基础入门
Elasticsearch 是一个实时的分布式搜索分析引擎, 它能让你以一个之前从未有过的速度和规模,去探索你的数据。 它被用作全文检索、结构化搜索、分析以及这三个功能的组合:
- Wikipedia 使用 Elasticsearch 提供带有高亮片段的全文搜索,还有 search-as-you-type 和 did-you-mean 的建议。
- 卫报 使用 Elasticsearch 将网络社交数据结合到访客日志中,实时的给它的编辑们提供公众对于新文章的反馈。
- Stack Overflow 将地理位置查询融入全文检索中去,并且使用 more-like-this 接口去查找相关的问题与答案。
- GitHub 使用 Elasticsearch 对1300亿行代码进行查询。
然而 Elasticsearch 不仅仅为巨头公司服务。它也帮助了很多初创公司,像 Datadog 和 Klout, 帮助他们将想法用原型实现,并转化为可扩展的解决方案。Elasticsearch 能运行在你的笔记本电脑上,或者扩展到上百台服务器上去处理PB级数据。
Elasticsearch 中没有一个单独的组件是全新的或者是革命性的。全文搜索很久之前就已经可以做到了, 就像早就出现了的分析系统和分布式数据库。 革命性的成果在于将这些单独的,有用的组件融合到一个单一的、一致的、实时的应用中。它对于初学者而言有一个较低的门槛, 而当你的技能提升或需求增加时,它也始终能满足你的需求。
如果你现在打开这本书,是因为你拥有数据。除非你准备使用它 做些什么 ,否则拥有这些数据将没有意义。
不幸的是,大部分数据库在从你的数据中提取可用知识时出乎意料的低效。 当然,你可以通过时间戳或精确值进行过滤,但是它们能够进行全文检索、处理同义词、通过相关性给文档评分么? 它们从同样的数据中生成分析与聚合数据吗?最重要的是,它们能实时地做到上面的那些而不经过大型批处理的任务么?
这就是 Elasticsearch 脱颖而出的地方:Elasticsearch 鼓励你去探索与利用数据,而不是因为查询数据太困难,就让它们烂在数据仓库里面。
Elasticsearch 将成为你最好的朋友。
你知道的, 为了搜索…
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库--无论是开源还是私有。
但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
Elasticsearch 将所有的功能打包成一个单独的服务,这样你可以通过程序与它提供的简单的 RESTful API 进行通信, 可以使用自己喜欢的编程语言充当 web 客户端,甚至可以使用命令行(去充当这个客户端)。
就 Elasticsearch 而言,起步很简单。对于初学者来说,它预设了一些适当的默认值,并隐藏了复杂的搜索理论知识。 它 开箱即用 。只需最少的理解,你很快就能具有生产力。
随着你知识的积累,你可以利用 Elasticsearch 更多的高级特性,它的整个引擎是可配置并且灵活的。 从众多高级特性中,挑选恰当去修饰的 Elasticsearch,使它能解决你本地遇到的问题。
你可以免费下载,使用,修改 Elasticsearch。它在 Apache 2 license 协议下发布的, 这是众多灵活的开源协议之一。Elasticsearch 的源码被托管在 Github 上 github.com/elastic/elasticsearch。 如果你想加入我们这个令人惊奇的 contributors 社区,看这里 Contributing to Elasticsearch。
如果你对 Elasticsearch 有任何相关的问题,包括特定的特性(specific features)、语言客户端(language clients)、插件(plugins),可以在这里 discuss.elastic.co 加入讨论。
回忆时光
许多年前,一个刚结婚的名叫 Shay Banon 的失业开发者,跟着他的妻子去了伦敦,他的妻子在那里学习厨师。 在寻找一个赚钱的工作的时候,为了给他的妻子做一个食谱搜索引擎,他开始使用 Lucene 的一个早期版本。
直接使用 Lucene 是很难的,因此 Shay 开始做一个抽象层,Java 开发者使用它可以很简单的给他们的程序添加搜索功能。 他发布了他的第一个开源项目 Compass。
后来 Shay 获得了一份工作,主要是高性能,分布式环境下的内存数据网格。这个对于高性能,实时,分布式搜索引擎的需求尤为突出, 他决定重写 Compass,把它变为一个独立的服务并取名 Elasticsearch。
第一个公开版本在2010年2月发布,从此以后,Elasticsearch 已经成为了 Github 上最活跃的项目之一,他拥有超过300名 contributors(目前736名 contributors )。 一家公司已经开始围绕 Elasticsearch 提供商业服务,并开发新的特性,但是,Elasticsearch 将永远开源并对所有人可用。
据说,Shay 的妻子还在等着她的食谱搜索引擎…
安装并运行Elasticsearch
想用最简单的方式去理解 Elasticsearch 能为你做什么,那就是使用它了,让我们开始吧!
安装 Elasticsearch 之前,你需要先安装一个较新的版本的 Java,最好的选择是,你可以从 www.java.com 获得官方提供的最新版本的 Java。
之后,你可以从 elastic 的官网 elastic.co/downloads/elasticsearch 获取最新版本的 Elasticsearch。
要想安装 Elasticsearch,先下载并解压适合你操作系统的 Elasticsearch 版本。如果你想了解更多的信息, 可以查看 Elasticsearch 参考手册里边的安装部分,这边给出的链接指向安装说明 Installation。
当你准备在生产环境安装 Elasticsearch 时,你可以在 官网下载地址 找 到 Debian 或者 RPM 包,除此之外,你也可以使用官方支持的 Puppet module 或者 Chef cookbook。
当你解压好了归档文件之后,Elasticsearch 已经准备好运行了。按照下面的操作,在前台(foregroud)启动 Elasticsearch:
cd elasticsearch-<version>
./bin/elasticsearch <1> <2>
如果你想把 Elasticsearch 作为一个守护进程在后台运行,那么可以在后面添加参数
-d。
如果你是在 Windows 上面运行 Elasticseach,你应该运行
bin\elasticsearch.bat而不是bin\elasticsearch。
测试 Elasticsearch 是否启动成功,可以打开另一个终端,执行以下操作:
curl 'http://localhost:9200/?pretty'
TIP:如果你是在 Windows 上面运行 Elasticsearch,你可以从 http://curl.haxx.se/download.html 中下载 cURL。 cURL 给你提供了一种将请求提交到 Elasticsearch 的便捷方式,并且安装 cURL 之后,你可以通过复制与粘贴去尝试书中的许多例子。
你应该得到和下面类似的响应(response):
{
"name" : "Tom Foster",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}
这就意味着你现在已经启动并运行一个 Elasticsearch 节点了,你可以用它做实验了。 单个 节点 可以作为一个运行中的 Elasticsearch 的实例。 而一个 集群 是一组拥有相同 cluster.name 的节点, 他们能一起工作并共享数据,还提供容错与可伸缩性。(当然,一个单独的节点也可以组成一个集群) 你可以在 elasticsearch.yml 配置文件中 修改 cluster.name ,该文件会在节点启动时加载 (译者注:这个重启服务后才会生效)。 关于上面的 cluster.name 以及其它 Important Configuration Changes 信息, 你可以在这本书后面提供的生产部署章节找到更多。
TIP:看到下方的 View in Sense 的例子了么?Install the Sense console 使用你自己的 Elasticsearch 集群去运行这本书中的例子, 查看会有怎样的结果。
当 Elastcisearch 在前台运行时,你可以通过按 Ctrl+C 去停止。
安装Sense
Sense 是一个 Kibana 应用 它提供交互式的控制台,通过你的浏览器直接向 Elasticsearch 提交请求。 这本书的在线版本包含有一个 View in Sense 的链接,里面有许多代码示例。当点击的时候,它会打开一个代码示例的Sense控制台。 你不必安装 Sense,但是它允许你在本地的 Elasticsearch 集群上测试示例代码,从而使本书更具有交互性。
安装与运行 Sense:
在 Kibana 目录下运行下面的命令,下载并安装 Sense app:
./bin/kibana plugin --install elastic/sense <1> Windows上面执行: bin\kibana.bat plugin --install elastic/sense。NOTE:你可以直接从这里 https://download.elastic.co/elastic/sense/sense-latest.tar.gz下载 Sense 离线安装可以查看这里 install it on an offline machine 。启动 Kibana.
