunction extends FunctionAdapter { private final String id; @Override public void execute(FunctionContext context) { Cache cache = CacheFactory.getAnyInstance(); QueryService queryService = cache.getQueryService(); String qstr = (String) context.getArguments(); try { Query query = queryService.newQuery(qstr); //If function is executed on region, context is RegionFunctionContext RegionFunctionContext rContext = (RegionFunctionContext)context; SelectResults results = (SelectResults) query.execute(rContext) //Send the results to function caller node. context.getResultSender().sendResult((ArrayList) (results).asList()); context.getResultSender().lastResult(null); } catch (Exception e) { throw new FunctionException(e); } } @Override public boolean hasResult() { return true; } @Override public boolean isHA() { return false; } public MyFunction(String id) { super(); this.id = id; } @Override public String getId() { return this.id; } }决定要查询的数据。基于此决策,您可以使用
PartitionResolver配置要在分区区域中查询的bucket的组织。例如,假设您已经定义了PortfolioKey类:
public class PortfolioKey implements DataSerializable { private int id; private long startValidTime; private long endValidTime private long writtenTime public int getId() { return this.id; } ... }您可以使用
MyPartitionResolver将ID相同的所有键存储在同一个bucket中。这个PartitionResolver必须在分区区域创建时使用xml或api进行声明式配置。有关更多信息,请参见配置分区区域。/** This resolver returns the value of the ID field in the key. With this resolver, * all Portfolios using the same ID are colocated in the same bucket. */ public class MyPartitionResolver implements PartitionResolver, Declarable { public Serializable getRoutingObject(EntryOperation operation) { return operation.getKey().getId(); }通过在函数调用中设置筛选器,在客户端或任何其他节点上执行函数。
/** * Execute MyFunction for query on specified keys. * */ public class TestFunctionQuery { public static void main(String[] args) { ResultCollector rcollector = null; PortfolioKey portfolioKey1 = ...; //Filter data based on portfolioKey1 which is the key used in //region.put(portfolioKey1, portfolio1); Set filter = Collections.singleton(portfolioKey1); //Query to get all positions for portfolio ID = 1 String qStr = "SELECT positions FROM /myPartitionRegion WHERE ID = 1"; try { Function func = new MyFunction("testFunction"); Region region = CacheFactory.getAnyInstance().getRegion("myPartitionRegion"); //Function will be routed to one node containing the bucket //for ID=1 and query will execute on that bucket. rcollector = FunctionService .onRegion(region) .setArguments(qStr) .withFilter(filter) .execute(func); Object result = rcollector.getResult(); //Results from one or multiple nodes. ArrayList resultList = (ArrayList)result; List queryResults = new ArrayList(); if (resultList.size()!=0) { for (Object obj: resultList) { if (obj != null) { queryResults.addAll((ArrayList)obj); } } } printResults(queryResults); } catch (FunctionException ex) { getLogger().info(ex); } } }
优化按键或字段值分区的数据查询
您可以通过创建键索引,然后使用FunctionService和用作筛选器的键或字段值来执行查询,从而提高按键或字段值分区的数据的查询性能。
下面是一个如何优化将在按区域键值分区的数据上运行的查询的示例。在下面的示例中,数据由“orderId”字段分区。
在orderId字段上创建一个键索引。有关详细信息,请参见创建键索引。
使用orderId作为函数上下文的筛选器提供的函数服务执行查询。例如:
/** * Execute MyFunction for query on data partitioned by orderId key * */ public class TestFunctionQuery { public static void main(String[] args) { Set filter = new HashSet(); ResultCollector rcollector = null; //Filter data based on orderId = '12345' filter.add(12345); //Query to get all orders that match ID 12345 and amount > 1000 String qStr = "SELECT * FROM /Orders WHERE orderId = '12345' AND amount > 1000"; try { Function func = new MyFunction("testFunction"); Region region = CacheFactory.getAnyInstance().getRegion("myPartitionRegion"); //Function will be routed to one node containing the bucket //for ID=1 and query will execute on that bucket. rcollector = FunctionService .onRegion(region) .setArguments(qStr) .withFilter(filter) .execute(func); Object result = rcollector.getResult(); //Results from one or multiple nodes. ArrayList resultList = (ArrayList)result; List queryResults = new ArrayList(); if (resultList.size()!=0) { for (Object obj: resultList) { if (obj != null) { queryResults.addAll((ArrayList)obj); } } } printResults(queryResults); } catch (FunctionException ex) { getLogger().info(ex); } } }
对分区区域执行等连接查询
为了在分区区域或分区区域和复制区域上执行等连接操作,您需要使用 query.execute方法,并为其提供一个函数执行上下文。您需要使用Geode的FunctionService executor,因为在不提供函数执行上下文的情况下,分区区域还不直接支持连接操作。
有关分区区域查询限制的更多信息,请参见分区区域查询限制。
例如,假设您的等连接查询如下:
SELECT DISTINCT * FROM /QueryRegion1 r1,
/QueryRegion2 r2 WHERE r1.ID = r2.ID
在这个示例中,QueryRegion2与QueryRegion1一起使用,并且两个区域具有相同类型的数据对象。
服务器端:
Function prQueryFunction1 = new QueryFunction();
FunctionService.registerFunction(prQueryFunction1);
public class QueryFunction extends FunctionAdapter {
@Override
public void execute(FunctionContext context) {
Cache cache = CacheFactory.getAnyInstance();
QueryService queryService = cache.getQueryService();
ArrayList allQueryResults = new ArrayList();
ArrayList arguments = (ArrayList)(context.getArguments());
String qstr = (String)arguments.get(0);
try {
Query query = queryService.newQuery(qstr);
SelectResults result = (SelectResults)query
.execute((RegionFunctionContext)context);
ArrayList arrayResult = (ArrayList)result.asList();
context.getResultSender().sendResult((ArrayList)result.asList());
context.getResultSender().lastResult(null);
} catch (Exception e) {
// handle exception
}
}
}
在服务器端,Query.execute()对分区区域的本地数据进行操作。
客户端:
Function function = new QueryFunction();
String queryString = "SELECT DISTINCT * FROM /QueryRegion1 r1,
/QueryRegion2 r2 WHERE r1.ID = r2.ID";
ArrayList argList = new ArrayList();
argList.add(queryString);
Object result = FunctionService.onRegion(CacheFactory.getAnyInstance()
.getRegion("QueryRegion1" ))
.setArguments(argList).execute(function).getResult();
ArrayList resultList = (ArrayList)result;
resultList.trimToSize();
List queryResults = null;
if (resultList.size() != 0) {
queryResults = new ArrayList();
for (Object obj : resultList) {
if (obj != null ) {
queryResults.addAll((ArrayList)obj);
}
}
}
在客户端,注意您可以在调用FunctionService.onRegion()时指定桶过滤器。在这种情况下,查询引擎依赖FunctionService将查询定向到特定的节点。
关于使用Query.execute 和 RegionFunctionContext的附加说明
您还可以通过在客户端代码(FunctionService.onRegion(..). setarguments())中指定参数来向查询函数传递多个参数(除了查询本身)。然后您可以使用context.getArguments在服务器端处理函数内部的参数。请注意,指定参数的顺序并不重要,只要将服务器上的参数处理顺序与客户机中指定的顺序匹配即可。
分区区域查询限制
分区区域中的查询限制
分区区域查询的功能与非分区区域查询相同,但本节列出的限制除外。不遵循这些指导原则的分区区域查询将生成UnsupportedOperationException异常。
仅通过函数服务支持分区区域之间以及分区区域和复制区域之间的连接查询。客户端服务器API不支持分区的连接查询。
只有在分区区域和分区区域以及复制区域位于同一位置时,才能对它们运行连接查询。仅在共定位的分区区域以及查询的where子句中指示了共定位列的位置上支持等连接查询。对于多列分区,WHERE规范中还应该有AND子句。参见来自不同分区区域的Colocate数据了解关于分区区域共存位置的更多信息。
只要在所有分区区域节点上也存在本地复制区域,就允许在分区区域之间以及分区区域与本地复制区域之间进行等连接查询。要对一个分区区域和另一个分区(分区或不分区)执行连接查询,需要使用“查询”。方法,并为其提供一个函数执行上下文。参见在分区区域上执行等价连接查询作为示例。
查询必须只是一个SELECT表达式(与任意OQL表达式相反),前面必须有零个或多个IMPORT语句。例如,这个查询是不允许的,因为它不仅仅是一个SELECT表达式:
