基础入门
分布式文档存储
在前面的章节,我们介绍了如何索引和查询数据,不过我们忽略了很多底层的技术细节, 例如文件是如何分布到集群的,又是如何从集群中获取的。 Elasticsearch 本意就是隐藏这些底层细节,让我们好专注在业务开发中,所以其实你不必了解这么深入也无妨。
在这个章节中,我们将深入探索这些核心的技术细节,这能帮助你更好地理解数据如何被存储到这个分布式系统中。
注意
这个章节包含了一些高级话题,上面也提到过,就算你不记住和理解所有的细节仍然能正常使用 > Elasticsearch。 如果你有兴趣的话,这个章节可以作为你的课外兴趣读物,扩展你的知识面。
如果你在阅读这个章节的时候感到很吃力,也不用担心。 这个章节仅仅只是用来告诉你 Elasticsearch 是如何工作的, 将来在工作中如果你需要用到这个章节提供的知识,可以再回过头来翻阅。
路由一个文档到一个分片中
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
你可能觉得由于 Elasticsearch 主分片数量是固定的会使索引难以进行扩容。实际上当你需要时有很多技巧可以轻松实现扩容。我们将会在扩容设计一章中提到更多有关水平扩展的内容。
所有的文档 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一个叫做 routing的路由参数 ,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。我们也会在扩容设计这一章中详细讨论为什么会有这样一种需求。
主分片和副本分片如何交互
为了说明目的, 我们 假设有一个集群由三个节点组成。 它包含一个叫 blogs 的索引,有两个主分片,每个主分片有两个副本分片。相同分片的副本不会放在同一节点,所以我们的集群看起来像 图 8 “有三个节点和一个索引的集群”。
图 8. 有三个节点和一个索引的集群
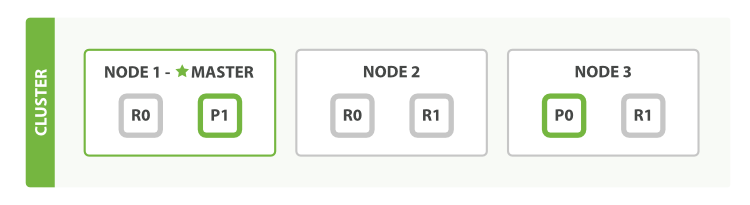
我们可以发送请求到集群中的任一节点。 每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。 在下面的例子中,将所有的请求发送到 Node 1 ,我们将其称为 协调节点(coordinating node) 。
当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点。
新建、索引和删除文档
新建、索引和删除 请求都是 写 操作, 必须在主分片上面完成之后才能被复制到相关的副本分片,如下图所示 图 9 “新建、索引和删除单个文档”.
图 9. 新建、索引和删除单个文档
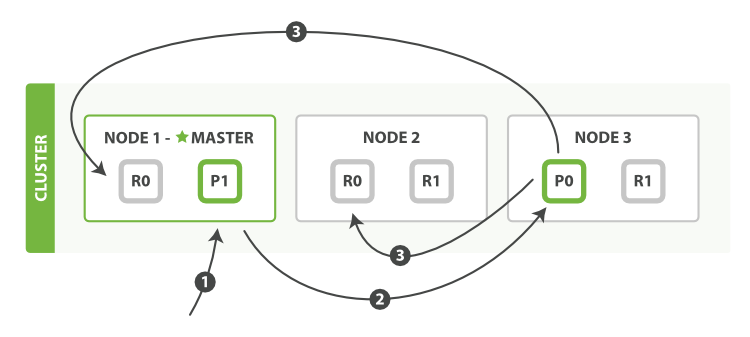
以下是在主副分片和任何副本分片上面 成功新建,索引和删除文档所需要的步骤顺序:
- 客户端向
Node 1发送新建、索引或者删除请求。 - 节点使用文档的
_id确定文档属于分片 0 。请求会被转发到Node 3,因为分片 0 的主分片目前被分配在Node 3上。 Node 3在主分片上面执行请求。如果成功了,它将请求并行转发到Node 1和Node 2的副本分片上。一旦所有的副本分片都报告成功,Node 3将向协调节点报告成功,协调节点向客户端报告成功。
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。
有一些可选的请求参数允许您影响这个过程,可能以数据安全为代价提升性能。这些选项很少使用,因为Elasticsearch已经很快,但是为了完整起见,在这里阐述如下:
consistencyconsistency,即一致性。在默认设置下,即使仅仅是在试图执行一个写操作之前,主分片都会要求必须要有 规定数量(quorum)(或者换种说法,也即必须要有大多数)的分片副本处于活跃可用状态,才会去执行写操作(其中分片副本可以是主分片或者副本分片)。这是为了避免在发生网络分区故障(network partition)的时候进行写操作,进而导致数据不一致。规定数量即:
int( (primary + number_of_replicas) / 2 ) + 1``consistency参数的值可以设为one(只要主分片状态 ok 就允许执行写操作),all(必须要主分片和所有副本分片的状态没问题才允许执行写操作), 或quorum。默认值为quorum, 即大多数的分片副本状态没问题就允许执行写操作。注意,规定数量 的计算公式中number_of_replicas指的是在索引设置中的设定副本分片数,而不是指当前处理活动状态的副本分片数。如果你的索引设置中指定了当前索引拥有三个副本分片,那规定数量的计算结果即:int( (primary + 3 replicas) / 2 ) + 1 = 3如果此时你只启动两个节点,那么处于活跃状态的分片副本数量就达不到规定数量,也因此您将无法索引和删除任何文档。timeout如果没有足够的副本分片会发生什么? Elasticsearch会等待,希望更多的分片出现。默认情况下,它最多等待1分钟。 如果你需要,你可以使用
timeout参数 使它更早终止:100100毫秒,30s是30秒。 新索引默认有 1个副本分片,这意味着为满足规定数量应该 需要两个活动的分片副本。 但是,这些默认的设置会阻止我们在单一节点上做任何事情。为了避免这个问题,要求只有当number_of_replicas大于1的时候,规定数量才会执行。
取回一个文档
可以从主分片或者从其它任意副本分片检索文档 ,如下图所示 图 10 “取回单个文档”.