./bin/kibana <1> Windows 上启动 kibana: bin\kibana.bat。在你的浏览器中打开 Sense:
http://localhost:5601/app/sense。
和Elasticsearch交互
和 Elasticsearch 的交互方式取决于 你是否使用 Java
Java API
如果你正在使用 Java,在代码中你可以使用 Elasticsearch 内置的两个客户端:
节点客户端(Node client)
节点客户端作为一个非数据节点加入到本地集群中。换句话说,它本身不保存任何数据,但是它知道数据在集群中的哪个节点中,并且可以把请求转发到正确的节点。
传输客户端(Transport client)
轻量级的传输客户端可以将请求发送到远程集群。它本身不加入集群,但是它可以将请求转发到集群中的一个节点上。
两个 Java 客户端都是通过 9300 端口并使用 Elasticsearch 的原生 传输 协议和集群交互。集群中的节点通过端口 9300 彼此通信。如果这个端口没有打开,节点将无法形成一个集群。
更多的 Java 客户端信息可以在 Elasticsearch Clients 中找到。
RESTful API with JSON over HTTP
所有其他语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信,你可以用你最喜爱的 web 客户端访问 Elasticsearch 。事实上,正如你所看到的,你甚至可以使用 curl 命令来和 Elasticsearch 交互。
Elasticsearch 为以下语言提供了官方客户端 --Groovy、JavaScript、.NET、 PHP、 Perl、 Python 和 Ruby--还有很多社区提供的客户端和插件,所有这些都可以在 Elasticsearch Clients 中找到。
一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
被 < > 标记的部件:
VERB |
适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE。 |
|---|---|
PROTOCOL |
http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理) |
HOST |
Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
PORT |
运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
PATH |
API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
QUERY_STRING |
任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
BODY |
一个 JSON 格式的请求体 (如果请求需要的话) |
例如,计算集群中文档的数量,我们可以用这个:
curl -XGET 'http://localhost:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
}
'
Elasticsearch 返回一个 HTTP 状态码(例如:200 OK)和(除HEAD请求)一个 JSON 格式的返回值。前面的 curl 请求将返回一个像下面一样的 JSON 体:
{
"count" : 0,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
}
}
在返回结果中没有看到 HTTP 头信息是因为我们没有要求curl显示它们。想要看到头信息,需要结合 -i 参数来使用 curl 命令:
curl -i -XGET 'localhost:9200/'
在书中剩余的部分,我们将用缩写格式来展示这些 curl 示例,所谓的缩写格式就是省略请求中所有相同的部分,例如主机名、端口号以及 curl 命令本身。而不是像下面显示的那样用一个完整的请求:
curl -XGET 'localhost:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
}'
我们将用缩写格式显示:
GET /_count
{
"query": {
"match_all": {}
}
}
事实上, Sense 控制台 也使用这样相同的格式。如果你正在阅读这本书的在线版本,可以通过点击 Sense 链接视图在 Sense 上打开和运行示例代码。
面向文档
在应用程序中对象很少只是一个简单的键和值的列表。通常,它们拥有更复杂的数据结构,可能包括日期、地理信息、其他对象或者数组等。
也许有一天你想把这些对象存储在数据库中。使用关系型数据库的行和列存储,这相当于是把一个表现力丰富的对象挤压到一个非常大的电子表格中:你必须将这个对象扁平化来适应表结构--通常一个字段>对应一列--而且又不得不在每次查询时重新构造对象。
Elasticsearch 是 面向文档 的,意味着它存储整个对象或 文档。Elasticsearch 不仅存储文档,而且 索引每个文档的内容使之可以被检索。在 Elasticsearch 中,你 对文档进行索引、检索、排序和过滤--而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。
JSON
Elasticsearch 使用 JavaScript Object Notation 或者 JSON 作为文档的序列化格式。JSON 序列化被大多数编程语言所支持,并且已经成为 NoSQL 领域的标准格式。 它简单、简洁、易于阅读。
考虑一下这个 JSON 文档,它代表了一个 user 对象:
{
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": [ "dolphins", "whales" ]
},
"join_date": "2014/05/01"
}
虽然原始的 user 对象很复杂,但这个对象的结构和含义在 JSON 版本中都得到了体现和保留。在 Elasticsearch 中将对象转化为 JSON 并做索引要比在一个扁平的表结构中做相同的事情简单的多。
适应新环境
为了对 Elasticsearch 能实现什么及其上手容易程度有一个基本印象,让我们从一个简单的教程开始并介绍索引、搜索及聚合等基础概念。
我们将一并介绍一些新的技术术语和基础概念,因此即使无法立即全盘理解也无妨。在本书后续内容中,我们将深入介绍这里提到的所有概念。
接下来尽情享受 Elasticsearch 探索之旅。
创建一个雇员目录
我们受雇于 Megacorp 公司,作为 HR 部门新的 “热爱无人机” ("We love our drones!")激励项目的一部分,我们的任务是为此创建一个雇员目录。该目录应当能培养雇员认同感及支持实时、高效、动态协作,因此有一些业务需求:
- 支持包含多值标签、数值、以及全文本的数据
- 检索任一雇员的完整信息
- 允许结构化搜索,比如查询 30 岁以上的员工
- 允许简单的全文搜索以及较复杂的短语搜索
- 支持在匹配文档内容中高亮显示搜索片段
- 支持基于数据创建和管理分析仪表盘
索引雇员文档
第一个业务需求就是存储雇员数据。 这将会以 雇员文档 的形式存储:一个文档代表一个雇员。存储数据到 Elasticsearch 的行为叫做 索引 ,但在索引一个文档之前,需要确定将文档存储在哪里。
一个 Elasticsearch 集群可以 包含多个 索引 ,相应的每个索引可以包含多个 类型 。 这些不同的类型存储着多个 文档 ,每个文档又有 多个 属性 。
Index Versus Index Versus Index
你也许已经注意到 索引 这个词在 Elasticsearch 语境中包含多重意思, 所以有必要做一点儿说明:
索引(名词):
如前所述,一个 索引 类似于传统关系数据库中的一个 数据库 ,是一个存储关系型文档的地方。 索引 (index) 的复数词为 indices 或 indexes 。
索引(动词):
索引一个文档 就是存储一个文档到一个 索引 (名词)中以便它可以被检索和查询到。这非常类似于 SQL 语句中的
INSERT关键词,除了文档已存在时新文档会替换旧文档情况之外。倒排索引:
关系型数据库通过增加一个 索引 比如一个 B树(B-tree)索引 到指定的列上,以便提升数据检索速度。Elasticsearch 和 Lucene 使用了一个叫做 倒排索引 的结构来达到相同的目的。
+ 默认的,一个文档中的每一个属性都是 被索引 的(有一个倒排索引)和可搜索的。一个没有倒排索引的属性是不能被搜索到的。我们将在 倒排索引 讨论倒排索引的更多细节。
对于雇员目录,我们将做如下操作:
- 每个雇员索引一个文档,包含该雇员的所有信息。
- 每个文档都将是
employee类型 。 - 该类型位于 索引
megacorp内。 - 该索引保存在我们的 Elasticsearch 集群中。
实践中这非常简单(尽管看起来有很多步骤),我们可以通过一条命令完成所有这些动作:
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
注意,路径 /megacorp/employee/1 包含了三部分的信息:
megacorp索引名称
employee类型名称
1特定雇员的ID
请求体 —— JSON 文档 —— 包含了这位员工的所有详细信息,他的名字叫 John Smith ,今年 25 岁,喜欢攀岩。
很简单!无需进行执行管理任务,如创建一个索引或指定每个属性的数据类型之类的,可以直接只索引一个文档。Elasticsearch 默认地完成其他一切,因此所有必需的管理任务都在后台使用默认设置完成。
进行下一步前,让我们增加更多的员工信息到目录中:
PUT /megacorp/employee/2
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
PUT /megacorp/employee/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
检索文档
目前我们已经在 Elasticsearch 中存储了一些数据, 接下来就能专注于实现应用的业务需求了。第一个需求是可以检索到单个雇员的数据。
这在 Elasticsearch 中很简单。简单地执行 一个 HTTP GET 请求并指定文档的地址——索引库、类型和ID。 使用这三个信息可以返回原始的 JSON 文档:
GET /megacorp/employee/1
返回结果包含了文档的一些元数据,以及 _source 属性,内容是 John Smith 雇员的原始 JSON 文档:
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
}
PUT改为GET可以用来检索文档,同样的,可以使用DELETE命令来删除文档,以及使用HEAD指令来检查文档是否存在。如果想更新已存在的文档,只需再次PUT。
轻量搜索
一个 GET 是相当简单的,可以直接得到指定的文档。 现在尝试点儿稍微高级的功能,比如一个简单的搜索!
第一个尝试的几乎是最简单的搜索了。我们使用下列请求来搜索所有雇员:
GET /megacorp/employee/_search
可以看到,我们仍然使用索引库 megacorp 以及类型 employee,但与指定一个文档 ID 不同,这次使用 _search 。返回结果包括了所有三个文档,放在数组 hits 中。一个搜索默认返回十条结果。
{
"took": 6,
"timed_out": false,
"_shards": { ... },
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "3",
"_score": 1,
"_source": {
"first_name": "Douglas",
"last_name": "Fir",
"age": 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 1,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [ "music" ]
}
}
]
}
}
注意:返回结果不仅告知匹配了哪些文档,还包含了整个文档本身:显示搜索结果给最终用户所需的全部信息。
接下来,尝试下搜索姓氏为 Smith 的雇员。为此,我们将使用一个 高亮 搜索,很容易通过命令行完成。这个方法一般涉及到一个 查询字符串 (query-string) 搜索,因为我们通过一个URL参数来传递查询信息给搜索接口:
GET /megacorp/employee/_search?q=last_name:Smith
我们仍然在请求路径中使用 _search 端点,并将查询本身赋值给参数 q= 。返回结果给出了所有的 Smith:
{
...
"hits": {
"total": 2,
"max_score": 0.30685282,
"hits": [
{
...
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
},
{
...