// NOT VALID for partitioned regions (SELECT DISTINCT *FROM /prRgn WHERE attribute > 10).size允许以下查询:
// VALID for partitioned regions SELECT DISTINCT * FROM /prRgn WHERE attribute > 10只要只引用一个分区区域,SELECT表达式本身可以是任意复杂的,包括嵌套的SELECT表达式。
分区区域引用只能在第一个FROM子句迭代器中。如果子句迭代器不引用任何区域,则允许使用额外的FROM子句迭代器(例如深入到分区区域中的值)。
第一个FROM子句迭代器必须只包含对分区区域的一个引用(该引用可以是参数,例如$1)。
第一个FROM子句迭代器不能包含子查询,但是在附加的FROM子句迭代器中允许子查询。
您可以在分区区域查询上使用ORDER BY,但是ORDER BY子句中指定的字段必须是投影列表的一部分。
如果查询的分区区域(或桶)已被销毁,则在销毁桶的新主服务器上重新尝试查询(如果存在的话)。在多次尝试之后,如果无法查询所有bucket(在查询启动时计算),则抛出QueryException。
查询调试
通过在要调试的查询字符串之前添加<trace>关键字,可以在查询级别调试特定的查询。
下面是一个例子:
<trace> select * from /exampleRegion
你也可以这样写:
<TRACE> select * from /exampleRegion
在执行查询时,Geode将在$GEMFIRE_DIR/system中记录一条消息。使用以下信息进行日志记录:
[info 2011/08/29 11:24:35.472 PDT CqServer <main> tid=0x1] Query Executed in 9.619656 ms; rowCount = 99; indexesUsed(0) "select * from /exampleRegion"
如果希望对所有查询启用调试,可以在启动时通过在命令行上设置系统属性来启用查询执行日志:
gfsh>start server --name=server_name -–J=-Dgemfire.Query.VERBOSE=true
或者你可以通过编程来设置属性:
System.setProperty("gemfire.Query.VERBOSE","true");
例如,假设您有一个EmployeeRegion,它将Employee对象作为值包含,并且对象中具有ID和status等公共字段。
Employee.java
Class Employee {
public int ID;
public String status;
- - - - - -
- - - - - -
}
此外,您还为该区域创建了以下索引:
<index name="sampleIndex-1">
<functional from-clause="/test " expression="ID"/>
</index>
<index name="sampleIndex-2">
<functional from-clause="/test " expression="status"/>
</index>
设置好gemfire.Query.VERBOSE为"true"之后。在EmployeeRegion或其索引上运行查询后,可以在日志中看到以下调试消息:
如果查询执行中没有使用索引,您将看到这样的调试消息:
[info 2011/08/29 11:24:35.472 PDT CqServer <main> tid=0x1] Query Executed in 9.619656 ms; rowCount = 99; indexesUsed(0) "select * from /test k where ID > 0 and status='active'"在查询执行中使用单一索引时,您可能会看到这样的调试消息:
[info 2011/08/29 11:24:35.472 PDT CqServer <main> tid=0x1] Query Executed in 101.43499 ms; rowCount = 199; indexesUsed(1):sampleIndex-1(Results: 199) "select count * from /test k where ID > 0"当查询使用多个索引时,您可能会看到这样的调试消息:
[info 2011/08/29 11:24:35.472 PDT CqServer <main> tid=0x1] Query Executed in 79.43847 ms; rowCount = 199; indexesUsed(2):sampleIndex-2(Results: 100),sampleIndex-1(Results: 199) "select * from /test k where ID > 0 OR status='active'"
在上述日志消息中,提供了以下信息:
- “rowCount” 表示查询的结果集大小。
- “indexesUsed(\n) ” 显示使用了n个索引来查找查询的结果。
- 分别报告每个索引名及其相应的结果。
- 可以使用最后附加的原始查询字符串标识日志。
使用索引
Geode查询引擎支持索引。索引可以为查询执行提供显著的性能收益。
查询在不借助索引的情况下运行,遍历集合中的每个对象。如果一个索引与部分或全部查询规范匹配,则查询仅在索引集上迭代,并且可以减少查询处理时间。
使用索引的提示和指南
使用索引优化查询需要一个仔细规划、测试和调优的周期。定义不良的索引会降低而不是改进查询的性能。本节给出查询服务中索引使用的指导原则。
创建、列出和删除索引
Geode ' QueryService ' API提供了创建、列出和删除索引的方法。您还可以使用
gfsh命令行界面创建、列出和删除索引,并使用cache.xml创建索引。创建键索引
在使用键或字段值对数据进行分区时,创建键索引是提高查询性能的好方法。您可以使用QueryService的
createKeyIndex方法创建键索引,也可以在cache.xml中定义索引。创建键索引使查询服务知道区域中的值与区域中的键之间的关系。创建哈希索引
不赞成使用哈希索引 Geode支持为执行基于平等的查询而创建哈希索引。
在映射字段上创建索引(“映射索引”)
为了帮助快速查找Map(或HashMap)类型字段中的多个值,可以在该字段中的特定(或所有)键上创建索引(有时称为“Map索引”)。
一次创建多个索引
为了在创建索引时提高速度和效率,可以定义多个索引,然后一次创建所有索引。
维护索引(同步或异步)和索引存储
索引与它们引用的区域数据自动保持同步。区域属性
IndexMaintenanceSynchronous指定在修改区域时同步更新区域索引,还是在后台线程中异步更新区域索引。使用查询索引提示
您可以使用hint关键字来允许Geode的查询引擎选择特定的索引。
在单个区域查询上使用索引
具有一个比较操作的查询可以使用键或范围索引进行改进,这取决于所比较的属性是否也是主键。
使用带有等连接查询的索引
相等连接查询是通过WHERE子句中的相等条件连接两个区域的查询。
使用带有溢出区域的索引
在查询溢出区域时可以使用索引;然而,也有一些警告。
在使用多个区域的等连接查询上使用索引
要跨多个区域查询,请标识所有等连接条件。然后,为相等连接条件创建尽可能少的索引,同时仍然连接所有区域。
索引样本
本主题提供用于创建查询索引的代码示例。
使用索引的提示和指南
使用索引优化查询需要一个仔细规划、测试和调优的周期。定义不良的索引会降低而不是改进查询的性能。本节给出查询服务中索引使用的指导原则。
在创建索引时,请记住以下几点:
- 索引会产生维护成本,因为当索引数据发生变化时,必须更新索引。与完全不使用索引相比,需要多次更新且不经常使用的索引可能需要更多的系统资源。
- 索引消耗内存。
- 索引对溢出区域的支持有限。有关详细信息,请参见使用带有溢出区域的索引。
- 如果要在同一区域上创建多个索引,请首先定义索引,然后一次创建所有索引,以避免在该区域上进行多次迭代。有关详细信息,请参见一次创建多个索引。
编写使用索引的查询的技巧
与在关系数据库上运行的查询处理器一样,查询的编写方式会极大地影响执行性能。此外,是否使用索引取决于如何声明每个查询。以下是优化Geode查询时需要考虑的一些问题:
- 通常,如果查询和索引的FROM子句完全匹配,那么索引将提高查询性能。
- 查询评估引擎没有复杂的基于成本的优化器。它有一个简单的优化器,可以根据索引大小和正在计算的操作符选择最佳索引(一个)或多个索引。
- 对于AND运算符,如果使用索引的条件和选择性更强的条件出现在查询中的其他条件之前,您可能会得到更好的结果。
- 索引不用于包含NOT的表达式中,因此在查询的WHERE子句中,
qty >= 10可以在qty上应用索引以提高效率。然而,NOT(qty < 10)不能应用相同的索引。 - 只要可能,提供提示,允许查询引擎选择特定的索引。参见使用查询索引提示
创建、列出和删除索引
Geode的QueryService API提供了创建、列出和删除索引的方法。您还可以使用gfsh命令行界面创建、列出和删除索引,并使用cache.xml创建索引。
创建索引
可以使用gfsh命令行接口或cache.xml以编程方式创建索引。
要创建索引,请使用以下QueryService方法之一:
createIndex. 创建索引的默认类型,范围索引。如果要编写执行除相等比较之外的任何比较操作的查询,请使用这种类型的索引。createKeyIndex. 创建键索引。有关更多信息,请参见创建键索引。- 弃用.
createHashIndex. 创建哈希索引。有关更多信息,请参见创建哈希索引。 createDefinedIndexes. 创建先前使用defineIndex定义的多个索引。有关更多信息,请参见一次创建多个索引。
以下部分提供了创建索引的示例:
使用 gfsh:
gfsh> create index --name=myIndex --expression=status --region=/exampleRegion
gfsh> create index --name=myKeyIndex --type=key --expression=id --region=/exampleRegion
更多示例请参见[Index Commands]https://geode.apache.org/docs/guide/17/tools_modules/gfsh/quick_ref_commands_by_area.html#topic_688C66526B4649AFA51C0F72F34FA45E)。
使用 Java API:
QueryService qs = cache.getQueryService();
qs.createIndex("myIndex", "status", "/exampleRegion");
qs.createKeyIndex("myKeyIndex", "id", "/exampleRegion");
使用 cache.xml:
<region name=exampleRegion>
<region-attributes . . . >
</region-attributes>
<index name="myIndex" from-clause="/exampleRegion" expression="status"/>
<index name="myKeyIndex" from-clause="/exampleRegion" expression="id" key-index="true"/>
...
</region>
注意: 如果没有指定缓存中的索引类型。类型默认为“range”。
列出索引
要从缓存或区域检索索引列表,请使用QueryService.getIndexes方法或gfsh命令行接口。
使用 gfsh:
gfsh> list indexes
gfsh> list indexes --with-stats
使用 Java API:
QueryService qs = cache.getQueryService();
qs.getIndexes(); //returns a collection of all indexes in the cache
qs.getIndexes(exampleRegion); //returns a collection of all indexes in exampleRegion
qs.getIndexes(exampleRegion, myKeyIndex); //returns the index named myKeyIndex from the exampleRegion
删除 Indexes
要从缓存或区域删除索引或所有索引,请使用QueryService.removeIndexes。方法或gfsh命令行接口。
使用 gfsh:
gfsh> destroy index
gfsh> destroy index --name=myIndex
gfsh> destroy index --region=/exampleRegion
使用 Java API:
QueryService qs = cache.getQueryService();
qs.removeIndexes(); //removes all indexes from the cache
qs.removeIndexes(myKeyIndex); //removes the index named myKeyIndex
qs.removeIndexes(exampleRegion); //removes all indexes from the exampleRegion
创建键索引
在使用键或字段值对数据进行分区时,创建键索引是提高查询性能的好方法。您可以使用QueryService的createKeyIndex方法创建键索引,也可以在cache.xml中定义索引。创建键索引使查询服务知道区域中的值与区域中的键之间的关系。
主键索引的FROM子句必须只是一个区域路径。索引表达式是一种表达式,当应用于条目值时,将生成键。例如,如果一个区域的值是portfolio,键是portfolio区域的id字段,那么索引表达式就是id。
然后可以使用FunctionService(使用分区键作为传递给函数的筛选器,并作为查询等式条件的一部分)对索引数据执行查询。参见根据键或字段值对数据分区进行优化查询以获得更多详细信息。
键索引有两个问题需要注意:
- 键索引没有排序。没有排序,您只能进行等式测试。其他比较是不可能的。要获得主键上的已排序索引,请在用作主键的属性上创建函数索引。
- 查询服务不能自动知道区域值和键之间的关系。为此,必须创建键索引。
注意: 在cache.xml中使用显式type=range的键索引将导致异常。键索引将不会在'range’查询中使用。
创建键索引的示例
使用 Java API:
QueryService qs = cache.getQueryService();
qs.createKeyIndex("myKeyIndex", "id", "/exampleRegion");
使用 gfsh:
gfsh> create index --name=myKeyIndex --expression=id --region=/exampleRegion
使用 cache.xml:
<region name=exampleRegion>
<region-attributes . . . >
</region-attributes>
<index name="myKeyIndex" from-clause="/exampleRegion" expression="id" key-index="true"/>
...