图 10. 取回单个文档
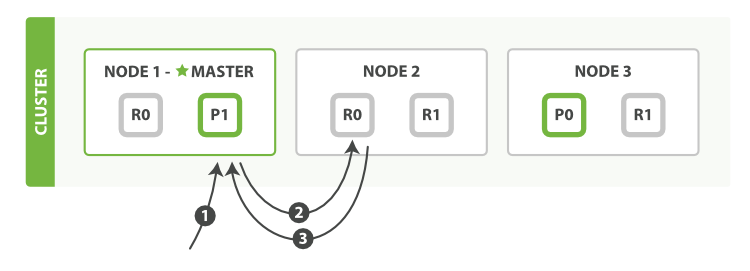
以下是从主分片或者副本分片检索文档的步骤顺序:
1、客户端向 Node 1 发送获取请求。
2、节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个节点上。 在这种情况下,它将请求转发到 Node 2 。
3、Node 2 将文档返回给 Node 1 ,然后将文档返回给客户端。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
局部更新文档
如 图 11 “局部更新文档” 所示,update API 结合了先前说明的读取和写入模式 。
图 11. 局部更新文档
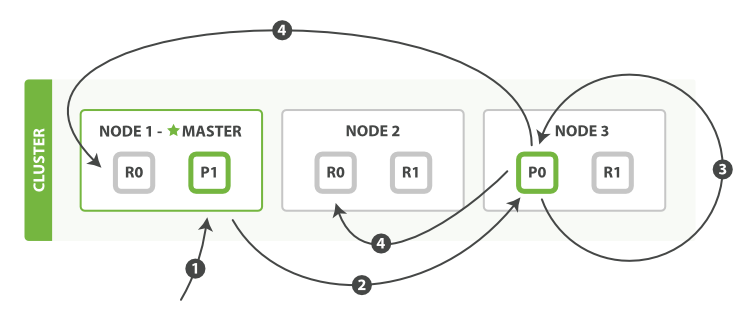
以下是部分更新一个文档的步骤:
- 客户端向
Node 1发送更新请求。 - 它将请求转发到主分片所在的
Node 3。 Node 3从主分片检索文档,修改_source字段中的 JSON ,并且尝试重新索引主分片的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过retry_on_conflict次后放弃。- 如果
Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和Node 2上的副本分片,重新建立索引。 一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
update API 还接受在 新建、索引和删除文档 章节中介绍的 routing 、 replication 、 consistency 和 timeout 参数。
基于文档的复制
当主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。请记住,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。 如果Elasticsearch仅转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档。
多文档模式
mget 和 bulk API 的 模式类似于单文档模式。区别在于协调节点知道每个文档存在于哪个分片中。 它将整个多文档请求分解成 每个分片 的多文档请求,并且将这些请求并行转发到每个参与节点。
协调节点一旦收到来自每个节点的应答,就将每个节点的响应收集整理成单个响应,返回给客户端,如 图 12 “使用 mget 取回多个文档” 所示。
图 12. 使用 mget 取回多个文档
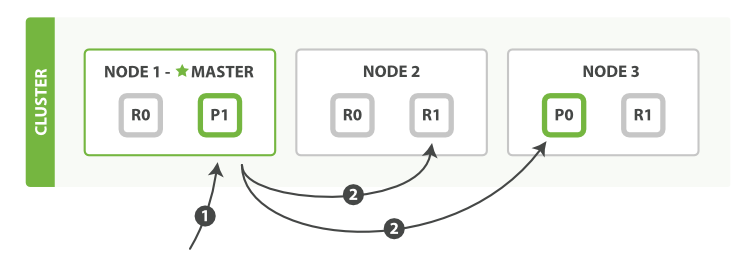
以下是使用单个 mget 请求取回多个文档所需的步骤顺序:
- 客户端向
Node 1发送mget请求。 Node 1为每个分片构建多文档获取请求,然后并行转发这些请求到托管在每个所需的主分片或者副本分片的节点上。一旦收到所有答复,Node 1构建响应并将其返回给客户端。
可以对 docs 数组中每个文档设置 routing 参数。
bulk API, 如 图 13 “使用 bulk 修改多个文档” 所示, 允许在单个批量请求中执行多个创建、索引、删除和更新请求。
图 13. 使用 bulk 修改多个文档
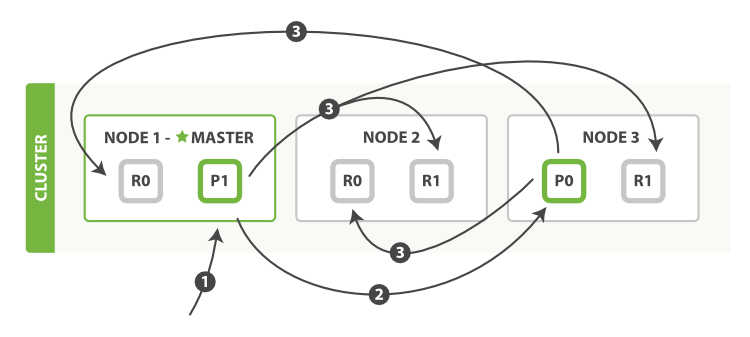
bulk API 按如下步骤顺序执行:
- 客户端向
Node 1发送bulk请求。 Node 1为每个节点创建一个批量请求,并将这些请求并行转发到每个包含主分片的节点主机。- 主分片一个接一个按顺序执行每个操作。当每个操作成功时,主分片并行转发新文档(或删除)到副本分片,然后执行下一个操作。 一旦所有的副本分片报告所有操作成功,该节点将向协调节点报告成功,协调节点将这些响应收集整理并返回给客户端。
bulk API 还可以在整个批量请求的最顶层使用 consistency 参数,以及在每个请求中的元数据中使用 routing 参数。
为什么是有趣的格式?