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [ "music" ]
}
}
]
}
}
使用查询表达式搜索
Query-string 搜索通过命令非常方便地进行临时性的即席搜索 ,但它有自身的局限性(参见 轻量 搜索)。Elasticsearch 提供一个丰富灵活的查询语言叫做 查询表达式 , 它支持构建更加复杂和健壮的查询。
领域特定语言 (DSL), 指定了使用一个 JSON 请求。我们可以像这样重写之前的查询所有 Smith 的搜索 :
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
返回结果与之前的查询一样,但还是可以看到有一些变化。其中之一是,不再使用 query-string 参数,而是一个请求体替代。这个请求使用 JSON 构造,并使用了一个 match 查询(属于查询类型之一,后续将会了解)。
更复杂的搜索
现在尝试下更复杂的搜索。 同样搜索姓氏为 Smith 的雇员,但这次我们只需要年龄大于 30 的。查询需要稍作调整,使用过滤器 filter ,它支持高效地执行一个结构化查询。
GET /megacorp/employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith" <1>
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 } <2>
}
}
}
}
}
match查询 一样。
range过滤器 , 它能找到年龄大于 30 的文档,其中gt表示_大于(_great than)。
目前无需太多担心语法问题,后续会更详细地介绍。只需明确我们添加了一个 过滤器 用于执行一个范围查询,并复用之前的 match 查询。现在结果只返回了一个雇员,叫 Jane Smith,32 岁。
{
...
"hits": {
"total": 1,
"max_score": 0.30685282,
"hits": [
{
...
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [ "music" ]
}
}
]
}
}
全文搜索
截止目前的搜索相对都很简单:单个姓名,通过年龄过滤。现在尝试下稍微高级点儿的全文搜索——一项传统数据库确实很难搞定的任务。
搜索下所有喜欢攀岩(rock climbing)的雇员:
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}
显然我们依旧使用之前的 match 查询在about 属性上搜索 “rock climbing” 。得到两个匹配的文档:
{
...
"hits": {
"total": 2,
"max_score": 0.16273327, <1>
"hits": [
{
...
"_score": 0.16273327,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
},
{
...
"_score": 0.016878016, <2>
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [ "music" ]
}
}
]
}
}
Elasticsearch 默认按照相关性得分排序,即每个文档跟查询的匹配程度。第一个最高得分的结果很明显:John Smith 的 about 属性清楚地写着 “rock climbing” 。
但为什么 Jane Smith 也作为结果返回了呢?原因是她的 about 属性里提到了 “rock” 。因为只有 “rock” 而没有 “climbing” ,所以她的相关性得分低于 John 的。
这是一个很好的案例,阐明了 Elasticsearch 如何 在 全文属性上搜索并返回相关性最强的结果。Elasticsearch中的 相关性 概念非常重要,也是完全区别于传统关系型数据库的一个概念,数据库中的一条记录要么匹配要么不匹配。
短语搜索
找出一个属性中的独立单词是没有问题的,但有时候想要精确匹配一系列单词或者短语 。 比如, 我们想执行这样一个查询,仅匹配同时包含 “rock” 和 “climbing” ,并且 二者以短语 “rock climbing” 的形式紧挨着的雇员记录。
为此对 match 查询稍作调整,使用一个叫做 match_phrase 的查询:
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}
毫无悬念,返回结果仅有 John Smith 的文档。
{
...
"hits": {
"total": 1,
"max_score": 0.23013961,
"hits": [
{
...
"_score": 0.23013961,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
}
]
}
}
高亮搜索
许多应用都倾向于在每个搜索结果中 高亮 部分文本片段,以便让用户知道为何该文档符合查询条件。在 Elasticsearch 中检索出高亮片段也很容易。
再次执行前面的查询,并增加一个新的 highlight 参数:
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
当执行该查询时,返回结果与之前一样,与此同时结果中还多了一个叫做 highlight 的部分。这个部分包含了 about 属性匹配的文本片段,并以 HTML 标签 <em></em> 封装:
{
...
"hits": {
"total": 1,
"max_score": 0.23013961,
"hits": [
{
...
"_score": 0.23013961,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
},
"highlight": {
"about": [
"I love to go <em>rock</em> <em>climbing</em>" <1>
]
}
}
]
}
}
关于高亮搜索片段,可以在 highlighting reference documentation 了解更多信息。
分析
终于到了最后一个业务需求:支持管理者对雇员目录做分析。 Elasticsearch 有一个功能叫聚合(aggregations),允许我们基于数据生成一些精细的分析结果。聚合与 SQL 中的 GROUP BY 类似但更强大。
举个例子,挖掘出雇员中最受欢迎的兴趣爱好:
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": { "field": "interests" }
}
}
}
暂时忽略掉语法,直接看看结果:
{
...
"hits": { ... },
"aggregations": {
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2
},
{
"key": "forestry",
"doc_count": 1
},
{
"key": "sports",
"doc_count": 1
}
]
}
}
}
可以看到,两位员工对音乐感兴趣,一位对林地感兴趣,一位对运动感兴趣。这些聚合并非预先统计,而是从匹配当前查询的文档中即时生成。如果想知道叫 Smith 的雇员中最受欢迎的兴趣爱好,可以直接添加适当的查询来组合查询:
GET /megacorp/employee/_search
{
"query": {
"match": {
"last_name": "smith"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}
all_interests 聚合已经变为只包含匹配查询的文档:
...
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2
},
{
"key": "sports",
"doc_count": 1
}
]
}
聚合还支持分级汇总 。比如,查询特定兴趣爱好员工的平均年龄:
GET /megacorp/employee/_search
{
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}
得到的聚合结果有点儿复杂,但理解起来还是很简单的:
...
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2,
"avg_age": {
"value": 28.5
}
},
{
"key": "forestry",
"doc_count": 1,
"avg_age": {
"value": 35
}
},
{
"key": "sports",
"doc_count": 1,
"avg_age": {
"value": 25
}
}
]
}
输出基本是第一次聚合的加强版。依然有一个兴趣及数量的列表,只不过每个兴趣都有了一个附加的 avg_age 属性,代表有这个兴趣爱好的所有员工的平均年龄。
即使现在不太理解这些语法也没有关系,依然很容易了解到复杂聚合及分组通过 Elasticsearch 特性实现得很完美。可提取的数据类型毫无限制。
教程结语
欣喜的是,这是一个关于 Elasticsearch 基础描述的教程,且仅仅是浅尝辄止,更多诸如 suggestions、geolocation、percolation、fuzzy 与 partial matching 等特性均被省略,以便保持教程的简洁。但它确实突显了开始构建高级搜索功能多么容易。不需要配置——只需要添加数据并开始搜索!
很可能语法会让你在某些地方有所困惑,并且对各个方面如何微调也有一些问题。没关系!本书后续内容将针对每个问题详细解释,让你全方位地理解 Elasticsearch 的工作原理。
分布式特性
在本章开头,我们提到过 Elasticsearch 可以横向扩展至数百(甚至数千)的服务器节点,同时可以处理PB级数据。我们的教程给出了一些使用 Elasticsearch 的示例,但并不涉及任何内部机制。Elasticsearch 天生就是分布式的,并且在设计时屏蔽了分布式的复杂性。
Elasticsearch 在分布式方面几乎是透明的。教程中并不要求了解分布式系统、分片、集群发现或其他的各种分布式概念。可以使用笔记本上的单节点轻松地运行教程里的程序,但如果你想要在 100 个节点的集群上运行程序,一切依然顺畅。
Elasticsearch 尽可能地屏蔽了分布式系统的复杂性。这里列举了一些在后台自动执行的操作:
- 分配文档到不同的容器 或 分片 中,文档可以储存在一个或多个节点中
- 按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
- 复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
- 将集群中任一节点的请求路由到存有相关数据的节点
- 集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复
当阅读本书时,将会遇到有关 Elasticsearch 分布式特性的补充章节。这些章节将介绍有关集群扩容、故障转移(集群内的原理) 、应对文档存储(分布式文档存储) 、执行分布式搜索(执行分布式检索) ,以及分区(shard)及其工作原理(分片内部原理) 。
这些章节并非必读,完全可以无需了解内部机制就使用 Elasticsearch,但是它们将从另一个角度帮助你了解更完整的 Elasticsearch 知识。可以根据需要跳过它们,或者想更完整地理解时再回头阅读也无妨。
后续步骤
现在对于通过 Elasticsearch 能够实现什么样的功能、以及上手的简易程度应该有了初步概念。Elasticsearch 力图通过最少的知识和配置做到开箱即用。学习 Elasticsearch 的最好方式是投入实践:尽管开始索引和搜索吧!