</region>
注意: 如果在使用缓存定义索引时没有指定索引的类型。类型默认为“range”。
创建哈希索引
不赞成使用哈希索引. Geode支持创建哈希索引,以执行基于平等的查询。
哈希索引的性能
使用哈希索引时,put操作的性能和恢复时间会比使用范围索引差。由于哈希索引的实现和根据请求重新计算密钥的成本,查询速度预计会变慢。哈希索引可以提高索引的内存使用。因此,必须权衡哈希索引空间节省的代价和它带来的性能损失。如果不考虑内存使用,建议使用范围索引。
考虑索引包含字符串字段时的内存使用情况。字符串的副本包含在索引中。使用哈希索引,索引表达式被规范化,并作为指向驻留在该区域中的对象的指针存储在索引中,从而使用更少的内存。测试可以减少高达30%的内存占用,但是节省的内存取决于所使用的键和数据。
性能考虑
限制
在创建哈希索引时,必须考虑以下限制:
- 只能对等于和不等于查询使用哈希索引。
- 由于同步的添加方法,哈希索引的维护将比其他索引慢。
- 不能异步维护哈希索引。如果您试图在一个将异步设置为维护模式的区域上创建散列索引,则会引发异常。
- 不能对具有多个迭代器或嵌套集合的查询使用哈希索引。
- 使用哈希索引会大大降低put操作性能和恢复时间。如果内存不是问题,那么使用范围索引而不是哈希索引。
创建哈希索引的示例
不赞成使用哈希索引。
使用 Java API:
QueryService qs = cache.getQueryService();
qs.createHashIndex("myHashIndex", "mktValue", "/exampleRegion");
使用 gfsh:
gfsh> create index --name=myHashIndex --expression=mktValue --region=/exampleRegion
--type=hash
使用 cache.xml:
<region name=exampleRegion>
<region-attributes . . . >
</region-attributes>
<index name="myHashIndex" from-clause="/exampleRegion p" expression="p.mktValue" type="hash"/>
...
</region>
在映射字段上创建索引(映射索引)
为了帮助快速查找Map(或HashMap)类型字段中的多个值,可以在该字段中的特定(或所有)键上创建索引(有时称为“Map索引”)。
例如,您可以创建一个映射索引来支持以下查询:
SELECT * FROM /users u WHERE u.name['first'] = 'John' OR u.name['last'] = 'Smith'
map索引扩展了在单个键上创建的常规范围索引,方法是为其他指定键或使用*时为所有键维护索引。映射索引的底层结构可以看作是所有这些索引的包装器。
下面的Java代码示例提供了如何创建映射索引的示例:
QueryService qs = cache.getQueryService();
//This will create indexes for for keys 'PVTL' and 'VMW'
qs.createIndex("indexName", "p.positions['PVTL', 'VMW']", "/portfolio p");
QueryService qs = cache.getQueryService();
//This will create indexes for all keys
qs.createIndex("indexName", "p.positions[*]", "/portfolio p");
在gfsh中,对等物为:
gfsh>create index --name="IndexName" --expression="p.positions['PVTL', 'VMW']" --region="/portfolio p"
gfsh>create index --name="IndexName" --expression="p.positions[*]" --region="/portfolio p"
为了创建或查询映射索引,必须使用方括号符号列出希望索引或查询的映射字段键。例如:[*], ['keyX1','keyX2’]。注意,使用p.pos.get('keyX1')将不会创建或查询映射索引。
注意: 您仍然可以查询Map或HashMap字段,而无需查询映射索引。例如,您总是可以在任意Map或HashMap字段中的单个键上创建常规的范围查询。但是,请注意,后续查询查找将仅限于单个键。
一次创建多个索引
为了在创建索引时提高速度和效率,可以定义多个索引,然后一次创建所有索引。
在创建多个索引之前定义它们,通过只迭代一次区域条目来加速索引创建过程。
通过在定义时指定 --type 参数,您可以一次定义不同类型的多个索引。
要定义多个索引,可以使用gfsh或Java API:
gfsh 例子:
gfsh> define index --name=myIndex1 --expression=exp1 --region=/exampleRegion
gfsh> define index --name=myIndex2 --expression="c.exp2" --region="/exampleRegion e, e.collection1 c"
gfsh> create defined indexes
如果索引创建失败,您可能会在gfsh中收到类似如下的错误消息:
gfsh>create defined indexes
Exception : org.apache.geode.cache.query.RegionNotFoundException ,
Message : Region ' /r3' not found: from /r3Occurred on following members
1. india(s1:17866)<v1>:27809
Java API 例子:
Cache cache = new CacheFactory().create();
QueryService queryService = cache.getQueryService();
queryService.defineIndex("name1", "indexExpr1", "regionPath1");
queryService.defineIndex("name2", "indexExpr2", "regionPath2");
queryService.defineKeyIndex("name4", "indexExpr4", "regionPath2");
List<Index> indexes = queryService.createDefinedIndexes();
如果一个或多个索引填充失败,Geode将收集异常并继续填充其余的索引。收集到的Exceptions存储在索引名和异常的映射中,可以通过MultiIndexCreationException访问这些索引名和异常。
索引定义存储在本地的gfsh客户机上。如果您想创建一组新索引,或者如果一个或多个索引创建失败,您可能希望使用 clear defined indexes命令清除存储的定义。定义的索引可以使用Java API清除:
queryService.clearDefinedIndexes();
或者 gfsh:
gfsh> clear defined indexes
维护索引(同步或异步)和索引存储
索引与它们引用的区域数据自动保持同步。区域属性indexmaintenancesyn指定在修改区域时同步更新区域索引,还是在后台线程中异步更新区域索引。
索引维护行为
异步索引维护将多个更新批处理到同一个区域键。默认模式是同步的,因为这提供了与区域数据的最大一致性。
参见 RegionFactory.setIndexMaintenanceSynchronous.
这个声明性索引创建将维护模式设置为异步:
<region-attributes index-update-type="asynchronous">
</region-attributes>
内部索引结构和存储
索引存储为基于索引表达式的紧凑或非紧凑数据结构(即使索引键类型相同)。例如,考虑以下乘客对象:
Passenger {
String name,
Date travelDate,
int age,
Flight flt,
}
Flight {
int flightId,
String origin,
String dest,
}
乘客姓名字段上的索引在缓存中的内存空间要求与航班起源字段不同,尽管它们都是字符串字段类型。Geode为索引存储选择的内部数据结构将取决于对象中的字段级别。在本例中,name是顶级字段,name上的索引可以存储为紧凑索引。由于origin是一个二级字段,任何使用origin作为索引表达式的索引都将作为非紧凑索引存储。
紧凑索引
紧凑索引具有简单的数据结构,以最小化其占用空间,代价是在索引维护方面做额外的工作。此索引不支持存储投影属性。
目前只选择紧凑索引,只支持在区域路径上创建索引。此外,还必须满足以下条件:
- 索引维护是同步的。
- 索引表达式是一个路径表达式。
- FROM子句只有一个迭代器。这意味着每个区域条目的索引中只有一个值,并且它直接位于区域值上(键、条目不支持)。
非紧凑索引
每当无法使用紧凑型索引时使用。
使用查询索引提示
您可以使用hint关键字来允许Geode的查询引擎选择特定的索引。
在查询中暗示索引的情况下,查询引擎过滤掉暗示索引(如果可能的话),然后从结果值中迭代和过滤。
例子:
<HINT 'IDIndex'> SELECT * FROM /Portfolios p WHERE p.ID > 10 AND p.owner = 'XYZ'
如果将多个索引作为提示添加,那么查询引擎将尝试使用尽可能多的索引,同时为提示索引提供一个首选项。
例子:
<HINT 'IDIndex', 'OwnerIndex'> SELECT * FROM /Portfolios p WHERE p.ID > 10 AND p.owner = 'XYZ' AND p.value < 100
在单个区域查询上使用索引
具有一个比较操作的查询可以使用键或范围索引进行改进,这取决于所比较的属性是否也是主键。
如果pkid是/exampleRegion区域的键,那么在pkid上创建键索引是最好的选择,因为键索引没有维护开销。如果pkid不是关键字,那么关于pkid的范围索引应该可以提高性能。
SELECT DISTINCT * FROM /exampleRegion portfolio WHERE portfolio.pkid = '123'
通过多个比较操作,可以在一个或多个属性上创建范围索引。试试以下:
- 在希望结果集大小最小的条件下创建单个索引。使用此索引检查性能。
- 保留第一个索引,在第二个条件下添加索引。添加第二个索引可能会降低性能。如果有,删除它,只保留第一个索引。查询中两个比较的顺序也会影响性能。一般来说,在OQL查询中,就像在SQL查询中一样,您应该对比较进行排序,以便前面的比较能够提供最少的结果来运行后续比较。
对于这个查询,您可以尝试对名称、年龄或两者都使用范围索引:
SELECT DISTINCT * FROM /exampleRegion portfolio WHERE portfolio.status = 'active' and portfolio.ID > 45
对于嵌套级别的查询,可以通过深入索引和查询中的较低级别来获得更好的性能。
这个查询深入到一个层次:
SELECT DISTINCT * FROM /exampleRegion portfolio, portfolio.positions.values positions where positions.secId = 'AOL' and positions.MktValue > 1
使用带有等连接查询的索引
相等连接查询是通过WHERE子句中的相等条件连接两个区域的查询。
使用索引与一个等连接查询:
为等连接条件的每一侧创建索引。查询引擎可以通过遍历左右两边索引的键来快速评估查询的等连接条件,以获得相等的匹配。
注意: 等连接查询需要常规索引。键索引不应用于等连接查询。
对于这个查询:
SELECT DISTINCT inv.name, ord.orderID, ord.status FROM /investors inv, /orders ord WHERE inv.investorID = ord.investorID创建两个索引:
| FROM clause | Indexed expression | | -------------- | ------------------ | | /investors inv | inv.investorID | | /orders ord | ord.investorID |
如果在具有等连接条件的查询中有额外的单区域查询,则仅当您能够为查询中的每个区域创建至少一个这样的索引时,才为单区域条件创建额外的索引。查询中区域子集上的任何索引都会降低性能。
对于该示例查询:
SELECT DISTINCT * FROM /investors inv, /securities sc, inv.heldSecurities inv_hs WHERE sc.status = "active" AND inv.name = "xyz" AND inv.age > 75 AND inv_hs.secName = sc.secName为等连接条件创建索引:
| FROM clause | Indexed expression | | ----------------------------------------- | ------------------ | | /investors inv, inv.heldSecurities inv_hs | inv_hs.secName | | /securities sc | sc.secName |
然后,如果您创建更多索引,请在
sc.status和inv.age或者inv.name上创建一个,或两者兼而有之。
使用带有溢出区域的索引
在查询溢出区域时可以使用索引;然而,也有一些警告。
以下是查询溢出区域的注意事项:
- 您必须对区域使用同步索引维护。这是默认的维护设置。
- index FROM子句必须只指定一个迭代器,并且它必须引用键或条目值。索引不能引用区域的entrySet。
- 索引数据本身没有存储在(溢出到)磁盘上。
例子:
下面的示例索引创建调用不适用于溢出区域。
// This index will not work on an overflow region because there are two iterators in the FROM clause.