当我们早些时候在代价较小的批量操作章节了解批量请求时, 您可能会问自己, "为什么 bulk API 需要有换行符的有趣格式,而不是发送包装在 JSON 数组中的请求,例如 mget API?" 。
为了回答这一点,我们需要解释一点背景:在批量请求中引用的每个文档可能属于不同的主分片, 每个文档可能被分配给集群中的任何节点。这意味着批量请求 bulk 中的每个 操作 都需要被转发到正确节点上的正确分片。
如果单个请求被包装在 JSON 数组中,那就意味着我们需要执行以下操作:
- 将 JSON 解析为数组(包括文档数据,可以非常大)
- 查看每个请求以确定应该去哪个分片
- 为每个分片创建一个请求数组
- 将这些数组序列化为内部传输格式
- 将请求发送到每个分片
这是可行的,但需要大量的 RAM 来存储原本相同的数据的副本,并将创建更多的数据结构,Java虚拟机(JVM)将不得不花费时间进行垃圾回收。
相反,Elasticsearch可以直接读取被网络缓冲区接收的原始数据。 它使用换行符字符来识别和解析小的 action/metadata 行来决定哪个分片应该处理每个请求。
这些原始请求会被直接转发到正确的分片。没有冗余的数据复制,没有浪费的数据结构。整个请求尽可能在最小的内存中处理。
搜索——最基本的工具
现在,我们已经学会了如何使用 Elasticsearch 作为一个简单的 NoSQL 风格的分布式文档存储系统。我们可以将一个 JSON 文档扔到 Elasticsearch 里,然后根据 ID 检索。但 Elasticsearch 真正强大之处在于可以从无规律的数据中找出有意义的信息——从“大数据”到“大信息”。
Elasticsearch 不只会存储(stores) 文档,为了能被搜索到也会为文档添加索引(indexes) ,这也是为什么我们使用结构化的 JSON 文档,而不是无结构的二进制数据。
文档中的每个字段都将被索引并且可以被查询 。不仅如此,在简单查询时,Elasticsearch 可以使用 所有(all) 这些索引字段,以惊人的速度返回结果。这是你永远不会考虑用传统数据库去做的一些事情。
搜索(search) 可以做到:
- 在类似于
gender或者age这样的字段 上使用结构化查询,join_date这样的字段上使用排序,就像SQL的结构化查询一样。 - 全文检索,找出所有匹配关键字的文档并按照相关性(relevance) 排序后返回结果。
- 以上二者兼而有之。
很多搜索都是开箱即用的,为了充分挖掘 Elasticsearch 的潜力,你需要理解以下三个概念:
映射(Mapping)
描述数据在每个字段内如何存储
分析(Analysis)
全文是如何处理使之可以被搜索的
领域特定查询语言(Query DSL)
Elasticsearch 中强大灵活的查询语言
以上提到的每个点都是一个大话题,我们将在 深入搜索 一章详细阐述它们。本章节我们将介绍这三点的一些基本概念——仅仅帮助你大致了解搜索是如何工作的。
我们将使用最简单的形式开始介绍 search API。
测试数据
本章节的测试数据可以在这里找到: https://gist.github.com/clintongormley/8579281 。
你可以把这些命令复制到终端中执行来实践本章的例子。
另外,如果你读的是在线版本,可以 点击这个链接 感受下。
空搜索
搜索API的最基础的形式是没有指定任何查询的空搜索 ,它简单地返回集群中所有索引下的所有文档:
GET /_search
返回的结果(为了界面简洁编辑过的)像这样:
{
"hits" : {
"total" : 14,
"hits" : [
{
"_index": "us",
"_type": "tweet",
"_id": "7",
"_score": 1,
"_source": {
"date": "2014-09-17",
"name": "John Smith",
"tweet": "The Query DSL is really powerful and flexible",
"user_id": 2
}
},
... 9 RESULTS REMOVED ...