然而,对于 Elasticsearch 知道得越多,就越有生产效率。告诉 Elasticsearch 越多的领域知识,就越容易进行结果调优。
本书的后续内容将帮助你从新手成长为专家,每个章节不仅阐述必要的基础知识,而且包含专家建议。如果刚刚上手,这些建议可能无法立竿见影;但 Elasticsearch 有着合理的默认设置,在无需干预的情况下通常都能工作得很好。当追求毫秒级的性能提升时,随时可以重温这些章节。
集群内的原理
补充章节
如前文所述,这是补充章节中第一篇介绍 Elasticsearch 在分布式环境中的运行原理。 在这个章节中,我们将会介绍 cluster 、 node 、 shard 等常用术语,Elastisearch 的扩容机制, 以及如何处理硬件故障的内容。
虽然这个章节不是必读的--您完全可以在不关注分片、副本和失效切换等内容的情况下长期使用Elasticsearch-- 但是这将帮助你了解 Elasticsearch 的内部工作过程。您可以先快速阅览该章节,将来有需要时再次查看。
ElasticSearch 的主旨是随时可用和按需扩容。 而扩容可以通过购买性能更强大( 垂直扩容 ,或 纵向扩容) 或者数量更多的服务器( 水平扩容 ,或 横向扩容 )来实现。
虽然 Elasticsearch 可以获益于更强大的硬件设备,但是垂直扩容是有极限的。 真正的扩容能力是来自于水平扩容--为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中。
对于大多数的数据库而言,通常需要对应用程序进行非常大的改动,才能利用上横向扩容的新增资源。 与之相反的是,ElastiSearch天生就是 分布式的 ,它知道如何通过管理多节点来提高扩容性和可用性。 这也意味着你的应用无需关注这个问题。
本章将讲述如何按需配置集群、节点和分片,并在硬件故障时确保数据安全。
空集群
如果我们启动了一个单独的节点,里面不包含任何的数据和 索引,那我们的集群看起来就是一个 图 1 “包含空内容节点的集群”。
图 1. 包含空内容节点的集群

一个运行中的 Elasticsearch 实例称为一个 节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为 主 节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
集群健康
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 集群健康 , 它在 status 字段中展示为 green 、 yellow 或者 red 。
GET /_cluster/health
在一个不包含任何索引的空集群中,它将会有一个类似于如下所示的返回内容:
{
"cluster_name": "elasticsearch",
"status": "green", <1>
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
status字段是我们最关心的。
status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
green所有的主分片和副本分片都正常运行。
yellow所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red有主分片没能正常运行。
在本章节剩余的部分,我们将解释什么是 主 分片和 副本 分片,以及上面提到的这些颜色的实际意义。
添加索引
我们往 Elasticsearch 添加数据时需要用到 索引 —— 保存相关数据的地方。 索引实际上是指向一个或者多个物理 分片 的 逻辑命名空间 。
一个 分片 是一个底层的 工作单元 ,它仅保存了 全部数据中的一部分。 在分片内部机制中,我们将详细介绍分片是如何工作的,而现在我们只需知道一个分片是一个 Lucene 的实例,以及它本身就是一个完整的搜索引擎。 我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
一个分片可以是 主 分片或者 副本 分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。
一个副本分片只是一个主分片的拷贝。 副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
让我们在包含一个空节点的集群内创建名为 blogs 的索引。 索引在默认情况下会被分配5个主分片, 但是为了演示目的,我们将分配3个主分片和一份副本(每个主分片拥有一个副本分片):
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
我们的集群现在是图 2 “拥有一个索引的单节点集群”。所有3个主分片都被分配在 Node 1 。
图 2. 拥有一个索引的单节点集群

如果我们现在查看集群健康, 我们将看到如下内容:
{
"cluster_name": "elasticsearch",
"status": "yellow", <1>
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3, <2>
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50
}
status值为yellow。
集群的健康状况为 yellow 则表示全部 主 分片都正常运行(集群可以正常服务所有请求),但是 副本 分片没有全部处在正常状态。 实际上,所有3个副本分片都是 unassigned —— 它们都没有被分配到任何节点。 在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点上的所有副本数据。
当前我们的集群是正常运行的,但是在硬件故障时有丢失数据的风险。
添加故障转移
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。 幸运的是,我们只需再启动一个节点即可防止数据丢失。
启动第二个节点
为了测试第二个节点启动后的情况,你可以在同一个目录内,完全依照启动第一个节点的方式来启动一个新节点(参考安装并运行 Elasticsearch)。多个节点可以共享同一个目录。
当你在同一台机器上启动了第二个节点时,只要它和第一个节点有同样的
cluster.name配置,它就会自动发现集群并加入到其中。 但是在不同机器上启动节点的时候,为了加入到同一集群,你需要配置一个可连接到的单播主机列表。 详细信息请查看最好使用单播代替组播
如果启动了第二个节点,我们的集群将会如图 3 “拥有两个节点的集群——所有主分片和副本分片都已被分配”所示。
图 3. 拥有两个节点的集群——所有主分片和副本分片都已被分配
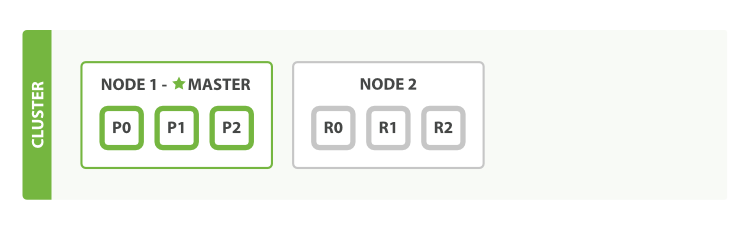
当第二个节点加入到集群后,3个 副本分片 将会分配到这个节点上——每个主分片对应一个副本分片。 这意味着当集群内任何一个节点出现问题时,我们的数据都完好无损。
所有新近被索引的文档都将会保存在主分片上,然后被并行的复制到对应的副本分片上。这就保证了我们既可以从主分片又可以从副本分片上获得文档。
cluster-health 现在展示的状态为 green ,这表示所有6个分片(包括3个主分片和3个副本分片)都在正常运行。
{
"cluster_name": "elasticsearch",
"status": "green", <1>
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
status值为green。
我们的集群现在不仅仅是正常运行的,并且还处于 始终可用 的状态。
水平扩容
怎样为我们的正在增长中的应用程序按需扩容呢? 当启动了第三个节点,我们的集群将会看起来如图 4 “拥有三个节点的集群——为了分散负载而对分片进行重新分配”所示。
图 4. 拥有三个节点的集群——为了分散负载而对分片进行重新分配
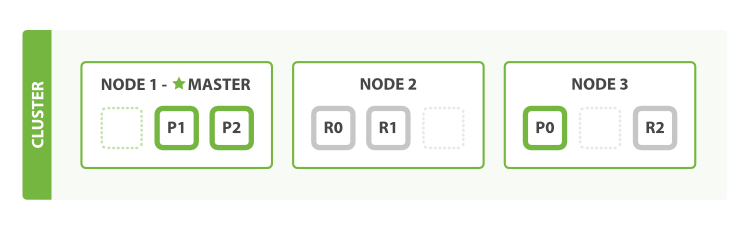
Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点,现在每个节点上都拥有2个分片,而不是之前的3个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少的分片所共享,每个分片的性能将会得到提升。
分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力。 我们这个拥有6个分片(3个主分片和3个副本分片)的索引可以最大扩容到6个节点,每个节点上存在一个分片,并且每个分片拥有所在节点的全部资源。
更多的扩容
但是如果我们想要扩容超过6个节点怎么办呢?
主分片的数目在索引创建时 就已经确定了下来。实际上,这个数目定义了这个索引能够 存储 的最大数据量。(实际大小取决于你的数据、硬件和使用场景。) 但是,读操作——搜索和返回数据——可以同时被主分片 或 副本分片所处理,所以当你拥有越多的副本分片时,也将拥有越高的吞吐量。
在运行中的集群上是可以动态调整副本分片数目的 ,我们可以按需伸缩集群。让我们把副本数从默认的 1增加到 2 :
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
如图 5 “将参数 number_of_replicas 调大到 2”所示, blogs 索引现在拥有9个分片:3个主分片和6个副本分片。 这意味着我们可以将集群扩容到9个节点,每个节点上一个分片。相比原来3个节点时,集群搜索性能可以提升 3 倍。
图 5. 将参数 number_of_replicas 调大到 2
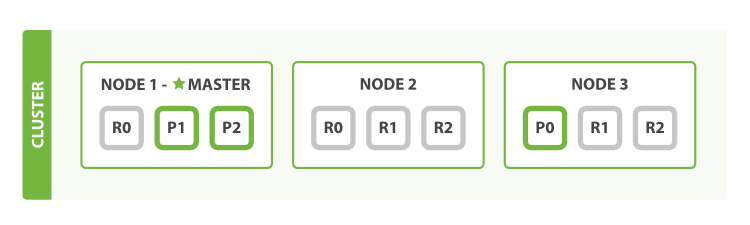
但是更多的副本分片数提高了数据冗余量:按照上面的节点配置,我们可以在失去2个节点的情况下不丢失任何数据。
应对故障
我们之前说过 Elasticsearch 可以应对节点故障,接下来让我们尝试下这个功能。 如果我们关闭第一个节点,这时集群的状态为图 6 “关闭了一个节点后的集群”
图 6. 关闭了一个节点后的集群
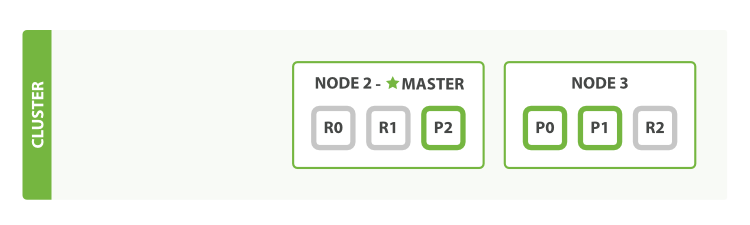
我们关闭的节点是一个主节点。而集群必须拥有一个主节点来保证正常工作,所以发生的第一件事情就是选举一个新的主节点: Node 2 。
在我们关闭 Node 1 的同时也失去了主分片 1 和 2 ,并且在缺失主分片的时候索引也不能正常工作。 如果此时来检查集群的状况,我们看到的状态将会为 red :不是所有主分片都在正常工作。
幸运的是,在其它节点上存在着这两个主分片的完整副本, 所以新的主节点立即将这些分片在 Node 2 和 Node 3 上对应的副本分片提升为主分片, 此时集群的状态将会为 yellow 。 这个提升主分片的过程是瞬间发生的,如同按下一个开关一般。
为什么我们集群状态是 yellow 而不是 green 呢? 虽然我们拥有所有的三个主分片,但是同时设置了每个主分片需要对应2份副本分片,而此时只存在一份副本分片。 所以集群不能为 green 的状态,不过我们不必过于担心:如果我们同样关闭了 Node 2 ,我们的程序 依然 可以保持在不丢任何数据的情况下运行,因为 Node 3 为每一个分片都保留着一份副本。
如果我们重新启动 Node 1 ,集群可以将缺失的副本分片再次进行分配,那么集群的状态也将如图 5 “将参数 number_of_replicas 调大到 2”所示。 如果 Node 1 依然拥有着之前的分片,它将尝试去重用它们,同时仅从主分片复制发生了修改的数据文件。
到目前为止,你应该对分片如何使得 Elasticsearch 进行水平扩容以及数据保障等知识有了一定了解。 接下来我们将讲述关于分片生命周期的更多细节。
数据输入和输出
无论我们写什么样的程序,目的都是一样的:以某种方式组织数据服务我们的目的。 但是数据不仅仅由随机位和字节组成。我们建立数据元素之间的关系以便于表示实体,或者现实世界中存在的 事物 。 如果我们知道一个名字和电子邮件地址属于同一个人,那么它们将会更有意义。
尽管在现实世界中,不是所有的类型相同的实体看起来都是一样的。 一个人可能有一个家庭电话号码,而另一个人只有一个手机号码,再一个人可能两者兼有。 一个人可能有三个电子邮件地址,而另一个人却一个都没有。一位西班牙人可能有两个姓,而讲英语的人可能只有一个姓。
面向对象编程语言如此流行的原因之一是对象帮我们表示和处理现实世界具有潜在的复杂的数据结构的实体,到目前为止,一切都很完美!