createIndex("secIdIndex", "b.secId","/portfolios pf, pf.positions.values b");
// This index will not work on an overflow region because the FROM clause specifies the entrySet
createIndex("indx1", "entries.value.getID", "/exampleRegion.entrySet() entries");
下面的示例索引适用于溢出区域。
createIndex("pkidIndex", "p.pkid", "/Portfolios p");
createIndex("indx1", "ks.toString", "/portfolio.keySet() ks");
gfsh中的相同示例:
gfsh> create index -name="pkidIndex" --expression="p.pkid" --region="/Portfolios p"
gfsh> create index -name="indx1" --expression="ks.toString" --region="/portfolio.keySet() ks"
在使用多个区域的等连接查询上使用索引
要跨多个区域查询,请标识所有等连接条件。然后,为相等连接条件创建尽可能少的索引,同时仍然连接所有区域。
如果存在冗余连接两个区域的等连接条件(例如,为了更好地过滤数据),那么为这些连接创建冗余索引将对性能产生负面影响。为每个区域对仅在一个等连接条件下创建索引。
在这个示例查询中:
SELECT DISTINCT *
FROM /investors inv, /securities sc, /orders or,
inv.ordersPlaced inv_op, or.securities or_sec
WHERE inv_op.orderID = or.orderID
AND or_sec.secID = sc.secID
连接这些区域需要所有条件,因此需要创建四个索引,每个等连接条件创建两个索引:
| FROM clause | Indexed expression |
|---|---|
| /investors inv, inv.ordersPlaced inv_op | inv_op.orderID |
| /orders or, or.securities or_sec | or.orderID |
| FROM clause | Indexed expression |
|---|---|
| /orders or, or.securities or_sec | or_sec.secID |
| /securities sc | sc.secID |
在示例中添加另一个条件:
SELECT DISTINCT *
FROM /investors inv, /securities sc, /orders or,
inv.ordersPlaced inv_op, or.securities or_sec, sc.investors sc_invs
WHERE inv_op.orderID = or.orderID
AND or_sec.secID = sc.secID
AND inv.investorID = sc_invs.investorID
您仍然希望总共使用四个索引,因为这是连接所有区域所需的全部。你需要从以下三个索引对中选择性能最好的两个:
| FROM clause | Indexed expression |
|---|---|
| /investors inv, inv.ordersPlaced inv_op | inv_op.orderID |
| /orders or, or.securities or_sec | or.orderID |
| FROM clause | Indexed expression |
|---|---|
| /orders or, or.securities or_sec | or_sec.secID |
| /securities sc, sc.investors sc_invs | sc.secID |
| FROM clause | Indexed expression |
|---|---|
| /investors inv, inv.ordersPlaced inv_op | inv.investorID |
| /securities sc, sc.investors sc_invs | sc_invs.investorID |
最有效的性能集是将数据压缩到尽可能小的结果集。检查您的数据并使用这三个索引对进行试验,看看哪一个提供了最好的性能。
索引例子
本主题提供用于创建查询索引的代码示例。
// Key index samples. The field doesn't have to be present.
createKeyIndex("pkidIndex","p.pkid1","/root/exampleRegion p");
createKeyIndex("Index4","ID","/portfolios");
// Simple index
createIndex("pkidIndex","p.pkid","/root/exampleRegion p");
createIndex("i", "p.status", "/exampleRegion p")
createIndex("i", "p.ID", "/exampleRegion p")
createIndex("i", "p.position1.secId", "/exampleRegion p"
// On Set type
createIndex("setIndex","s","/root/exampleRegion p, p.sp s");
// Positions is a map
createIndex("secIdIndex","b.secId","/portfolios pf, pf.positions.values b");
//...
createIndex("i", "pf.collectionHolderMap[(pf.Id).toString()].arr[pf.ID]", "/exampleRegion pf")
createIndex("i", "pf.ID", "/exampleRegion pf", "pf.positions.values pos")
createIndex("i", "pos.secId", "/exampleRegion pf", "pf.positions.values pos")
createIndex("i", "e.value.getID()", "/exampleRegion.entrySet e")
createIndex("i", "e.value.ID", "/exampleRegion.entrySet e")
//...
createIndex("i", "entries.value.getID", "/exampleRegion.entrySet() entries")
createIndex("i", "ks.toString", "/exampleRegion.getKeys() ks")
createIndex("i", "key.status", "/exampleRegion.keys key")
createIndex("i", "secIds.length", "/exampleRegion p, p.secIds secIds")
createIndex("i", "secId", "/portfolios.asList[1].positions.values")
createIndex("i", "secId", "/portfolios['1'].positions.valules")
//Index on Map types
createIndex("i", "p.positions['key1']", "/exampleRegion p")
createIndex("i", "p.positions['key1','key2',key3',key7']", "/exampleRegion p")
createIndex("i", "p.positions[*]", "/exampleRegion p")
下面是一些关于索引的示例查询。
SELECT * FROM (SELECT * FROM /R2 m) r2, (SELECT * FROM /exampleRegion e WHERE e.pkid IN r2.sp) p
SELECT * FROM (SELECT * FROM /R2 m WHERE m.ID IN SET (1, 5, 10)) r2,
(SELECT * FROM /exampleRegion e WHERE e.pkid IN r2.sp) p
//examples using position index in the collection
SELECT * FROM /exampleRegion p WHERE p.names[0] = 'aaa'
SELECT * FROM /exampleRegion p WHERE p.position3[1].portfolioId = 2
SELECT DISTINCT positions.values.toArray[0], positions.values.toArray[0], status
FROM /exampleRegion
连续查询
连续查询持续返回与您设置的查询匹配的事件。
连续查询是如何工作的
客户端通过使用sql类型的查询过滤订阅服务器端事件。服务器发送修改查询结果的所有事件。CQ事件交付使用客户机/服务器订阅框架。
实现连续查询
在客户机中使用连续查询来接收对服务器上运行的查询的连续更新。
管理连续查询
本主题讨论CQ管理选项、CQ状态和检索初始结果集。
连续查询是如何工作的
客户端通过使用sql类型的查询过滤订阅服务器端事件。服务器发送修改查询结果的所有事件。CQ事件交付使用客户机/服务器订阅框架。
使用CQ,客户机向服务器端发送一个查询以供执行,并接收满足条件的事件。例如,在存储股票市场交易订单的区域中,您可以通过运行一个CQ查询来检索某个价格上的所有订单,查询如下:
SELECT * FROM /tradeOrder t WHERE t.price > 100.00
当CQ运行时,服务器向客户机发送影响查询结果的所有新事件。在客户端,由您编写的侦听器接收和处理传入的事件。对于这个关于/tradeOrder的查询示例,您可以编写一个侦听器来将事件推送到显示高价订单的GUI。CQ事件交付使用客户机/服务器订阅框架。
连续查询的逻辑架构
客户端可以执行任意数量的CQ,每个CQ分配任意数量的侦听器。
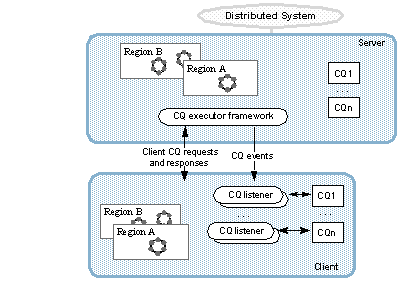
数据流与CQs
CQs不更新客户端区域。这与其他服务器到客户机的消息传递(如为满足兴趣注册而发送的更新和从客户机的“池”获取请求的响应)形成了对比。CQs作为CQ侦听器的通知工具,可以按照应用程序所需的任何方式对其进行编程。
当对服务器区域运行CQ时,更新服务器缓存的线程根据CQ查询计算每个条目事件。如果旧的或新的条目值满足查询,线程将在客户机的队列中放置一个CqEvent。CqEvent包含来自原始缓存事件的信息以及特定于CQ执行的信息。一旦客户端接收到CqEvent,它就被传递给为CQ定义的所有CqListener的onEvent方法。
下面是服务器缓存中更新条目的典型CQ数据流:
- 条目事件从服务器或其对等方到达服务器的缓存,从远程站点分发,或从客户端更新。
- 对于每个事件,服务器的CQ执行器框架将检查其与正在运行的CQ是否匹配。
- 如果旧条目值或新条目值满足CQ查询,则将CQ事件发送到客户端CQ的侦听器。CQ的每个侦听器都获得事件。
如下图所示:
- 条目X的新价格和旧价格都满足CQ查询,因此事件被发送,指示对查询结果的更新。
- 条目Y的旧价格满足查询,因此它是查询结果的一部分。条目Y的无效使得它不满足查询。因此,事件被发送,表明它在查询结果中被销毁。
- 新创建的条目Z的价格不满足查询,因此没有发送事件。
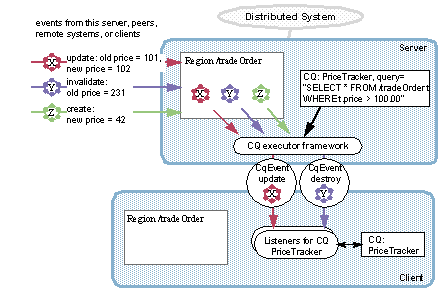
CQ 事件
CQ事件不会更改您的客户机缓存。它们仅作为事件服务提供。这允许您拥有任意cq集合,而无需在区域中存储大量数据。如果您需要从CQ事件中持久化信息,请编写侦听器来存储对应用程序最有意义的信息。
CqEvent对象包含以下信息:
- 输入键和新值。
- 在服务器中触发缓存事件的基本操作。这是GemFire中用于缓存事件的标准
Operation类实例。 CqQuery对象与此CQ事件关联。Throwable对象,只有在为缓存事件运行CqQuery时发生错误时才返回。这是非空的只有CqListeneronError调用。- 与此CQ事件关联的查询操作。此操作描述缓存事件对查询结果的影响。可能的值是:
CREATE, 对应于标准的数据库INSERT操作UPDATEDESTROY, 对应于标准的数据库DELETE删除操作
区域操作不转换为特定的查询操作,而查询操作也不特定地描述区域事件。相反,查询操作描述区域事件如何影响查询结果。
| 基于新旧条目值的查询操作 | 新值不满足查询 | 新值满足查询 |
|---|---|---|
| 旧值不满足查询 | 没有事件 | CREATE 查询操作 |
| 旧值确实满足查询 | DESTROY 查询操作 |
UPDATE 查询操作 |
您可以使用查询操作来决定如何处理侦听器中的CqEvent。例如,在屏幕上显示查询结果的CqListener可能会停止显示条目,开始显示条目,或者根据查询操作更新条目显示。
CQs的区域类型限制
您只能在复制或分区区域上创建CQs。如果您试图在未复制或未分区的区域上创建CQ,您将收到以下错误消息:
The region <region name> specified in CQ creation is neither replicated nor partitioned; only replicated or partitioned regions are allowed in CQ creation.