],
"max_score" : 1
},
"took" : 4,
"_shards" : {
"failed" : 0,
"successful" : 10,
"total" : 10
},
"timed_out" : false
}
hits
返回结果中最重要的部分是 hits ,它 包含 total 字段来表示匹配到的文档总数,并且一个 hits 数组包含所查询结果的前十个文档。
在 hits 数组中每个结果包含文档的 _index 、 _type 、 _id ,加上 _source 字段。这意味着我们可以直接从返回的搜索结果中使用整个文档。这不像其他的搜索引擎,仅仅返回文档的ID,需要你单独去获取文档。
每个结果还有一个 _score ,它衡量了文档与查询的匹配程度。默认情况下,首先返回最相关的文档结果,就是说,返回的文档是按照 _score 降序排列的。在这个例子中,我们没有指定任何查询,故所有的文档具有相同的相关性,因此对所有的结果而言 1 是中性的 _score 。
max_score 值是与查询所匹配文档的 _score 的最大值。
took
took 值告诉我们执行整个搜索请求耗费了多少毫秒。
shards
_shards 部分 告诉我们在查询中参与分片的总数,以及这些分片成功了多少个失败了多少个。正常情况下我们不希望分片失败,但是分片失败是可能发生的。如果我们遭遇到一种灾难级别的故障,在这个故障中丢失了相同分片的原始数据和副本,那么对这个分片将没有可用副本来对搜索请求作出响应。假若这样,Elasticsearch 将报告这个分片是失败的,但是会继续返回剩余分片的结果。
timeout
timed_out 值告诉我们查询是否超时。默认情况下,搜索请求不会超时。 如果低响应时间比完成结果更重要,你可以指定 timeout 为 10 或者 10ms(10毫秒),或者 1s(1秒):
GET /_search?timeout=10ms
在请求超时之前,Elasticsearch 将会返回已经成功从每个分片获取的结果。
应当注意的是
timeout不是停止执行查询,它仅仅是告知正在协调的节点返回到目前为止收集的结果并且关闭连接。在后台,其他的分片可能仍在执行查询即使是结果已经被发送了。使用超时是因为 SLA(服务等级协议)对你是很重要的,而不是因为想去中止长时间运行的查询。
多索引,多类型
你有没有注意到之前的 empty search 的结果,不同类型的文档 — user 和 tweet 来自不同的索引— us和 gb ?
如果不对某一特殊的索引或者类型做限制,就会搜索集群中的所有文档。Elasticsearch 转发搜索请求到每一个主分片或者副本分片,汇集查询出的前10个结果,并且返回给我们。
然而,经常的情况下,你 想在一个或多个特殊的索引并且在一个或者多个特殊的类型中进行搜索。我们可以通过在URL中指定特殊的索引和类型达到这种效果,如下所示:
/_search在所有的索引中搜索所有的类型
/gb/_search在
gb索引中搜索所有的类型/gb,us/_search在
gb和us索引中搜索所有的文档/g*,u*/_search在任何以
g或者u开头的索引中搜索所有的类型/gb/user/_search在
gb索引中搜索user类型/gb,us/user,tweet/_search在
gb和us索引中搜索user和tweet类型/_all/user,tweet/_search在所有的索引中搜索
user和tweet类型
当在单一的索引下进行搜索的时候,Elasticsearch 转发请求到索引的每个分片中,可以是主分片也可以是副本分片,然后从每个分片中收集结果。多索引搜索恰好也是用相同的方式工作的--只是会涉及到更多的分片。
接下来,你将明白这种简单的方式如何灵活的根据需求的变化让扩容变得简单。
分页
在之前的 空搜索 中说明了集群中有 14 个文档匹配了(empty)query 。 但是在 hits 数组中只有 10 个文档。如何才能看到其他的文档?
和 SQL 使用 LIMIT 关键字返回单个 page 结果的方法相同,Elasticsearch 接受 from 和 size 参数:
size显示应该返回的结果数量,默认是
10from显示应该跳过的初始结果数量,默认是
0
如果每页展示 5 条结果,可以用下面方式请求得到 1 到 3 页的结果:
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10
考虑到分页过深以及一次请求太多结果的情况,结果集在返回之前先进行排序。 但请记住一个请求经常跨越多个分片,每个分片都产生自己的排序结果,这些结果需要进行集中排序以保证整体顺序是正确的。
在分布式系统中深度分页
理解为什么深度分页是有问题的,我们可以假设在一个有 5 个主分片的索引中搜索。 当我们请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 50 个结果排序得到全部结果的前 10 个。
现在假设我们请求第 1000 页--结果从 10001 到 10010 。所有都以相同的方式工作除了每个分片不得不产生前10010个结果以外。 然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的 50040 个结果。
可以看到,在分布式系统中,对结果排序的成本随分页的深度成指数上升。这就是 web 搜索引擎对任何查询都不要返回超过 1000 个结果的原因。
轻量搜索
有两种形式的 搜索 API:一种是 “轻量的” 查询字符串 版本,要求在查询字符串中传递所有的 参数,另一种是更完整的 请求体 版本,要求使用 JSON 格式和更丰富的查询表达式作为搜索语言。
查询字符串搜索非常适用于通过命令行做即席查询。例如,查询在 tweet 类型中 tweet 字段包含 elasticsearch 单词的所有文档:
GET /_all/tweet/_search?q=tweet:elasticsearch
拷贝为 CURL在 SENSE 中查看
下一个查询在 name 字段中包含 john 并且在 tweet 字段中包含 mary 的文档。实际的查询就是这样
+name:john +tweet:mary
但是查询字符串参数所需要的 百分比编码 (译者注:URL编码)实际上更加难懂:
GET /_search?q=%2Bname%3Ajohn+%2Btweet%3Amary
拷贝为 CURL在 SENSE 中查看
+ 前缀表示必须与查询条件匹配。类似地, - 前缀表示一定不与查询条件匹配。没有 + 或者 - 的所有其他条件都是可选的——匹配的越多,文档就越相关。
_all 字段
这个简单搜索返回包含 mary 的所有文档:
GET /_search?q=mary
拷贝为 CURL在 SENSE 中查看
之前的例子中,我们在 tweet 和 name 字段中搜索内容。然而,这个查询的结果在三个地方提到了 mary:
- 有一个用户叫做 Mary
- 6条微博发自 Mary
- 一条微博直接 @mary
Elasticsearch 是如何在三个不同的字段中查找到结果的呢?