但是当我们需要存储这些实体时问题来了,传统上,我们以行和列的形式存储数据到关系型数据库中,相当于使用电子表格。 正因为我们使用了这种不灵活的存储媒介导致所有我们使用对象的灵活性都丢失了。
但是否我们可以将我们的对象按对象的方式来存储? 这样我们就能更加专注于 使用 数据,而不是在电子表格的局限性下对我们的应用建模。 我们可以重新利用对象的灵活性。
一个 对象 是基于特定语言的内存的数据结构。 为了通过网络发送或者存储它,我们需要将它表示成某种标准的格式。 JSON 是一种以人可读的文本表示对象的方法。 它已经变成 NoSQL 世界交换数据的事实标准。当一个对象被序列化成为 JSON,它被称为一个 JSON 文档 。
Elastcisearch 是分布式的 文档 存储。它能存储和检索复杂的数据结构--序列化成为JSON文档--以 实时 的方式。 换句话说,一旦一个文档被存储在 Elasticsearch 中,它就是可以被集群中的任意节点检索到。
当然,我们不仅要存储数据,我们一定还需要查询它,成批且快速的查询它们。 尽管现存的 NoSQL 解决方案允许我们以文档的形式存储对象,但是他们仍旧需要我们思考如何查询我们的数据,以及确定哪些字段需要被索引以加快数据检索。
在 Elasticsearch 中, 每个字段的所有数据 都是 默认被索引的 。 即每个字段都有为了快速检索设置的专用倒排索引。而且,不像其他多数的数据库,它能在 同一个查询中 使用所有这些倒排索引,并以惊人的速度返回结果。
在本章中,我们展示了用来创建,检索,更新和删除文档的 API。就目前而言,我们不关心文档中的数据或者怎样查询它们。 所有我们关心的就是在 Elasticsearch 中怎样安全的存储文档,以及如何将文档再次返回。
什么是文档?
在大多数应用中,多数实体或对象可以被序列化为包含键值对的 JSON 对象。 一个 键 可以是一个字段或字段的名称,一个 值 可以是一个字符串,一个数字,一个布尔值, 另一个对象,一些数组值,或一些其它特殊类型诸如表示日期的字符串,或代表一个地理位置的对象:
{
"name": "John Smith",
"age": 42,
"confirmed": true,
"join_date": "2014-06-01",
"home": {
"lat": 51.5,
"lon": 0.1
},
"accounts": [
{
"type": "facebook",
"id": "johnsmith"
},
{
"type": "twitter",
"id": "johnsmith"
}
]
}
通常情况下,我们使用的术语 对象 和 文档 是可以互相替换的。不过,有一个区别: 一个对象仅仅是类似于 hash 、 hashmap 、字典或者关联数组的 JSON 对象,对象中也可以嵌套其他的对象。 对象可能包含了另外一些对象。在 Elasticsearch 中,术语 文档 有着特定的含义。它是指最顶层或者根对象, 这个根对象被序列化成 JSON 并存储到 Elasticsearch 中,指定了唯一 ID。
字段的名字可以是任何合法的字符串,但 不可以 包含英文句号(.)。
文档元数据
一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index文档在哪存放
_type文档表示的对象类别
_id文档唯一标识
_index
一个 索引 应该是因共同的特性被分组到一起的文档集合。 例如,你可能存储所有的产品在索引 products中,而存储所有销售的交易到索引 sales 中。 虽然也允许存储不相关的数据到一个索引中,但这通常看作是一个反模式的做法。
我们将在 索引管理 介绍如何自行创建和管理索引,但现在我们将让 Elasticsearch 帮我们创建索引。 所有需要我们做的就是选择一个索引名,这个名字必须小写,不能以下划线开头,不能包含逗号。我们用 website 作为索引名举例。
_type
数据可能在索引中只是松散的组合在一起,但是通常明确定义一些数据中的子分区是很有用的。 例如,所有的产品都放在一个索引中,但是你有许多不同的产品类别,比如 "electronics" 、 "kitchen" 和 "lawn-care"。
这些文档共享一种相同的(或非常相似)的模式:他们有一个标题、描述、产品代码和价格。他们只是正好属于“产品”下的一些子类。
Elasticsearch 公开了一个称为 types (类型)的特性,它允许您在索引中对数据进行逻辑分区。不同 types 的文档可能有不同的字段,但最好能够非常相似。 我们将在 类型和映射 中更多的讨论关于 types 的一些应用和限制。
一个 _type 命名可以是大写或者小写,但是不能以下划线或者句号开头,不应该包含逗号, 并且长度限制为256个字符. 我们使用 blog 作为类型名举例。
_id
ID 是一个字符串, 当它和 _index 以及 _type 组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的 _id ,要么让 Elasticsearch 帮你生成。
其他元数据
还有一些其他的元数据元素,他们在 类型和映射 进行了介绍。通过前面已经列出的元数据元素, 我们已经能存储文档到 Elasticsearch 中并通过 ID 检索它--换句话说,使用 Elasticsearch 作为文档的存储介质。
索引文档
通过使用 index API ,文档可以被 索引 —— 存储和使文档可被搜索 。 但是首先,我们要确定文档的位置。正如我们刚刚讨论的,一个文档的 _index 、 _type 和 _id 唯一标识一个文档。 我们可以提供自定义的 _id 值,或者让 index API 自动生成。
使用自定义的 ID
如果你的文档有一个自然的 标识符 (例如,一个 user_account 字段或其他标识文档的值),你应该使用如下方式的 index API 并提供你自己 _id :
PUT /{index}/{type}/{id}
{
"field": "value",
...