此外,您不能在具有local-destroy驱逐设置的复制区域上创建CQ,因为该驱逐设置更改了该区域的数据策略。如果您试图在这类区域上创建CQ,您将收到以下错误消息:
CQ is not supported for replicated region: <region name> with eviction action: LOCAL_DESTROY
还请参见配置分布式、复制和预加载区域,了解在复制区域上设置本地销毁回收的潜在问题。
实现连续查询
在客户机中使用连续查询来接收对服务器上运行的查询的连续更新。
CQs仅由客户端在其服务器上运行。
在开始之前,您应该熟悉查询并配置客户机/服务器系统。
将用于CQs的客户端池配置为
subscription-enabled,设置为true。要使CQ和兴趣订阅事件尽可能紧密地结合在一起,请为所有事件使用单个池。不同的池可能使用不同的服务器,这可能导致事件交付时间的更大差异。
编写OQL查询来从服务器检索所需的数据。
查询必须满足这些CQ要求,除了标准GemFire查询规范:
- FROM子句必须只包含一个区域规范,其中包含可选的iterator变量。
- 查询必须是一个SELECT表达式,前面必须有零个或多个IMPORT语句。这意味着查询不能是
/tradeOrder.name或"(SELECT * from /tradeOrder).size".之类的语句。 - CQ查询不能使用:
- 跨区域连接
- 向下钻取嵌套集合
- DISTINCT
- 预测
- 绑定参数
- 必须在分区或复制区域上创建CQ查询。参见CQs的区域类型限制。
CQ查询的基本语法是:
SELECT * FROM /fullRegionPath [iterator] [WHERE clause]此示例查询可用于获取价格超过$100的所有交易订单:
SELECT * FROM /tradeOrder t WHERE t.price > 100.00编写您的CQ侦听器来处理来自服务器的CQ事件。实现
org.apache.geode.cache.query.CqListener在您需要的每个事件处理程序中。除了您的主要CQ侦听器之外,您可能还有用于所有CQ的侦听器来跟踪统计信息或其他一般信息。注意: 如果选择从
CqListener更新缓存,请特别小心。如果侦听器更新在其自己的CQ中查询的区域,并且该区域有一个名为Pool的名称,则更新将被转发到服务器。如果服务器上的更新满足相同的CQ,那么它可能返回到执行更新的侦听器,这可能会将应用程序放入无限循环中。如果侦听器被编程来更新彼此的区域,那么可以使用多个区域和多个cq来执行相同的场景。这个示例概述了一个
CqListener,它可能用于使用来自服务器的当前数据更新显示屏幕。侦听器从CqEvent获取queryOperation和输入键和值,然后根据queryOperation的类型更新屏幕。// CqListener class public class TradeEventListener implements CqListener { public void onEvent(CqEvent cqEvent) { // org.apache.geode.cache Operation associated with the query op Operation queryOperation = cqEvent.getQueryOperation(); // key and new value from the event Object key = cqEvent.getKey(); TradeOrder tradeOrder = (TradeOrder)cqEvent.getNewValue(); if (queryOperation.isUpdate()) { // update data on the screen for the trade order . . . } else if (queryOperation.isCreate()) { // add the trade order to the screen . . . } else if (queryOperation.isDestroy()) { // remove the trade order from the screen . . . } } public void onError(CqEvent cqEvent) { // handle the error } // From CacheCallback public void close() { // close the output screen for the trades . . . } }安装侦听器并运行查询时,侦听器将处理所有CQ结果。
如果您需要CQs来检测它们是否连接到托管其订阅队列的任何服务器,请实现
CqStatusListener而不是CqListener。CqStatusListener扩展了当前的CqListener,允许客户端检测CQ何时连接和/或从服务器断开。onCqConnected()方法将在连接CQ时调用,在断开连接后重新连接CQ时调用。当CQ不再连接到任何服务器时,将调用oncqdisconnect()方法。以步骤3中的例子为例,我们可以实现一个
CqStatusListener:public class TradeEventListener implements CqStatusListener { public void onEvent(CqEvent cqEvent) { // org.apache.geode.cache Operation associated with the query op Operation queryOperation = cqEvent.getQueryOperation(); // key and new value from the event Object key = cqEvent.getKey(); TradeOrder tradeOrder = (TradeOrder)cqEvent.getNewValue(); if (queryOperation.isUpdate()) { // update data on the screen for the trade order . . . } else if (queryOperation.isCreate()) { // add the trade order to the screen . . . } else if (queryOperation.isDestroy()) { // remove the trade order from the screen . . . } } public void onError(CqEvent cqEvent) { // handle the error } // From CacheCallback public void close() { // close the output screen for the trades . . . } public void onCqConnected() { //Display connected symbol } public void onCqDisconnected() { //Display disconnected symbol } }当您安装
CqStatusListener时,您的侦听器将能够检测到它与所查询的服务器的连接状态。编程你的客户端运行CQ:
- 创建一个
CqAttributesFactory并使用它来设置您的CqListener和CqStatusListener。 - 将属性工厂、CQ查询及其惟一名称传递给
QueryService,以创建一个新的CqQuery。 - 通过调用
CqQuery对象上的一个执行方法来启动正在运行的查询。可以使用或不使用初始结果集执行。 - 当你完成了CQ,关闭它。
- 创建一个
连续查询实现
// Get cache and queryService - refs to local cache and QueryService
// Create client /tradeOrder region configured to talk to the server
// Create CqAttribute using CqAttributeFactory
CqAttributesFactory cqf = new CqAttributesFactory();
// Create a listener and add it to the CQ attributes callback defined below
CqListener tradeEventListener = new TradeEventListener();
cqf.addCqListener(tradeEventListener);
CqAttributes cqa = cqf.create();
// Name of the CQ and its query
String cqName = "priceTracker";
String queryStr = "SELECT * FROM /tradeOrder t where t.price > 100.00";
// Create the CqQuery
CqQuery priceTracker = queryService.newCq(cqName, queryStr, cqa);
try
{ // Execute CQ, getting the optional initial result set
// Without the initial result set, the call is priceTracker.execute();
SelectResults sResults = priceTracker.executeWithInitialResults();
for (Object o : sResults) {
Struct s = (Struct) o;
TradeOrder to = (TradeOrder) s.get("value");
System.out.println("Intial result includes: " + to);
}
}
catch (Exception ex)
{
ex.printStackTrace();
}
// Now the CQ is running on the server, sending CqEvents to the listener
. . .
// End of life for the CQ - clear up resources by closing
priceTracker.close();
使用连续查询,您可以选择性地实现:
- 通过为高可用性配置服务器来实现高可用性CQs。
- 通过为持久消息配置客户端,并指示哪些CQs在创建时是持久的,从而实现持久CQs。
管理连续查询
本主题讨论CQ管理选项、CQ状态和检索初始结果集。
使用RegionService实例中的CQs
如果您正在从RegionService实例中运行持久的客户端队列,那么应该停止并启动整个客户端的脱机事件存储。服务器为整个客户机进程管理一个队列,因此您需要通过ClientCache实例请求整个缓存的持久CQ事件消息传递的停止和开始。如果关闭RegionService实例,事件处理将停止,但服务器将继续发送事件,这些事件将丢失。
停止:
clientCache.close(true);
按以下顺序重新启动:
- 创建
ClientCache实例。 - 创建所有
RegionService实例。初始化CQ监听器。 - 调用
ClientCache实例的readyForEvents方法。
一个CQ的状态
CQ有三种可能的状态,它们在服务器上进行维护。您可以通过CqQuery.getState从客户端检查它们。
| 查询状态 | 这是什么意思? | 什么时候CQ达到这个状态? | 注释 |
|---|---|---|---|
| STOPPED | CQ已经就绪,可以运行了,但是没有运行。 | 当CQ第一次被创建和停止运行状态后。 | 停止的CQ使用系统资源。停止CQ只会停止从服务器到客户机的CQ事件消息传递。所有服务器端CQ处理都将继续,但是新的CQ事件不会被放置到服务器的客户机队列中。停止CQ不会改变客户端上的任何东西(当然,客户端会停止接收停止的CQ的事件)。 |
| RUNNING | CQ针对服务器区域事件运行,客户端侦听器等待CQ事件。 | 当CQ从停止状态执行时。 | 这是事件发送到客户机的唯一状态。 |
| CLOSED | CQ不能用于任何其他活动。您无法重新运行已关闭的CQ。 | 当客户端关闭CQ时,当缓存或连接条件使其无法维护或运行时。 | 关闭的CQ不使用系统资源。 |
CQ管理选项
从客户端管理CQs。所有调用都只针对调用客户机的CQs执行。
| 任务 | 对于单个CQ使用 … | 用于CQs组的使用 … |
|---|---|---|
| 创建一个 CQ | QueryService.newCq |
N/A |
| 执行一个 CQ | CqQuery.execute and CqQuery.executeWithInitialResults |
QueryService.executeCqs |
| 停止一个 CQ | CqQuery.stop |
QueryService.stopCqs |
| 关闭一个 CQ | CqQuery.close |
QueryService.closeCqs |
| 存取一个 CQ | CqEvent.getCq and QueryService.getCq |
QueryService.getCq |
| 修改 CQ Listeners | CqQuery.getCqAttributesMutator |
N/A |
| 访问CQ运行时统计数据 | CqQuery.getStatistics |
QueryService.getCqStatistics |
| 在服务器上注册所有持久CQs | N/A | QueryService.getAllDurableCqsFromServer |
使用gfsh管理CQs和持久客户端
使用gfsh命令行实用工具,您可以执行以下操作:
- 关闭持久客户端和持久客户端CQs。参见关闭。
- 列出给定持久客户端ID的所有持久CQs。参见List。
- 显示给定持久客户端ID的订阅事件队列大小。 参见 show subscription-queue-size.