当索引一个文档的时候,Elasticsearch 取出所有字段的值拼接成一个大的字符串,作为 _all 字段进行索引。例如,当索引这个文档时:
{
"tweet": "However did I manage before Elasticsearch?",
"date": "2014-09-14",
"name": "Mary Jones",
"user_id": 1
}
这就好似增加了一个名叫 _all 的额外字段:
"However did I manage before Elasticsearch? 2014-09-14 Mary Jones 1"
除非设置特定字段,否则查询字符串就使用 _all 字段进行搜索。
_all字段是一个很实用的特性。之后,你会发现如果搜索时用指定字段来代替_all字段,将会更好控制搜索结果。当_all字段不再有用的时候,可以将它置为失效,正如在 元数据: _all 字段 中所解释的。
更复杂的查询
下面的查询针对tweents类型,并使用以下的条件:
name字段中包含mary或者johndate值大于2014-09-10_all字段包含aggregations或者geo
+name:(mary john) +date:>2014-09-10 +(aggregations geo)
拷贝为 CURL在 SENSE 中查看
查询字符串在做了适当的编码后,可读性很差:
?q=%2Bname%3A(mary+john)+%2Bdate%3A%3E2014-09-10+%2B(aggregations+geo)
从之前的例子中可以看出,这种 轻量 的查询字符串搜索效果还是挺让人惊喜的。 它的查询语法在相关参考文档中有详细解释,以便简洁的表达很复杂的查询。对于通过命令做一次性查询,或者是在开发阶段,都非常方便。
但同时也可以看到,这种精简让调试更加晦涩和困难。而且很脆弱,一些查询字符串中很小的语法错误,像 - , : , / 或者 " 不匹配等,将会返回错误而不是搜索结果。
最后,查询字符串搜索允许任何用户在索引的任意字段上执行可能较慢且重量级的查询,这可能会暴露隐私信息,甚至将集群拖垮。
相反,我们经常在生产环境中更多地使用功能全面的 request body 查询API,除了能完成以上所有功能,还有一些附加功能。但在到达那个阶段之前,首先需要了解数据在 Elasticsearch 中是如何被索引的。
映射和分析
当摆弄索引里面的数据时,我们发现一些奇怪的事情。一些事情看起来被打乱了:在我们的索引中有12条推文,其中只有一条包含日期 2014-09-15 ,但是看一看下面查询命中的 总数 (total):
GET /_search?q=2014 # 12 results
GET /_search?q=2014-09-15 # 12 results !
GET /_search?q=date:2014-09-15 # 1 result
GET /_search?q=date:2014 # 0 results !
为什么在 _all 字段查询日期返回所有推文,而在 date 字段只查询年份却没有返回结果?为什么我们在 _all 字段和 date 字段的查询结果有差别?
推测起来,这是因为数据在 _all 字段与 date 字段的索引方式不同。所以,通过请求 gb 索引中 tweet类型的映射(或模式定义),让我们看一看 Elasticsearch 是如何解释我们文档结构的:
GET /gb/_mapping/tweet
这将得到如下结果:
{
"gb": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"name": {
"type": "string"
},
"tweet": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}
}
基于对字段类型的猜测, Elasticsearch 动态为我们产生了一个映射。这个响应告诉我们 date 字段被认为是 date 类型的。由于 _all 是默认字段,所以没有提及它。但是我们知道 _all 字段是 string 类型的。
所以 date 字段和 string 字段 索引方式不同,因此搜索结果也不一样。这完全不令人吃惊。你可能会认为 核心数据类型 strings、numbers、Booleans 和 dates 的索引方式有稍许不同。没错,他们确实稍有不同。
但是,到目前为止,最大的差异在于 代表 精确值 (它包括 string 字段)的字段和代表 全文 的字段。这个区别非常重要——它将搜索引擎和所有其他数据库区别开来。
精确值 VS 全文
Elasticsearch 中的数据可以概括的分为两类:精确值和全文。
精确值 如它们听起来那样精确。例如日期或者用户 ID,但字符串也可以表示精确值,例如用户名或邮箱地址。对于精确值来讲,Foo 和 foo 是不同的,2014 和 2014-09-15 也是不同的。
另一方面,全文 是指文本数据(通常以人类容易识别的语言书写),例如一个推文的内容或一封邮件的内容。
May is fun but June bores me.
它指的是月份还是人?
精确值很容易查询。结果是二进制的:要么匹配查询,要么不匹配。这种查询很容易用 SQL 表示:
WHERE name = "John Smith"
AND user_id = 2
AND date > "2014-09-15"
查询全文数据要微妙的多。我们问的不只是“这个文档匹配查询吗”,而是“该文档匹配查询的程度有多大?”换句话说,该文档与给定查询的相关性如何?