}
举个例子,如果我们的索引称为 website ,类型称为 blog ,并且选择 123 作为 ID ,那么索引请求应该是下面这样:
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
Elasticsearch 响应体如下所示:
{
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 1,
"created": true
}
该响应表明文档已经成功创建,该索引包括 _index 、 _type 和 _id 元数据, 以及一个新元素: _version 。
在 Elasticsearch 中每个文档都有一个版本号。当每次对文档进行修改时(包括删除), _version 的值会递增。 在 处理冲突 中,我们讨论了怎样使用 _version 号码确保你的应用程序中的一部分修改不会覆盖另一部分所做的修改。
Autogenerating IDs
如果你的数据没有自然的 ID, Elasticsearch 可以帮我们自动生成 ID 。 请求的结构调整为: 不再使用PUT 谓词(“使用这个 URL 存储这个文档”), 而是使用 POST 谓词(“存储文档在这个 URL 命名空间下”)。
现在该 URL 只需包含 _index 和 _type :
POST /website/blog/
{
"title": "My second blog entry",
"text": "Still trying this out...",
"date": "2014/01/01"
}
除了 _id 是 Elasticsearch 自动生成的,响应的其他部分和前面的类似:
{
"_index": "website",
"_type": "blog",
"_id": "AVFgSgVHUP18jI2wRx0w",
"_version": 1,
"created": true
}
自动生成的 ID 是 URL-safe、 基于 Base64 编码且长度为20个字符的 GUID 字符串。 这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一 ID ,且互相之间的冲突概率几乎为零。
取回一个文档
为了从 Elasticsearch 中检索出文档 ,我们仍然使用相同的 _index , _type , 和 _id ,但是 HTTP 谓词更改为 GET :
GET /website/blog/123?pretty
响应体包括目前已经熟悉了的元数据元素,再加上 _source 字段,这个字段包含我们索引数据时发送给 Elasticsearch 的原始 JSON 文档:
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
}
pretty参数, 正如前面的例子中看到的,这将会调用 Elasticsearch 的 pretty-print 功能,该功能 使得 JSON 响应体更加可读。但是,_source字段不能被格式化打印出来。相反,我们得到的_source字段中的 JSON 串,刚好是和我们传给它的一样。
GET 请求的响应体包括 {"found": true} ,这证实了文档已经被找到。 如果我们请求一个不存在的文档,我们仍旧会得到一个 JSON 响应体,但是 found 将会是 false 。 此外, HTTP 响应码将会是 404 Not Found ,而不是 200 OK 。
我们可以通过传递 -i 参数给 curl 命令,该参数 能够显示响应的头部:
curl -i -XGET http://localhost:9200/website/blog/124?pretty
显示响应头部的响应体现在类似这样:
HTTP/1.1 404 Not Found
Content-Type: application/json; charset=UTF-8
Content-Length: 83
{
"_index" : "website",
"_type" : "blog",
"_id" : "124",
"found" : false
}
返回文档的一部分
默认情况下, GET 请求 会返回整个文档,这个文档正如存储在 _source 字段中的一样。但是也许你只对其中的 title 字段感兴趣。单个字段能用 _source 参数请求得到,多个字段也能使用逗号分隔的列表来指定。
GET /website/blog/123?_source=title,text
该 _source 字段现在包含的只是我们请求的那些字段,并且已经将 date 字段过滤掉了。
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry" ,
"text": "Just trying this out..."
}
}
或者,如果你只想得到 _source 字段,不需要任何元数据,你能使用 _source 端点:
GET /website/blog/123/_source
那么返回的的内容如下所示:
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
检查文档是否存在
如果只想检查一个文档是否存在 --根本不想关心内容--那么用 HEAD 方法来代替 GET 方法。 HEAD 请求没有返回体,只返回一个 HTTP 请求报头:
curl -i -XHEAD http://localhost:9200/website/blog/123
如果文档存在, Elasticsearch 将返回一个 200 ok 的状态码:
HTTP/1.1 200 OK
Content-Type: text/plain; charset=UTF-8
Content-Length: 0
若文档不存在, Elasticsearch 将返回一个 404 Not Found 的状态码:
curl -i -XHEAD http://localhost:9200/website/blog/124
HTTP/1.1 404 Not Found
Content-Type: text/plain; charset=UTF-8
Content-Length: 0
当然,一个文档仅仅是在检查的时候不存在,并不意味着一毫秒之后它也不存在:也许同时正好另一个进程就创建了该文档。
更新整个文档
在 Elasticsearch 中文档是 不可改变 的,不能修改它们。 相反,如果想要更新现有的文档,需要 重建索引或者进行替换, 我们可以使用相同的 index API 进行实现,在 索引文档 中已经进行了讨论。
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}
在响应体中,我们能看到 Elasticsearch 已经增加了 _version 字段值:
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 2,
"created": false <1>
}
created标志设置成false,是因为相同的索引、类型和 ID 的文档已经存在。
在内部,Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档。 尽管你不能再对旧版本的文档进行访问,但它并不会立即消失。当继续索引更多的数据,Elasticsearch 会在后台清理这些已删除文档。
在本章的后面部分,我们会介绍 update API, 这个 API 可以用于 partial updates to a document 。 虽然它似乎对文档直接进行了修改,但实际上 Elasticsearch 按前述完全相同方式执行以下过程:
- 从旧文档构建 JSON
- 更改该 JSON
- 删除旧文档
- 索引一个新文档
唯一的区别在于, update API 仅仅通过一个客户端请求来实现这些步骤,而不需要单独的 get 和 index请求。
创建新文档
当我们索引一个文档, 怎么确认我们正在创建一个完全新的文档,而不是覆盖现有的呢?
请记住, _index 、 _type 和 _id 的组合可以唯一标识一个文档。所以,确保创建一个新文档的最简单办法是,使用索引请求的 POST 形式让 Elasticsearch 自动生成唯一 _id :
POST /website/blog/
{ ... }
然而,如果已经有自己的 _id ,那么我们必须告诉 Elasticsearch ,只有在相同的 _index 、 _type 和 _id 不存在时才接受我们的索引请求。这里有两种方式,他们做的实际是相同的事情。使用哪种,取决于哪种使用起来更方便。
第一种方法使用 op_type 查询 -字符串参数:
PUT /website/blog/123?op_type=create
{ ... }
第二种方法是在 URL 末端使用 /_create :
PUT /website/blog/123/_create
{ ... }
如果创建新文档的请求成功执行,Elasticsearch 会返回元数据和一个 201 Created 的 HTTP 响应码。
另一方面,如果具有相同的 _index 、 _type 和 _id 的文档已经存在,Elasticsearch 将会返回 409 Conflict 响应码,以及如下的错误信息:
{
"error": {
"root_cause": [
{
"type": "document_already_exists_exception",
"reason": "[blog][123]: document already exists",
"shard": "0",
"index": "website"
}
],
"type": "document_already_exists_exception",
"reason": "[blog][123]: document already exists",
"shard": "0",
"index": "website"
},
"status": 409
}
删除文档
删除文档 的语法和我们所知道的规则相同,只是 使用 DELETE 方法:
DELETE /website/blog/123
如果找到该文档,Elasticsearch 将要返回一个 200 ok 的 HTTP 响应码,和一个类似以下结构的响应体。注意,字段 _version 值已经增加:
{
"found" : true,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3
}
如果文档没有 找到,我们将得到 404 Not Found 的响应码和类似这样的响应体:
{
"found" : false,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 4
}
即使文档不存在( Found 是 false ), _version 值仍然会增加。这是 Elasticsearch 内部记录本的一部分,用来确保这些改变在跨多节点时以正确的顺序执行。
处理冲突
当我们使用 index API 更新文档 ,可以一次性读取原始文档,做我们的修改,然后重新索引 整个文档 。 最近的索引请求将获胜:无论最后哪一个文档被索引,都将被唯一存储在 Elasticsearch 中。如果其他人同时更改这个文档,他们的更改将丢失。
很多时候这是没有问题的。也许我们的主数据存储是一个关系型数据库,我们只是将数据复制到 Elasticsearch 中并使其可被搜索。 也许两个人同时更改相同的文档的几率很小。或者对于我们的业务来说偶尔丢失更改并不是很严重的问题。
但有时丢失了一个变更就是 非常严重的 。试想我们使用 Elasticsearch 存储我们网上商城商品库存的数量, 每次我们卖一个商品的时候,我们在 Elasticsearch 中将库存数量减少。
有一天,管理层决定做一次促销。突然地,我们一秒要卖好几个商品。 假设有两个 web 程序并行运行,每一个都同时处理所有商品的销售,如图 图 7 “Consequence of no concurrency control” 所示。
图 7. Consequence of no concurrency control
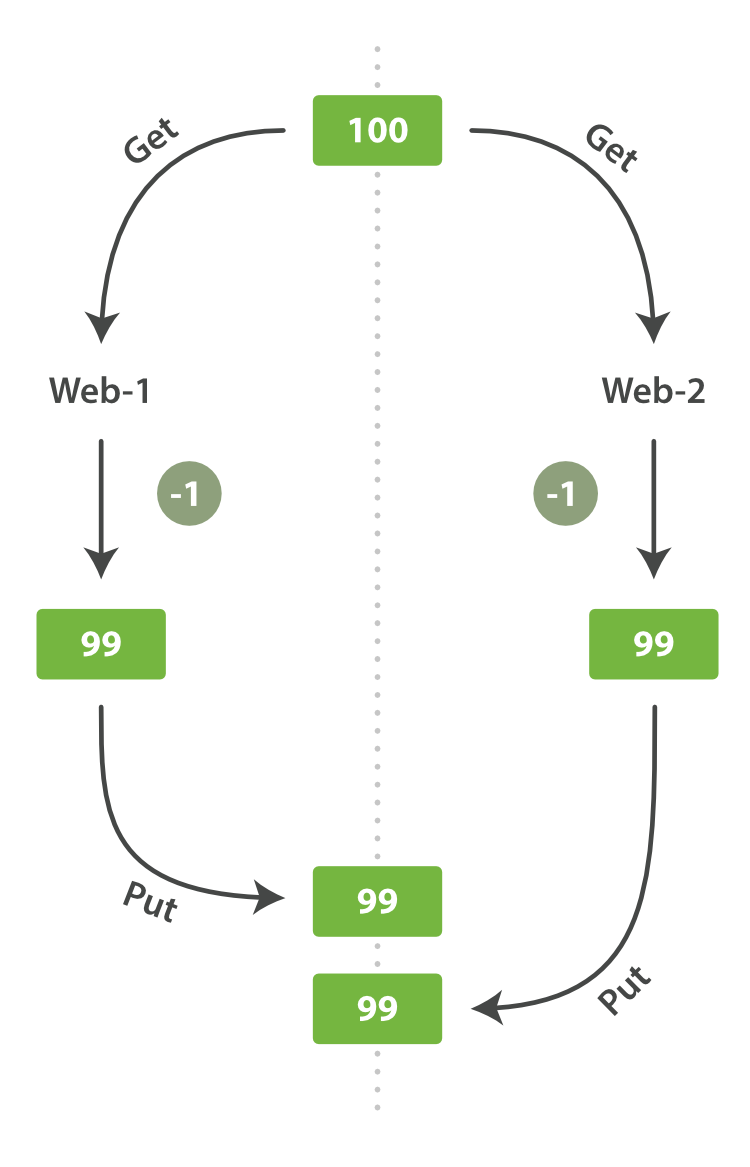
web_1 对 stock_count 所做的更改已经丢失,因为 web_2 不知道它的 stock_count 的拷贝已经过期。 结果我们会认为有超过商品的实际数量的库存,因为卖给顾客的库存商品并不存在,我们将让他们非常失望。
变更越频繁,读数据和更新数据的间隙越长,也就越可能丢失变更。
在数据库领域中,有两种方法通常被用来确保并发更新时变更不会丢失:
悲观并发控制
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
乐观并发控制
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
乐观并发控制
Elasticsearch 是分布式的。当文档创建、更新或删除时, 新版本的文档必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许 顺序是乱的。 Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前讨论 index , GET 和 delete 请求时,我们指出每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。 Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version 号来达到这个目的。 如果该版本不是当前版本号,我们的请求将会失败。
让我们创建一个新的博客文章:
PUT /website/blog/1/_create
{
"title": "My first blog entry",
"text": "Just trying this out..."