检索CQ的初始结果集
在执行CQ时,可以选择检索初始结果集。为此,使用executeWithInitialResults方法执行CQ。返回的初始SelectResults与您在特别运行查询时通过在服务器缓存上执行调用QueryService.newQuery.execute得到的相同,但包含key。这个示例从初始结果集中检索键和值:
SelectResults cqResults = cq.executeWithInitialResults();
for (Object o : cqResults.asList()) {
Struct s = (Struct) o; // Struct with Key, value pair
Portfolio p = (Portfolio) s.get("value"); // get value from the Struct
String id = (String) s.get("key"); // get key from the Struct
}
如果您正在管理来自CQ结果的数据集,您可以通过遍历结果集并在事件到达时从侦听器更新结果集来初始化该数据集。例如,您可以使用初始结果填充新屏幕,然后从CQ侦听器更新屏幕。
如果使用ExecuteWithInitialResults方法执行CQ,返回的结果可能已经包含了与事件相关的更改。当CQ注册过程中该区域发生更新时,就会出现这种情况。CQ不会阻塞任何区域操作,因为它会影响区域操作的性能。将应用程序设计为在区域操作和CQ注册之间同步,以避免交付重复的事件。
事务
本节描述Geode事务。Geode为执行事务性工作的客户机应用程序提供了一个API。Geode使用熟悉的begin、commit和rollback方法实现乐观事务,这些方法实现与关系数据库事务方法相同的操作。
遵守ACID语义
本节解释Geode的乐观事务实现提供ACID语义的方式。
代码示例
基于应用程序的事务和嵌入在函数中的事务为建模提供了示例。
设计注意事项
超越基础的设计引入了其他考虑因素。本节标识并讨论事务如何与系统的其他方面交互。
遵守ACID语义
本节介绍Geode事务。Geode为执行事务性工作的客户机应用程序提供了一个API。Geode实现了乐观的事务,选择了它们提供的更高的事务性能,而不是传统关系数据库中缓慢的锁定方法。
乐观事务语义与传统关系数据库的原子-一致性-隔离-持久性(ACID)语义并不相同。
原子性
原子性是“全有或全无”的行为:只有当事务包含的所有操作都成功完成时,事务才会成功完成。如果在事务期间出现问题(可能是由于具有重叠更改的其他事务造成的),在问题解决之前,事务无法成功完成。
乐观事务通过使用预约系统提供原子性并实现速度,而不是使用传统的两阶段锁行关系数据库技术。这种保留阻止了其他交叉事务的完成,允许提交检查冲突,并在对数据进行更改之前以全有或全无的方式保留资源。在本地和远程完成所有更改之后,将释放预订。在预订系统中,交叉事务将被简单地丢弃。避免了获取锁的序列化。
一致性
一致性要求在事务中编写的数据必须遵守为受影响区域建立的键和值约束。请注意,事务的有效性是应用程序的责任。
隔离
隔离是事务状态对系统组件可见的级别。Geode事务具有可重复的读隔离。一旦为给定的键读取提交的值,它总是返回相同的值。如果事务中的写操作删除了已读取的键的值,则后续的读操作将返回事务引用。
默认配置在流程线程级别隔离事务。当一个事务正在进行时,它的更改只在运行该事务的线程中可见。同一进程中的其他线程和其他进程中的线程在提交操作开始之前不能看到更改。在开始提交之后,更改在缓存中是可见的,但是访问更改数据的其他线程可能会看到事务的部分结果,从而导致脏读。有关如何更改默认行为,请参见更改脏读的处理。
持久性
关系数据库通过使用磁盘存储进行恢复和事务日志记录来提供持久性。Geode针对性能进行了优化,不支持事务的磁盘持久性。
参见允许事务在持久区域上工作了解如何允许以非持久方式在持久区域上操作的事务。
代码示例
应用程序可以直接运行事务或调用包含事务的函数。本节用代码片段演示了这两个用例,这些代码片段演示了正确的事务编程方法。
预期的用例操作事务中的两个区域。出于性能目的,Geode事务实现要求对分区区域的区域项进行colocated。参见自定义分区和配置数据了解如何配置区域条目的详细信息。
应用程序中的事务
应用程序/客户机使用CacheTransactionManagerAPI。这段最基本的代码片段显示了事务的结构,以它的begin开始事务,commit结束事务,以及处理这些方法可能抛出的异常。
CacheTransactionManager txManager =
cache.getCacheTransactionManager();
try {
txManager.begin();
// ... do transactional, region operations
txManager.commit();
} catch (CommitConflictException conflict) {
// ... do necessary work for a transaction that failed on commit
} finally {
// All other exceptions will be handled by the caller.
// Examples of some exceptions: the data is not colocated, a rebalance
// interfered with the transaction, or the server is gone.
// Any exception thrown by a method other than commit() needs
// to do a rollback to avoid leaking the transaction state.
if(mgr.exists()) {
mgr.rollback();
}
}
下一个应用程序/客户端代码片段示例中将显示事务的更多细节。在这个典型的事务中,put操作必须是原子的,涉及两个区域。
在此交易中,记录客户的购买行为。现金区域包含每个客户可用来进行交易的现金余额。交易区域记录每个客户用于交易的余额。
如果事务提交时发生冲突,则抛出异常,本示例将再次尝试。
// inputs needed for this transaction; shown as variables for simplicity
final String customer = "Customer1";
final Integer purchase = 1000;
// region set up shown to promote understanding
Cache cache = new CacheFactory().create();
Pool pool = PoolManager.createFactory()
.addLocator("localhost", LOCATOR_PORT)
.create("pool-name");
Region<String, Integer> cash =
cache.createClientRegionFactory(ClientRegionShortcut.PROXY)
.setPoolName(pool.getName())
.create("cash");
Region<String, Integer> trades =
cache.createClientRegionFactory(ClientRegionShortcut.PROXY)
.setPoolName(pool.getName())
.create("trades");
// transaction code
CacheTransactionManager txmgr = cache.getCacheTransactionManager();
boolean retryTransaction = false;
do {
try {
txmgr.begin();
// Subtract out the cost of the trade for this customer's balance
Integer cashBalance = cash.get(customer);
Integer newBalance = (cashBalance != null ? cashBalance : 0) - purchase;
cash.put(customer, newBalance);
// Add in the cost of the trade for this customer
Integer tradeBalance = trades.get(customer);
newBalance = (tradeBalance != null ? tradeBalance : 0) + purchase;
trades.put(customer, newBalance);
txmgr.commit();
retryTransaction = false;
}
catch (CommitConflictException conflict) {
// entry value changed causing a conflict for this customer, so try again
retryTransaction = true;
} finally {
// All other exceptions will be handled by the caller.
// Any exception thrown by a method other than commit() needs
// to do a rollback to avoid leaking the transaction state.
if(mgr.exists()) {
mgr.rollback();
}
}
} while (retryTransaction);
设计事务,使任何get操作都在事务中。这将导致这些条目成为事务状态的一部分,这样就可以检测到交叉的事务并发出提交conficts的信号。
函数内的事务
事务可以嵌入到函数中。应用程序调用该函数,该函数包含执行begin、区域操作和commit或rollback的事务。
这种函数的使用可以带来性能上的好处。性能优势来自于驻留在服务器上的函数和区域数据。当该函数调用区域操作时,那些对区域条目的操作将保留在服务器上,因此不存在对区域数据执行get或put操作的网络往返时间。
这个函数示例在表示库存中可用产品数量的单个区域上完成原子更新。在事务中这样做可以防止为同时下单的两个订单重复分配库存。
/**
* Atomically reduce inventory quantity
*/
public class TransactionalFunction extends Function {
/**
* Returns true if the function had the requested quantity of
* inventory and successfully completed the transaction to
* record the reduced inventory that fulfills the order.
*/
@Override
public void execute(FunctionContext context) {
RegionFunctionContext rfc = (RegionFunctionContext) context;
Region<ProductId, Integer> inventoryRegion = rfc.getDataSet();
CacheTransactionManager
mgr = CacheFactory.getAnyInstance().getCacheTransactionManager();
// single argument will be a ProductId and a quantity
ProductRequest request = (ProductRequest) rfc.getArguments();
ProductId productRequested = request.getProductId();
Integer qtyRequested = request.getQuantity();
Boolean success = false;
do {
Boolean commitConflict = false;
try {
mgr.begin();
Integer qtyAvailable = inventoryRegion.get(productRequested);
Integer qtyRequested = request.getQuantity();
if (qtyAvail >= qtyRequested) {
// enough inventory is available, so process request
Integer remaining = qtyAvailable - qtyRequested;
inventoryRegion.put(productRequested, remaining);
success = true;
}
mgr.commit();
} catch (CommitConflictException conflict) {
// retry transaction, as another request on this same key succeeded,
// so this transaction attempt failed
commitConflict = true;
} finally {
// All other exceptions will be handled by the caller; however,
// any exception thrown by a method other than commit() needs
// to do a rollback to avoid leaking the transaction state.
if(mgr.exists()) {
mgr.rollback();
}
}
} while (commitConflict);
context.getResultSender().lastResult(success);
}
@Override
public String getId() {
return "TxFunction";
}
/**
* Returning true causes this function to execute on the server
* that holds the primary bucket for the given key. It can save a
* network hop from the secondary to the primary.