我们很少对全文类型的域做精确匹配。相反,我们希望在文本类型的域中搜索。不仅如此,我们还希望搜索能够理解我们的 意图 :
- 搜索
UK,会返回包含United Kindom的文档。 - 搜索
jump,会匹配jumped,jumps,jumping,甚至是leap。 - 搜索
johnny walker会匹配Johnnie Walker,johnnie depp应该匹配Johnny Depp。 fox news hunting应该返回福克斯新闻( Foxs News )中关于狩猎的故事,同时,fox hunting news应该返回关于猎狐的故事。
为了促进这类在全文域中的查询,Elasticsearch 首先 分析 文档,之后根据结果创建 倒排索引 。在接下来的两节,我们会讨论倒排索引和分析过程。
倒排索引
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,我们首先将每个文档的 content 域拆分成单独的 词(我们称它为 词条 或 tokens),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:
Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
------------------------
现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
Term Doc_1 Doc_2
-------------------------
brown | X | X
quick | X |
------------------------
Total | 2 | 1
两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
但是,我们目前的倒排索引有一些问题:
Quick和quick以独立的词条出现,然而用户可能认为它们是相同的词。fox和foxes非常相似, 就像dog和dogs;他们有相同的词根。jumped和leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词。
使用前面的索引搜索 +Quick +fox 不会得到任何匹配文档。(记住,+ 前缀表明这个词必须存在。)只有同时出现 Quick 和 fox 的文档才满足这个查询条件,但是第一个文档包含 quick fox ,第二个文档包含 Quick foxes 。
我们的用户可以合理的期望两个文档与查询匹配。我们可以做的更好。
如果我们将词条规范为标准模式,那么我们可以找到与用户搜索的词条不完全一致,但具有足够相关性的文档。例如:
Quick可以小写化为quick。foxes可以 词干提取 --变为词根的格式-- 为fox。类似的,dogs可以为提取为dog。jumped和leap是同义词,可以索引为相同的单词jump。
现在索引看上去像这样:
Term Doc_1 Doc_2
-------------------------
brown | X | X
dog | X | X
fox | X | X
in | | X
jump | X | X
lazy | X | X
over | X | X
quick | X | X
summer | | X
the | X | X
------------------------
这还远远不够。我们搜索 +Quick +fox 仍然 会失败,因为在我们的索引中,已经没有 Quick 了。但是,如果我们对搜索的字符串使用与 content 域相同的标准化规则,会变成查询 +quick +fox ,这样两个文档都会匹配!
分词和标准化的过程称为 分析 , 我们会在下个章节讨论。
分析与分析器
分析 包含下面的过程:
- 首先,将一块文本分成适合于倒排索引的独立的 词条 ,
- 之后,将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
分析器执行上面的工作。 分析器 实际上是将三个功能封装到了一个包里:
字符过滤器
首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉HTML,或者将
&转化成and。分词器
其次,字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。
Token 过滤器
最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化
Quick),删除词条(例如, 像a,and,the等无用词),或者增加词条(例如,像jump和leap这种同义词)。
Elasticsearch提供了开箱即用的字符过滤器、分词器和token 过滤器。 这些可以组合起来形成自定义的分析器以用于不同的目的。我们会在 自定义分析器 章节详细讨论。
内置分析器
但是, Elasticsearch还附带了可以直接使用的预包装的分析器。 接下来我们会列出最重要的分析器。为了证明它们的差异,我们看看每个分析器会从下面的字符串得到哪些词条:
"Set the shape to semi-transparent by calling set_trans(5)"
标准分析器
标准分析器是Elasticsearch默认使用的分析器。它是分析各种语言文本最常用的选择。它根据 Unicode 联盟 定义的 单词边界 划分文本。删除绝大部分标点。最后,将词条小写。它会产生
set, the, shape, to, semi, transparent, by, calling, set_trans, 5简单分析器
简单分析器在任何不是字母的地方分隔文本,将词条小写。它会产生
set, the, shape, to, semi, transparent, by, calling, set, trans空格分析器
空格分析器在空格的地方划分文本。它会产生
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)语言分析器
特定语言分析器可用于 很多语言。它们可以考虑指定语言的特点。例如,
英语分析器附带了一组英语无用词(常用单词,例如and或者the,它们对相关性没有多少影响),它们会被删除。 由于理解英语语法的规则,这个分词器可以提取英语单词的 词干 。英语分词器会产生下面的词条:set, shape, semi, transpar, call, set_tran, 5注意看transparent、calling和set_trans已经变为词根格式。
什么时候使用分析器
当我们 索引 一个文档,它的全文域被分析成词条以用来创建倒排索引。 但是,当我们在全文域 搜索 的时候,我们需要将查询字符串通过 相同的分析过程 ,以保证我们搜索的词条格式与索引中的词条格式一致。
全文查询,理解每个域是如何定义的,因此它们可以做 正确的事:
- 当你查询一个 全文 域时, 会对查询字符串应用相同的分析器,以产生正确的搜索词条列表。
- 当你查询一个 精确值 域时,不会分析查询字符串, 而是搜索你指定的精确值。
现在你可以理解在 开始章节 的查询为什么返回那样的结果:
date域包含一个精确值:单独的词条2014-09-15。_all域是一个全文域,所以分词进程将日期转化为三个词条:2014,09, 和15。
当我们在 _all 域查询 2014,它匹配所有的12条推文,因为它们都含有 2014 :
GET /_search?q=2014 # 12 results
当我们在 _all 域查询 2014-09-15,它首先分析查询字符串,产生匹配 2014, 09, 或 15 中 任意 词条的查询。这也会匹配所有12条推文,因为它们都含有 2014 :
GET /_search?q=2014-09-15 # 12 results !
当我们在 date 域查询 2014-09-15,它寻找 精确 日期,只找到一个推文:
GET /_search?q=date:2014-09-15 # 1 result
当我们在 date 域查询 2014,它找不到任何文档,因为没有文档含有这个精确日志:
GET /_search?q=date:2014 # 0 results !