}
响应体告诉我们,这个新创建的文档 _version 版本号是 1 。现在假设我们想编辑这个文档:我们加载其数据到 web 表单中, 做一些修改,然后保存新的版本。
首先我们检索文档:
GET /website/blog/1
响应体包含相同的 _version 版本号 1 :
{
"_index" : "website",
"_type" : "blog",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry",
"text": "Just trying this out..."
}
}
现在,当我们尝试通过重建文档的索引来保存修改,我们指定 version 为我们的修改会被应用的版本:
PUT /website/blog/1?version=1 <1>
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
_version为1时,本次更新才能成功。
此请求成功,并且响应体告诉我们 _version 已经递增到 2 :
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 2
"created": false
}
然而,如果我们重新运行相同的索引请求,仍然指定 version=1 , Elasticsearch 返回 409 ConflictHTTP 响应码,和一个如下所示的响应体:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
}
],
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
},
"status": 409
}
这告诉我们在 Elasticsearch 中这个文档的当前 _version 号是 2 ,但我们指定的更新版本号为 1 。
我们现在怎么做取决于我们的应用需求。我们可以告诉用户说其他人已经修改了文档,并且在再次保存之前检查这些修改内容。 或者,在之前的商品 stock_count 场景,我们可以获取到最新的文档并尝试重新应用这些修改。
所有文档的更新或删除 API,都可以接受 version 参数,这允许你在代码中使用乐观的并发控制,这是一种明智的做法。
通过外部系统使用版本控制
一个常见的设置是使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索, 这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch ,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号 — 或一个能作为版本号的字段值比如 timestamp — 那么你就可以在 Elasticsearch 中通过增加 version_type=external 到查询字符串的方式重用这些相同的版本号, 版本号必须是大于零的整数, 且小于 9.2E+18 — 一个 Java 中 long 类型的正值。
外部版本号的处理方式和我们之前讨论的内部版本号的处理方式有些不同, Elasticsearch 不是检查当前 _version 和请求中指定的版本号是否相同, 而是检查当前 _version 是否 小于 指定的版本号。 如果请求成功,外部的版本号作为文档的新 _version 进行存储。
外部版本号不仅在索引和删除请求是可以指定,而且在 创建 新文档时也可以指定。
例如,要创建一个新的具有外部版本号 5 的博客文章,我们可以按以下方法进行:
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}
在响应中,我们能看到当前的 _version 版本号是 5 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 5,
"created": true
}
现在我们更新这个文档,指定一个新的 version 号是 10 :
PUT /website/blog/2?version=10&version_type=external
{
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}
请求成功并将当前 _version 设为 10 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 10,
"created": false
}
如果你要重新运行此请求时,它将会失败,并返回像我们之前看到的同样的冲突错误, 因为指定的外部版本号不大于 Elasticsearch 的当前版本号。
文档的部分更新
在 更新整个文档 , 我们已经介绍过 更新一个文档的方法是检索并修改它,然后重新索引整个文档,这的确如此。然而,使用 update API 我们还可以部分更新文档,例如在某个请求时对计数器进行累加。
我们也介绍过文档是不可变的:他们不能被修改,只能被替换。 update API 必须遵循同样的规则。 从外部来看,我们在一个文档的某个位置进行部分更新。然而在内部, update API 简单使用与之前描述相同的 检索-修改-重建索引 的处理过程。 区别在于这个过程发生在分片内部,这样就避免了多次请求的网络开销。通过减少检索和重建索引步骤之间的时间,我们也减少了其他进程的变更带来冲突的可能性。
update 请求最简单的一种形式是接收文档的一部分作为 doc 的参数, 它只是与现有的文档进行合并。对象被合并到一起,覆盖现有的字段,增加新的字段。 例如,我们增加字段 tags 和 views 到我们的博客文章,如下所示:
POST /website/blog/1/_update
{
"doc" : {
"tags" : [ "testing" ],
"views": 0
}
}
如果请求成功,我们看到类似于 index 请求的响应:
{
"_index" : "website",
"_id" : "1",
"_type" : "blog",
"_version" : 3
}
检索文档显示了更新后的 _source 字段:
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 3,
"found": true,
"_source": {
"title": "My first blog entry",
"text": "Starting to get the hang of this...",
"tags": [ "testing" ], <1>
"views": 0 <2>
}
}
_source中。
使用脚本部分更新文档
脚本可以在 update API中用来改变 _source 的字段内容, 它在更新脚本中称为 ctx._source 。 例如,我们可以使用脚本来增加博客文章中 views 的数量:
POST /website/blog/1/_update
{
"script" : "ctx._source.views+=1"
}
用 Groovy 脚本编程
对于那些 API 不能满足需求的情况,Elasticsearch 允许你使用脚本编写自定义的逻辑。 许多API都支持脚本的使用,包括搜索、排序、聚合和文档更新。 脚本可以作为请求的一部分被传递,从特殊的 .scripts 索引中检索,或者从磁盘加载脚本。
默认的脚本语言 是 Groovy,一种快速表达的脚本语言,在语法上与 JavaScript 类似。 它在 Elasticsearch V1.3.0 版本首次引入并运行在 沙盒 中,然而 Groovy 脚本引擎存在漏洞, 允许攻击者通过构建 Groovy 脚本,在 Elasticsearch Java VM 运行时脱离沙盒并执行 shell 命令。
因此,在版本 v1.3.8 、 1.4.3 和 V1.5.0 及更高的版本中,它已经被默认禁用。 此外,您可以通过设置集群中的所有节点的
config/elasticsearch.yml文件来禁用动态 Groovy 脚本:script.groovy.sandbox.enabled: false这将关闭 Groovy 沙盒,从而防止动态 Groovy 脚本作为请求的一部分被接受, 或者从特殊的
.scripts索引中被检索。当然,你仍然可以使用存储在每个节点的config/scripts/目录下的 Groovy 脚本。如果你的架构和安全性不需要担心漏洞攻击,例如你的 Elasticsearch 终端仅暴露和提供给可信赖的应用, 当它是你的应用需要的特性时,你可以选择重新启用动态脚本。
你可以在 scripting reference documentation 获取更多关于脚本的资料。
我们也可以通过使用脚本给 tags 数组添加一个新的标签。在这个例子中,我们指定新的标签作为参数,而不是硬编码到脚本内部。 这使得 Elasticsearch 可以重用这个脚本,而不是每次我们想添加标签时都要对新脚本重新编译:
POST /website/blog/1/_update
{
"script" : "ctx._source.tags+=new_tag",
"params" : {
"new_tag" : "search"
}
}
获取文档并显示最后两次请求的效果:
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 5,
"found": true,
"_source": {
"title": "My first blog entry",
"text": "Starting to get the hang of this...",
"tags": ["testing", "search"], <1>
"views": 1 <2>
}
}
search标签已追加到tags数组中。
views字段已递增。
我们甚至可以选择通过设置 ctx.op 为 delete 来删除基于其内容的文档:
POST /website/blog/1/_update
{
"script" : "ctx.op = ctx._source.views == count ? 'delete' : 'none'",
"params" : {
"count": 1
}
}
更新的文档可能尚不存在
假设我们需要 在 Elasticsearch 中存储一个页面访问量计数器。 每当有用户浏览网页,我们对该页面的计数器进行累加。但是,如果它是一个新网页,我们不能确定计数器已经存在。 如果我们尝试更新一个不存在的文档,那么更新操作将会失败。
在这样的情况下,我们可以使用 upsert 参数,指定如果文档不存在就应该先创建它:
POST /website/pageviews/1/_update
{
"script" : "ctx._source.views+=1",
"upsert": {
"views": 1
}
}
我们第一次运行这个请求时, upsert 值作为新文档被索引,初始化 views 字段为 1 。 在后续的运行中,由于文档已经存在, script 更新操作将替代 upsert 进行应用,对 views 计数器进行累加。
更新和冲突
在本节的介绍中,我们说明 检索 和 重建索引 步骤的间隔越小,变更冲突的机会越小。 但是它并不能完全消除冲突的可能性。 还是有可能在 update 设法重新索引之前,来自另一进程的请求修改了文档。
为了避免数据丢失, update API 在 检索 步骤时检索得到文档当前的 _version 号,并传递版本号到 重建索引 步骤的 index 请求。 如果另一个进程修改了处于检索和重新索引步骤之间的文档,那么 _version号将不匹配,更新请求将会失败。
对于部分更新的很多使用场景,文档已经被改变也没有关系。 例如,如果两个进程都对页面访问量计数器进行递增操作,它们发生的先后顺序其实不太重要; 如果冲突发生了,我们唯一需要做的就是尝试再次更新。