*/
@Override
public Boolean optimizeForWrite() {
return true;
}
}
本例中不讨论关于函数实现的应用程序端细节。应用程序设置函数上下文和参数。有关函数的详细信息,请参见[函数执行]一节(https://geode.apache.org/docs/guide/17/developing/function_exec/chapter_overview.html)。
函数实现需要捕获提交冲突异常,以便能够重试整个事务。只有当对同一产品的另一个请求与此产品相交,且该请求的事务首先提交时,才会出现异常。
定义optimizeForWrite方法是为了使系统在保存给定键的主桶的服务器上执行函数。它可以保存从辅助服务器到主服务器的网络跳转。
注意变量qtyAvailable是一个引用,因为Region.get操作返回服务器端代码中的引用。参见Region Operations Return References了解详细信息,以及在使用服务器代码时如何处理引用作为返回值的含义。
设计注意事项
包含更复杂特性的设计会引入更多的考虑。本节讨论事务如何与其他Geode特性交互。
- 按区域划分
- 区域操作返回引用
- 首先使用混合区域类型进行操作
- 允许事务在持久区域上工作
- 将事务与查询和索引混合在一起
- 将事务与驱逐混合在一起
- 将事务与过期混合
- 更改脏读的处理
按区域划分
为了提高性能,对多个分区区域进行操作的事务需要这些分区区域对其条目进行共定位。来自不同分区区域的Colocate数据描述了如何对条目进行Colocate。
区域操作返回引用
为了提高性能,服务器调用的区域操作返回对区域条目的引用。对该引用的任何赋值都会更改区域内的条目。这破坏了系统为处理程序(如缓存写入器和缓存加载器)维护一致性和回调链的能力。
使用在服务器上执行的事务中的引用更改条目具有相同的一致性问题,但更糟糕的是,更改不会被视为事务状态的一部分。
使用引用有两种方法:创建一个副本,或者配置系统返回副本而不是引用。让系统返回副本会带来性能损失。 这两种方法在安全条目修改中都有详细说明。
首先使用混合区域类型进行操作
当一个事务中有多个区域参与,且至少有一个分区和至少一个复制区域时,代码必须对分区区域执行第一次操作,以避免TransactionDataNotColocatedException。编写事务以在分区区域上执行其第一个操作,即使该操作是假的。
允许事务在持久区域上工作
Geode的原子事务实现禁止具有持久性的区域参与事务。在事务中对持久区域操作的调用会抛出一个UnsupportedOperationException异常和一条相关的消息
Operations on persist-backup regions are not allowed because this thread
has an active transaction
希望在事务期间允许对持久区域进行操作的应用程序可以设置此系统属性:
-Dgemfire.ALLOW_PERSISTENT_TRANSACTIONS=true
设置此系统属性可以消除异常。它不会改变事务提交时发生的磁盘写不强制原子性这一事实。提交期间的服务器崩溃可能在某些情况下成功,但不是所有的磁盘写操作都成功。
将事务与查询和索引混合在一起
查询和查询结果反映区域状态,而不是事务中发生的任何状态或更改。同样,索引的内容和更新不会与事务中的任何更改相交。因此,不要将事务与查询或索引区域混合。
将事务与驱逐混合在一起
LRU驱逐和事务可以很好地协作。从事务中操作的区域条目上的任何回收操作都将延迟到提交事务时才执行。此外,由于事务所接触的任何条目都已经重置了其LRU时钟,所以收回不太可能在提交之后立即选择这些条目作为受害者。
将事务与过期混合
事务禁用受事务影响的任何区域条目的过期。
更改脏读的处理
应用程序需要严格但较慢的隔离模型(比如不允许对过渡状态进行脏读),应该设置一个属性并将读操作封装在事务中。使用属性配置这个严格的隔离模型:
-Dgemfire.detectReadConflicts=true
此属性仅当读取一致的事务前或事务后状态时,才会导致读取操作成功。如果不一致,Geode抛出一个CommitConflictException异常。
函数执行
函数是驻留在服务器上的代码体,应用程序可以从客户机或另一台服务器调用它,而不需要发送函数代码本身。调用方可以指示依赖于数据的函数对特定数据集进行操作,也可以指示独立于数据的函数对特定服务器、成员或成员组进行操作。
函数执行服务为各种用例提供解决方案,包括:
- 应用程序需要对与key关联的数据执行操作。注册的服务器端函数可以检索数据、对其进行操作并将其返回,所有处理都在服务器本地执行。
- 应用程序需要在每个服务器上初始化一些组件,稍后执行的函数可能会使用这些组件。
- 第三方服务(如消息传递服务)需要初始化和启动。
- 任何任意聚合操作都需要对本地数据集进行迭代,可以通过对缓存服务器的一次调用更有效地进行迭代。
- 外部资源需要通过在服务器上执行函数来提供。
- 函数执行如何工作
- 在Apache Geode中执行一个函数
函数执行如何工作
函数在哪里执行
在Geode中,您可以在以下位置执行独立于数据的函数或依赖于数据的函数:
Data-independent函数
- 在一个或多个特定的成员上—在对等集群中执行函数,通过使用
FunctionService的方法onMember()和onMembers()指定希望在其中运行函数的成员。 - 在特定的服务器或服务器集上—如果作为客户机连接到集群,则可以在为特定连接池配置的服务器或服务器上执行该函数,或者在使用默认连接池连接到给定缓存的服务器或服务器上执行该函数。对于客户机/服务器架构上的独立于数据的函数,客户机调用
FunctionService的方法onServer()或onServers()。(有关池连接的详细信息,请参见客户机/服务器连接如何工作。) - 在成员组上或在每个成员组中的单个成员上—您可以将成员组织为逻辑成员组。(有关使用成员组的更多信息,请参见配置和运行集群。您可以对指定成员组或成员组中的所有成员调用独立于数据的函数,或者仅对每个指定成员组中的一个成员执行该函数。
对于依赖数据的函数
- 在一个区域上—如果您正在执行一个依赖于数据的函数,请指定一个区域和一组键(可选),在这些键上运行函数。方法
FunctionService.onRegion()指导依赖于数据的函数在特定区域上执行。
更多详细信息,请参阅FunctionService的Java API文档的org.apache.geode.cache.execute。
如何执行函数
在执行一个函数时,会发生以下情况:
- 对于启用安全的集群,在执行函数之前,要检查调用者是否被授权执行函数。授权所需的权限由函数的
function .getrequiredpermissions()方法提供。有关此方法的讨论,请参见函数执行的授权。 - 如果授权成功,Geode将在需要运行该函数的所有成员上调用该函数。位置由
FunctionService的on*方法调用、区域配置和任何筛选器确定。 - 如果函数有结果,则将结果返回给
ResultCollector对象中的addResult方法调用。 - 发起成员使用`ResultCollector.getResult收集结果。
高度可用的函数
通常,函数执行错误返回给调用应用程序。您可以为返回结果的onRegion函数编写高可用性代码,因此如果一个函数没有成功执行,Geode将自动重试该函数。您必须对函数进行编码和配置,使其具有高可用性,调用该函数的应用程序必须使用结果收集器getResult方法调用该函数。
当发生故障(如执行错误或执行时成员崩溃)时,系统的响应方式为:
- 等待所有调用返回
- 设置指示重新执行的布尔值
- 调用结果收集器的
clearResults方法 - 执行函数
对于客户端区域,系统根据org.apache.geode.cache.client.Pool retryAttempts重试执行。如果函数每次都不能运行,那么最后的异常将返回给getResult方法。
对于成员调用,系统将重试,直到成功或系统中没有数据保留以供函数操作为止。
函数执行场景
此图显示了从所有可用服务器上的客户机调用的独立于数据的函数的事件序列。
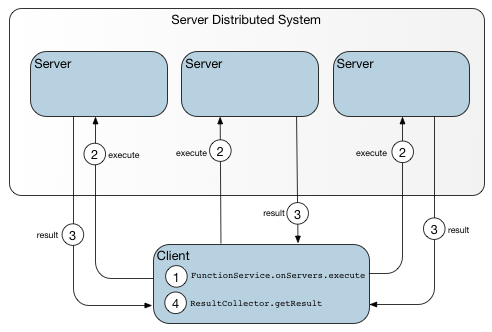
客户端联系定位器以获取集群中每个服务器的主机和端口标识符,并发出对每个服务器的调用。作为调用的发起者,客户机还接收调用结果。
此图显示了对对等集群中的成员执行的独立于数据的函数的事件序列。
您可以将onMembers()视为对onServers()的客户机-服务器调用的对等对等点。因为它是从集群中其他成员的对等点调用的,所以onMembers()函数调用可以访问详细的元数据,不需要定位器的服务。调用者调用函数本身(如果合适的话)以及集群中的其他成员,并收集所有函数执行的结果。
区域上的数据依赖函数 显示了在区域上运行的数据依赖函数。
图:一个区域的数据相关函数
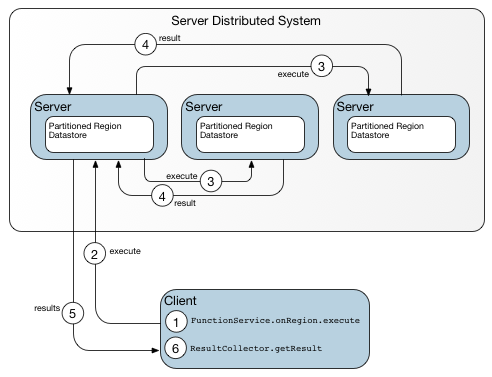
onRegion()调用需要比定位器在其主机:端口标识符中提供的更详细的元数据。此图显示了当客户机缺少关于目标位置的详细元数据(如第一次调用时)或以前获得的元数据不再是最新数据时所遵循的路径。
当客户机第一次调用要在集群的特定区域上执行的函数时,客户机对目标位置的了解仅限于定位器提供的主机和端口信息。由于只有这些有限的信息,客户机将其执行请求发送到下一个根据池分配算法将要调用的服务器。因为它是集群中的参与者,所以该服务器可以访问详细的元数据,并可以将函数调用分派到适当的目标位置。当服务器将结果返回给客户机时,它设置一个标志,指示对不同服务器的请求是否提供了到目标的更直接的路径。为了提高效率,客户机请求元数据的副本。关于区域bucket布局的其他详细信息,客户机可以在后续调用中充当自己的分派器,并为自己标识多个目标,从而消除至少一个跃点。
在获得当前元数据之后,客户机可以在后续调用中充当自己的分派器,为自己标识多个目标并消除一个跳转,如[获得当前元数据后依赖于数据的函数]所示(https://geode.apache.org/docs/guide/17/developing/function_exec/how_function_execution_works.html#how_function_execution_works__fig_data_dependent_function_obtaining_current_metadata)。
图:获取当前元数据后的数据相关函数
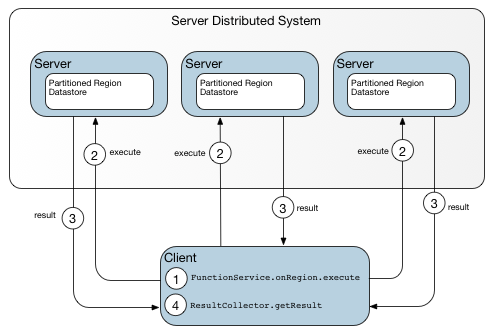
图:数据相关的函数,该函数依赖于带有键的区域
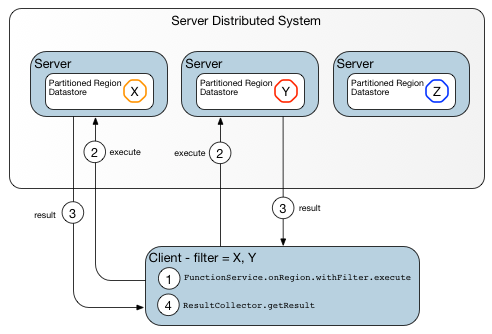
不保存任何key的服务器被排除在函数执行之外。
对等数据相关函数显示了一个对等数据相关调用。
图:点对点数据相关函数
调用者是集群的成员,而不是外部客户端,因此函数在调用者的集群中运行。请注意此图与前面的图(依赖于具有键的区域的数据函数之间的相似性),其中显示了一个客户机-服务器模型,其中客户机具有关于集群中目标位置的最新元数据。
具有最新目标元数据的客户机-服务器系统演示了在客户机-服务器系统中调用高可用函数的一系列步骤,其中客户机具有关于目标位置的最新元数据。
图:具有最新目标元数据的客户机-服务器系统
在本例中,三个主键(X, Y, Z)及其辅助副本(X ', Y ', Z ')分布在三个服务器之间。因为optimizeForWrite是true,系统首先尝试调用主键所在的函数:Server 1和Server 2。但是,假设服务器2由于某种原因离线,因此针对键Y的调用失败。因为isHA被设置为true,所以调用在服务器1(第一次成功,很可能会再次成功)和服务器3(键Y '所在)上重试。这一次,函数调用成功返回。对高可用函数的调用重试,直到获得成功的结果或达到重试限制。
在Apache Geode中执行一个函数
在这个过程中,假设您已经定义了想要运行函数的成员和区域。
主要任务:
- 编写函数代码。
- 在希望执行该函数的所有服务器上注册该函数。注册函数最简单的方法是使用
gfsh的deploy命令来部署包含函数代码的JAR文件。部署JAR会自动为您注册函数。有关详细信息,请参见通过部署JAR自动注册函数。或者,您可以编写XML或应用程序代码来注册函数。有关详细信息,请参见以编程方式注册函数。 - 编写应用程序代码以运行函数,如果函数返回结果,则处理结果。
- 如果函数返回结果,并且需要特殊的结果处理,那么编写一个定制的
ResultsCollector实现并在函数执行中使用它。
编写函数代码
要编写函数代码,您需要在org.apache.geode.cache中实现function接口。执行的方案。
编写函数所需的方法。这些步骤不必按此顺序执行。
- 实现
getId返回函数的唯一名称。您可以使用这个名称通过FunctionServiceAPI访问函数。 - 高可用性:
- 代码
isHa返回true,向Geode表明在一个或多个成员失败后,它可以重新执行您的函数 - 编写函数代码以返回结果
- 代码
hasResult返回true
- 代码
- 如果你的函数返回要处理的结果,则返回true;如果你的函数不返回任何数据,则返回false。
- 如果函数将在一个区域上执行,则实现
optimizeForWrite返回false(如果函数只从缓存中读取数据),如果函数更新缓存则返回true。该方法只有在运行函数时,通过FunctionServiceonRegion调用获得Execution对象时才有效。optimizeForWrite'默认返回false。 - 如果函数运行时的授权级别不是默认的