测试分析器
有些时候很难理解分词的过程和实际被存储到索引中的词条,特别是你刚接触 Elasticsearch。为了理解发生了什么,你可以使用 analyze API 来看文本是如何被分析的。在消息体里,指定分析器和要分析的文本:
GET /_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}
拷贝为 CURL在 SENSE 中查看
结果中每个元素代表一个单独的词条:
{
"tokens": [
{
"token": "text",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "to",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "analyze",
"start_offset": 8,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 3
}
]
}
token 是实际存储到索引中的词条。 position 指明词条在原始文本中出现的位置。 start_offset 和 end_offset 指明字符在原始字符串中的位置。
type值都不一样,可以忽略它们。它们在Elasticsearch中的唯一作用在于keep_typestoken 过滤器。
analyze API 是一个有用的工具,它有助于我们理解Elasticsearch索引内部发生了什么,随着深入,我们会进一步讨论它。
指定分析器
当Elasticsearch在你的文档中检测到一个新的字符串域 ,它会自动设置其为一个全文 字符串 域,使用 标准 分析器对它进行分析。
你不希望总是这样。可能你想使用一个不同的分析器,适用于你的数据使用的语言。有时候你想要一个字符串域就是一个字符串域--不使用分析,直接索引你传入的精确值,例如用户ID或者一个内部的状态域或标签。
要做到这一点,我们必须手动指定这些域的映射。
映射
为了能够将时间域视为时间,数字域视为数字,字符串域视为全文或精确值字符串, Elasticsearch 需要知道每个域中数据的类型。这个信息包含在映射中。
如 数据输入和输出 中解释的, 索引中每个文档都有 类型 。每种类型都有它自己的 映射 ,或者 模式定义。映射定义了类型中的域,每个域的数据类型,以及Elasticsearch如何处理这些域。映射也用于配置与类型有关的元数据。
我们会在 类型和映射 详细讨论映射。本节,我们只讨论足够让你入门的内容。
核心简单域类型
Elasticsearch 支持 如下简单域类型:
- 字符串:
string - 整数 :
byte,short,integer,long - 浮点数:
float,double - 布尔型:
boolean - 日期:
date
当你索引一个包含新域的文档--之前未曾出现-- Elasticsearch 会使用 动态映射 ,通过JSON中基本数据类型,尝试猜测域类型,使用如下规则:
| JSON type | 域 type |
|---|---|
布尔型: true 或者 false |
boolean |
整数: 123 |
long |
浮点数: 123.45 |
double |
字符串,有效日期: 2014-09-15 |
date |
字符串: foo bar |
string |
"123")索引一个数字,它会被映射为string类型,而不是long。但是,如果这个域已经映射为long,那么 Elasticsearch 会尝试将这个字符串转化为 long ,如果无法转化,则抛出一个异常。
查看映射
通过 /_mapping ,我们可以查看 Elasticsearch 在一个或多个索引中的一个或多个类型的映射 。在 开始章节 ,我们已经取得索引 gb 中类型 tweet 的映射:
GET /gb/_mapping/tweet
Elasticsearch 根据我们索引的文档,为域(称为 属性 )动态生成的映射。
{
"gb": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"name": {
"type": "string"
},
"tweet": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}
}
age域映射为string类型,而不是integer,会导致查询出现令人困惑的结果。
检查一下!而不是假设你的映射是正确的。
自定义域映射
尽管在很多情况下基本域数据类型 已经够用,但你经常需要为单独域自定义映射 ,特别是字符串域。自定义映射允许你执行下面的操作:
- 全文字符串域和精确值字符串域的区别
- 使用特定语言分析器
- 优化域以适应部分匹配
- 指定自定义数据格式
- 还有更多
域最重要的属性是 type 。对于不是 string 的域,你一般只需要设置 type :
{
"number_of_clicks": {
"type": "integer"
}
}
默认, string 类型域会被认为包含全文。就是说,它们的值在索引前,会通过 一个分析器,针对于这个域的查询在搜索前也会经过一个分析器。
string 域映射的两个最重要 属性是 index 和 analyzer 。
index
index 属性控制怎样索引字符串。它可以是下面三个值:
analyzed首先分析字符串,然后索引它。换句话说,以全文索引这个域。
not_analyzed索引这个域,所以它能够被搜索,但索引的是精确值。不会对它进行分析。
no不索引这个域。这个域不会被搜索到。
string 域 index 属性默认是 analyzed 。如果我们想映射这个字段为一个精确值,我们需要设置它为 not_analyzed :
{
"tag": {
"type": "string",
"index": "not_analyzed"
}
}
long,double,date等)也接受index参数,但有意义的值只有no和not_analyzed, 因为它们永远不会被分析。
analyzer
对于 analyzed 字符串域,用 analyzer 属性指定在搜索和索引时使用的分析器。默认, Elasticsearch 使用 standard 分析器, 但你可以指定一个内置的分析器替代它,例如 whitespace 、 simple 和 english:
{
"tweet": {
"type": "string",
"analyzer": "english"
}
}
在 自定义分析器 ,我们会展示怎样定义和使用自定义分析器。
更新映射
当你首次 创建一个索引的时候,可以指定类型的映射。你也可以使用 /_mapping 为新类型(或者为存在的类型更新映射)增加映射。
我们可以更新一个映射来添加一个新域,但不能将一个存在的域从 analyzed 改为 not_analyzed 。
为了描述指定映射的两种方式,我们先删除 gd 索引:
DELETE /gb
然后创建一个新索引,指定 tweet 域使用 english 分析器:
PUT /gb <1>
{
"mappings": {
"tweet" : {
"properties" : {
"tweet" : {
"type" : "string",
"analyzer": "english"
},
"date" : {
"type" : "date"
},
"name" : {
"type" : "string"
},
"user_id" : {
"type" : "long"
}
}
}
}
}
通过消息体中指定的
mappings创建了索引。
稍后,我们决定在 tweet 映射增加一个新的名为 tag 的 not_analyzed 的文本域,使用 _mapping :
PUT /gb/_mapping/tweet
{
"properties" : {
"tag" : {
"type" : "string",
"index": "not_analyzed"
}
}
}
注意,我们不需要再次列出所有已存在的域,因为无论如何我们都无法改变它们。新域已经被合并到存在的映射中。
测试映射
你可以使用 analyze API 测试字符串域的映射。比较下面两个请求的输出:
GET /gb/_analyze
{
"field": "tweet",
"text": "Black-cats" <1>
}
GET /gb/_analyze
{
"field": "tag",
"text": "Black-cats" <2>
}
消息体里面传输我们想要分析的文本。
tweet 域产生两个词条 black 和 cat , tag 域产生单独的词条 Black-cats 。换句话说,我们的映射正常工作。
复杂核心域类型
除了我们提到的简单标量数据类型, JSON 还有 null 值,数组,和对象,这些 Elasticsearch 都是支持的。
多值域
很有可能,我们希望 tag 域 包含多个标签。我们可以以数组的形式索引标签:
{ "tag": [ "search", "nosql" ]}
对于数组,没有特殊的映射需求。任何域都可以包含0、1或者多个值,就像全文域分析得到多个词条。
这暗示 数组中所有的值必须是相同数据类型的 。你不能将日期和字符串混在一起。如果你通过索引数组来创建新的域,Elasticsearch 会用数组中第一个值的数据类型作为这个域的 类型 。
_source域,包含与你索引的一模一样的 JSON 文档。
但是,数组是以多值域 索引的—可以搜索,但是无序的。 在搜索的时候,你不能指定 “第一个” 或者 “最后一个”。 更确切的说,把数组想象成 装在袋子里的值 。
空域
当然,数组可以为空。 这相当于存在零值。 事实上,在 Lucene 中是不能存储 null 值的,所以我们认为存在 null 值的域为空域。
下面三种域被认为是空的,它们将不会被索引:
"null_value": null,
"empty_array": [],
"array_with_null_value": [ null ]
多层级对象
我们讨论的最后一个 JSON 原生数据类是 对象 -- 在其他语言中称为哈希,哈希 map,字典或者关联数组。
内部对象 经常用于 嵌入一个实体或对象到其它对象中。例如,与其在 tweet 文档中包含 user_name 和 user_id 域,我们也可以这样写:
{
"tweet": "Elasticsearch is very flexible",
"user": {
"id": "@johnsmith",
"gender": "male",
"age": 26,
"name": {
"full": "John Smith",
"first": "John",
"last": "Smith"
}
}
}
内部对象的映射
Elasticsearch 会动态 监测新的对象域并映射它们为 对象 ,在 properties 属性下列出内部域:
{
"gb": {
"tweet": { <1>
"properties": {
"tweet": { "type": "string" },
"user": { <2>
"type": "object",
"properties": {
"id": { "type": "string" },
"gender": { "type": "string" },
"age": { "type": "long" },
"name": { <3>
"type": "object",
"properties": {
"full": { "type": "string" },
"first": { "type": "string" },
"last": { "type": "string" }
}
}
}
}
}
}
}
}
内部对象
user 和 name 域的映射结构与 tweet 类型的相同。事实上, type 映射只是一种特殊的 对象 映射,我们称之为 根对象 。除了它有一些文档元数据的特殊顶级域,例如 _source 和 _all 域,它和其他对象一样。
内部对象是如何索引的
Lucene 不理解内部对象。 Lucene 文档是由一组键值对列表组成的。为了能让 Elasticsearch 有效地索引内部类,它把我们的文档转化成这样:
{
"tweet": [elasticsearch, flexible, very],
"user.id": [@johnsmith],
"user.gender": [male],
"user.age": [26],
"user.name.full": [john, smith],
"user.name.first": [john],
"user.name.last": [smith]
}
内部域 可以通过名称引用(例如, first )。为了区分同名的两个域,我们可以使用全 路径 (例如, user.name.first ) 或 type 名加路径( tweet.user.name.first )。
user和user.name域。Lucene 索引只有标量和简单值,没有复杂数据结构。
内部对象数组
最后,考虑包含 内部对象的数组是如何被索引的。 假设我们有个 followers 数组:
{
"followers": [
{ "age": 35, "name": "Mary White"},
{ "age": 26, "name": "Alex Jones"},
{ "age": 19, "name": "Lisa Smith"}
]
}
这个文档会像我们之前描述的那样被扁平化处理,结果如下所示:
{
"followers.age": [19, 26, 35],
"followers.name": [alex, jones, lisa, smith, mary, white]
}
{age: 35} 和 {name: Mary White} 之间的相关性已经丢失了,因为每个多值域只是一包无序的值,而不是有序数组。这足以让我们问,“有一个26岁的追随者?”
但是我们不能得到一个准确的答案:“是否有一个26岁 名字叫 Alex Jones 的追随者?”
相关内部对象被称为 nested 对象,可以回答上面的查询,我们稍后会在嵌套对象中介绍它。