这可以通过 设置参数 retry_on_conflict 来自动完成, 这个参数规定了失败之前 update 应该重试的次数,它的默认值为 0 。
POST /website/pageviews/1/_update?retry_on_conflict=5 <1>
{
"script" : "ctx._source.views+=1",
"upsert": {
"views": 0
}
}
在增量操作无关顺序的场景,例如递增计数器等这个方法十分有效,但是在其他情况下变更的顺序 是 非常重要的。 类似 index API , update API 默认采用 最终写入生效 的方案,但它也接受一个 version 参数来允许你使用 optimistic concurrency control 指定想要更新文档的版本。
取回多个文档
Elasticsearch 的速度已经很快了,但甚至能更快。 将多个请求合并成一个,避免单独处理每个请求花费的网络延时和开销。 如果你需要从 Elasticsearch 检索很多文档,那么使用 multi-get 或者 mget API 来将这些检索请求放在一个请求中,将比逐个文档请求更快地检索到全部文档。
mget API 要求有一个 docs 数组作为参数,每个 元素包含需要检索文档的元数据, 包括 _index 、 _type 和 _id 。如果你想检索一个或者多个特定的字段,那么你可以通过 _source 参数来指定这些字段的名字:
GET /_mget
{
"docs" : [
{
"_index" : "website",
"_type" : "blog",
"_id" : 2
},
{
"_index" : "website",
"_type" : "pageviews",
"_id" : 1,
"_source": "views"
}
]
}
该响应体也包含一个 docs 数组 , 对于每一个在请求中指定的文档,这个数组中都包含有一个对应的响应,且顺序与请求中的顺序相同。 其中的每一个响应都和使用单个 get request 请求所得到的响应体相同:
{
"docs" : [
{
"_index" : "website",
"_id" : "2",
"_type" : "blog",
"found" : true,
"_source" : {
"text" : "This is a piece of cake...",
"title" : "My first external blog entry"
},
"_version" : 10
},
{
"_index" : "website",
"_id" : "1",
"_type" : "pageviews",
"found" : true,
"_version" : 2,
"_source" : {
"views" : 2
}
}
]
}
如果想检索的数据都在相同的 _index 中(甚至相同的 _type 中),则可以在 URL 中指定默认的 /_index 或者默认的 /_index/_type 。
你仍然可以通过单独请求覆盖这些值:
GET /website/blog/_mget
{
"docs" : [
{ "_id" : 2 },
{ "_type" : "pageviews", "_id" : 1 }
]
}
事实上,如果所有文档的 _index 和 _type 都是相同的,你可以只传一个 ids 数组,而不是整个 docs 数组:
GET /website/blog/_mget
{
"ids" : [ "2", "1" ]
}
注意,我们请求的第二个文档是不存在的。我们指定类型为 blog ,但是文档 ID 1 的类型是 pageviews,这个不存在的情况将在响应体中被报告:
{
"docs" : [
{
"_index" : "website",
"_type" : "blog",
"_id" : "2",
"_version" : 10,
"found" : true,
"_source" : {
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}
},
{
"_index" : "website",
"_type" : "blog",
"_id" : "1",
"found" : false <1>
}
]
}
事实上第二个文档未能找到并不妨碍第一个文档被检索到。每个文档都是单独检索和报告的。
200。事实上,即使请求 没有找到任何文档,它的状态码依然是200--因为mget请求本身已经成功执行。 为了确定某个文档查找是成功或者失败,你需要检查found标记。
代价较小的批量操作
与 mget 可以使我们一次取回多个文档同样的方式, bulk API 允许在单个步骤中进行多次 create 、 index 、 update 或 delete 请求。 如果你需要索引一个数据流比如日志事件,它可以排队和索引数百或数千批次。
bulk 与其他的请求体格式稍有不同,如下所示:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
这种格式类似一个有效的单行 JSON 文档 流 ,它通过换行符(\n)连接到一起。注意两个要点:
- 每行一定要以换行符(
\n)结尾, 包括最后一行 。这些换行符被用作一个标记,可以有效分隔行。 - 这些行不能包含未转义的换行符,因为他们将会对解析造成干扰。这意味着这个 JSON 不 能使用 pretty 参数打印。 在 为什么是有趣的格式? 中, 我们解释为什么
bulkAPI 使用这种格式。
action/metadata 行指定 哪一个文档 做 什么操作 。
action 必须是以下选项之一:
metadata 应该 指定被索引、创建、更新或者删除的文档的 _index 、 _type 和 _id 。
例如,一个 delete 请求看起来是这样的:
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
request body 行由文档的 _source 本身组成--文档包含的字段和值。它是 index 和 create 操作所必需的,这是有道理的:你必须提供文档以索引。
它也是 update 操作所必需的,并且应该包含你传递给 update API 的相同请求体: doc 、 upsert 、 script 等等。 删除操作不需要 request body 行。
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
如果不指定 _id ,将会自动生成一个 ID :
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
为了把所有的操作组合在一起,一个完整的 bulk 请求 有以下形式:
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }} <1>
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} } <2>
delete动作不能有请求体,它后面跟着的是另外一个操作。
这个 Elasticsearch 响应包含 items 数组, 这个数组的内容是以请求的顺序列出来的每个请求的结果。
{
"took": 4,
"errors": false, <1>
"items": [
{ "delete": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 2,
"status": 200,
"found": true
}},
{ "create": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 3,
"status": 201
}},
{ "create": {
"_index": "website",
"_type": "blog",
"_id": "EiwfApScQiiy7TIKFxRCTw",
"_version": 1,
"status": 201
}},
{ "update": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 4,
"status": 200
}}
]
}
每个子请求都是独立执行,因此某个子请求的失败不会对其他子请求的成功与否造成影响。 如果其中任何子请求失败,最顶层的 error 标志被设置为 true ,并且在相应的请求报告出错误明细:
POST /_bulk
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "Cannot create - it already exists" }
{ "index": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "But we can update it" }
在响应中,我们看到 create 文档 123 失败,因为它已经存在。但是随后的 index 请求,也是对文档 123 操作,就成功了:
{
"took": 3,
"errors": true, <1>
"items": [
{ "create": {
"_index": "website",
"_type": "blog",
"_id": "123",
"status": 409, <2>
"error": "DocumentAlreadyExistsException <3>
[[website][4] [blog][123]:
document already exists]"
}},
{ "index": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 5,
"status": 200 <4>
}}
]
}
409 CONFLICT。
解释为什么请求失败的错误信息。
第二个请求成功,返回 HTTP 状态码
200 OK。
这也意味着 bulk 请求不是原子的: 不能用它来实现事务控制。每个请求是单独处理的,因此一个请求的成功或失败不会影响其他的请求。
不要重复指定Index和Type
也许你正在批量索引日志数据到相同的 index 和 type 中。 但为每一个文档指定相同的元数据是一种浪费。相反,可以像 mget API 一样,在 bulk 请求的 URL 中接收默认的 /_index 或者 /_index/_type :
POST /website/_bulk
{ "index": { "_type": "log" }}
{ "event": "User logged in" }
你仍然可以覆盖元数据行中的 _index 和 _type , 但是它将使用 URL 中的这些元数据值作为默认值:
POST /website/log/_bulk
{ "index": {}}
{ "event": "User logged in" }
{ "index": { "_type": "blog" }}
{ "title": "Overriding the default type" }
多大是太大了?
整个批量请求都需要由接收到请求的节点加载到内存中,因此该请求越大,其他请求所能获得的内存就越少。 批量请求的大小有一个最佳值,大于这个值,性能将不再提升,甚至会下降。 但是最佳值不是一个固定的值。它完全取决于硬件、文档的大小和复杂度、索引和搜索的负载的整体情况。
幸运的是,很容易找到这个 最佳点 :通过批量索引典型文档,并不断增加批量大小进行尝试。 当性能开始下降,那么你的批量大小就太大了。一个好的办法是开始时将 1,000 到 5,000 个文档作为一个批次, 如果你的文档非常大,那么就减少批量的文档个数。
密切关注你的批量请求的物理大小往往非常有用,一千个 1KB 的文档是完全不同于一千个 1MB 文档所占的物理大小。 一个好的批量大小在开始处理后所占用的物理大小约为 5-15 MB。