DATA:WRITE,则实现function.getrequiredpermissions()方法的覆盖。有关此方法的详细信息,请参见函数执行授权。 - 编写
execute方法来执行函数的工作。- 使
execute线程安全以适应同步调用。 - 对于高可用性,代码
execute可容纳对该函数的多个相同调用。使用RegionFunctionContextisPossibleDuplicate来确定调用是否是高可用性的重新执行。这个布尔值在执行失败时设置为true,否则为false。 注意: 可以在另一个成员执行函数失败后设置isPossibleDuplicate布尔值,因此它只表明执行可能是当前成员中的重复运行。 - 使用函数上下文获取关于执行和数据的信息:
- 上下文保存函数ID、用于将结果传递回发起者的
ResultSender对象,以及函数起源的成员提供的函数参数。 - 提供给该函数的上下文是
FunctionContext,如果通过FunctionServiceonRegion调用获得Execution对象,该上下文将自动扩展到RegionFunctionContext。 - 对于依赖于数据的函数,
RegionFunctionContext保存Region对象、键筛选器的Set和指示对该函数的多个相同调用的布尔值,以实现高可用性。 - 对于分区区域,
PartitionRegionHelper提供对该区域的其他信息和数据的访问。对于单个区域,使用getLocalDataForContext。对于被着色的区域,使用getLocalColocatedRegions。 注意: 当您使用PartitionRegionHelper.getLocalDataForContext时。如果您处理的是本地数据集而不是区域,则putIfAbsent可能不返回预期的结果。
- 上下文保存函数ID、用于将结果传递回发起者的
- 要将错误条件或异常传播回函数的调用方,请从
execute方法中抛出FunctionException。Geode将异常传递回调用方,就像它被抛出到调用方一样。有关[FunctionException]的更多信息,请参见[FunctionException]的Java API文档(https://geode.apache.org/releases/latest/javadoc/org/apache/geode/cache/execute/FunctionException.html)。
- 使
示例函数代码:
import java.io.Serializable;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import org.apache.geode.cache.execute.Function;
import org.apache.geode.cache.execute.FunctionContext;
import org.apache.geode.cache.execute.FunctionException;
import org.apache.geode.cache.execute.RegionFunctionContext;
import org.apache.geode.cache.partition.PartitionRegionHelper;
public class MultiGetFunction implements Function {
public void execute(FunctionContext fc) {
if(! (fc instanceof RegionFunctionContext)){
throw new FunctionException("This is a data aware function, and has
to be called using FunctionService.onRegion.");
}
RegionFunctionContext context = (RegionFunctionContext)fc;
Set keys = context.getFilter();
Set keysTillSecondLast = new HashSet();
int setSize = keys.size();
Iterator keysIterator = keys.iterator();
for(int i = 0; i < (setSize -1); i++)
{
keysTillSecondLast.add(keysIterator.next());
}
for (Object k : keysTillSecondLast) {
context.getResultSender().sendResult(
(Serializable)PartitionRegionHelper.getLocalDataForContext(context)
.get(k));
}
Object lastResult = keysIterator.next();
context.getResultSender().lastResult(
(Serializable)PartitionRegionHelper.getLocalDataForContext(context)
.get(lastResult));
}
public String getId() {
return getClass().getName();
}
}
通过部署JAR自动注册函数
当您部署包含函数(换句话说,包含实现函数接口的类)的JAR文件时,该函数将通过FunctionService.registerFunction方法自动注册。
使用gfsh注册函数:
将类文件打包到JAR文件中。
启动
gfsh提示符。如果需要,启动定位器并连接到要运行该函数的集群。在gfsh提示符下,键入以下命令:
gfsh>deploy --jar=group1_functions.jar其中group1_functions.jar对应于步骤1中创建的JAR文件。
如果使用相同的函数部署了另一个JAR文件(使用相同的JAR文件名或另一个文件名),则将注册该函数的新实现,覆盖旧的实现。如果一个JAR文件被取消部署,那么在部署时自动注册的任何函数都将被取消注册。由于多次部署具有相同名称的JAR文件会导致JAR被取消部署和重新部署,因此每次发生这种情况时,JAR中的函数都将被取消注册和重新注册。如果从多个不同名称的JAR文件中注册了具有相同ID的函数,那么如果其中一个JAR文件被重新部署或取消部署,那么该函数将被取消注册。
有关部署JAR文件的详细信息,请参见将应用程序JAR部署到Apache Geode成员。
以编程方式注册函数
本节适用于使用Execution.execute(String functionId)签名调用的函数。当调用此方法时,调用应用程序将函数ID发送到将要运行Function.execute的所有成员。接收成员使用ID在本地FunctionService中查找函数。为了进行查找,所有接收成员必须事先在函数服务中注册了函数。
另一种方法是“执行”签名。当调用此方法时,调用应用程序序列化Execution.execute(Function function)的实例并将其发送到运行Function.execute的所有成员。接收成员反序列化Function实例,创建它的新本地实例,并从中运行execute。此选项不适用于服务器上的非java客户端函数调用。
Java服务器必须注册由非Java客户机调用的函数。您可能希望在其他情况下使用注册,以避免成员之间发送Function实例的开销。
注册您的函数使用以下方法之一:
XML:
<cache> ... </region> <function-service> <function> <class-name>com.bigFatCompany.tradeService.cache.func.TradeCalc</class-name> </function> </function-service>Java:
myFunction myFun = new myFunction(); FunctionService.registerFunction(myFun);注意: 注册后修改函数实例对注册的函数没有影响。如果要执行新函数,必须使用不同的标识符注册它。
运行函数
这假设您已经遵循了编写和注册函数的步骤。
在需要显式执行函数并处理结果的每个成员中,可以使用gfsh命令行运行函数,也可以编写应用程序来运行函数。
使用gfsh运行函数
启动gfsh提示符。
如果需要,启动定位器并连接到要运行该函数的集群。
在gfsh提示符下,键入以下命令:
gfsh> execute function --id=function_id其中function_id等于分配给函数的唯一ID。您可以使用
Function.getId方法获得此ID。
有关函数的更多gfsh命令,请参见函数执行命令。
通过API调用运行函数
- 使用一个
FunctionServiceon*方法创建一个Execute对象。on*方法、onRegion、onMembers等定义函数运行的最高级别。对于经过colocated分区的区域,使用onRegion并指定任何一个经过colocated分区。使用onRegion运行的函数称为数据依赖函数,其他函数称为数据独立函数。 - 根据需要使用
Execution对象进行额外的函数配置。您可以:- 提供一个键
SettowithFilters来缩小onRegionexecution对象的执行范围。您可以通过RegionFunctionContext.getFilter检索Functionexecute方法中的键集。 - 为
setArguments提供函数参数。您可以通过FunctionContext.getArguments在Functionexecute方法中检索这些内容。 - 定义一个自定义的
ResultCollector
- 提供一个键
- 调用
execute对象以execute方法运行函数。 - 如果函数返回结果,则从
execute返回的结果收集器调用getResult,并编写应用程序代码来处理结果。注意: 实现高可用性,您必须调用getResult方法。
运行函数的例子-执行成员:
MultiGetFunction function = new MultiGetFunction();
FunctionService.registerFunction(function);
writeToStdout("Press Enter to continue.");
stdinReader.readLine();
Set keysForGet = new HashSet();
keysForGet.add("KEY_4");
keysForGet.add("KEY_9");
keysForGet.add("KEY_7");
Execution execution = FunctionService.onRegion(exampleRegion)
.withFilter(keysForGet)
.setArguments(Boolean.TRUE)
.withCollector(new MyArrayListResultCollector());
ResultCollector rc = execution.execute(function);
// Retrieve results, if the function returns results
List result = (List)rc.getResult();
编写自定义结果收集器
本主题适用于返回结果的函数。
当您执行一个返回结果的函数时,该函数将结果存储到ResultCollector中,并返回ResultCollector对象。然后调用应用程序可以通过ResultCollector getResult方法检索结果。例子:
ResultCollector rc = execution.execute(function);
List result = (List)rc.getResult();
Geode的默认ResultCollector将所有结果收集到一个ArrayList中。它的getResult方法阻塞,直到收到所有结果。然后返回完整的结果集。
定制结果收集:
编写一个扩展
ResultCollector的类,并根据需要编写存储和检索结果的方法。注意,这些方法有两种类型:- 当
Function实例SendResults方法的结果到达时,Geode调用addResult和endResults getResult可用于正在执行的应用程序(调用Execute .execute的应用程序)检索结果
- 当
使用高可用性的
onRegion功能,已为其编码:- 编写
ResultCollectorclearResults方法的代码,以删除任何部分结果数据。这为重新执行干净的函数做好了准备。 - 当您调用该函数时,调用结果收集器
getResult方法。这支持高可用性功能。
- 编写
在调用函数执行的成员中,使用
withCollector方法创建Execution对象,并将其传递给自定义收集器。例子:Execution execution = FunctionService.onRegion(exampleRegion) .withFilter(keysForGet) .setArguments(Boolean.TRUE) .withCollector(new MyArrayListResultCollector());
针对成员组中的单个成员或整个成员组
要在一组成员或一组成员中的一个成员上执行独立于数据的函数,可以编写自己的嵌套函数。如果从客户机到服务器执行一个函数,则需要编写一个嵌套函数;如果从服务器到所有成员执行一个函数,则需要编写另一个嵌套函数。
[id]: