深入搜索
近似匹配
使用 TF/IDF 的标准全文检索将文档或者文档中的字段作一大袋的词语处理。 match 查询可以告知我们这大袋子中是否包含查询的词条,但却无法告知词语之间的关系。
思考下面这几个句子的不同:
- Sue ate the alligator.
- The alligator ate Sue.
- Sue never goes anywhere without her alligator-skin purse.
用 match 搜索 sue alligator 上面的三个文档都会得到匹配,但它却不能确定这两个词是否只来自于一种语境,甚至都不能确定是否来自于同一个段落。
理解分词之间的关系是一个复杂的难题,我们也无法通过换一种查询方式去解决。但我们至少可以通过出现在彼此附近或者仅仅是彼此相邻的分词来判断一些似乎相关的分词。
每个文档可能都比我们上面这个例子要长: Sue 和 alligator 这两个词可能会分散在其他的段落文字中,我们可能会希望得到尽可能包含这两个词的文档,但我们也同样需要这些文档与分词有很高的相关度。
这就是短语匹配或者近似匹配的所属领域。
在这一章节,我们还是使用在
match查询中使用过的文档作为例子。
短语匹配
就像 match 查询对于标准全文检索是一种最常用的查询一样,当你想找到彼此邻近搜索词的查询方法时,就会想到 match_phrase 查询 。
GET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": "quick brown fox"
}
}
}
类似 match 查询, match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索,但只保留那些包含 全部 搜索词项,且 位置 与搜索词项相同的文档。 比如对于 quick fox 的短语搜索可能不会匹配到任何文档,因为没有文档包含的 quick 词之后紧跟着 fox 。
match_phrase查询同样可写成一种类型为phrase的match查询:
"match": {
"title": {
"query": "quick brown fox",
"type": "phrase"
}
}
词项的位置
当一个字符串被分词后,这个分析器不但会 返回一个词项列表,而且还会返回各词项在原始字符串中的 位置 或者顺序关系:
GET /_analyze?analyzer=standard
Quick brown fox
返回信息如下:
{
"tokens": [
{
"token": "quick",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 1 <1>
},
{
"token": "brown",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2 <2>
},
{
"token": "fox",
"start_offset": 12,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 3 <3>
}
]
}

position代表各词项在原始字符串中的位置。
位置信息可以被存储在倒排索引中,因此 match_phrase 查询这类对词语位置敏感的查询, 就可以利用位置信息去匹配包含所有查询词项,且各词项顺序也与我们搜索指定一致的文档,中间不夹杂其他词项。
什么是短语
一个被认定为和短语 quick brown fox 匹配的文档,必须满足以下这些要求:
quick、brown和fox需要全部出现在域中。brown的位置应该比quick的位置大1。fox的位置应该比quick的位置大2。
如果以上任何一个选项不成立,则该文档不能认定为匹配。
match_phrase查询是利用一种低级别的span查询族(query family)去做词语位置敏感的匹配。 Span 查询是一种词项级别的查询,所以它们没有分词阶段;它们只对指定的词项进行精确搜索。值得庆幸的是,
match_phrase查询已经足够优秀,大多数人是不会直接使用span查询。 然而,在一些专业领域,例如专利检索,还是会采用这种低级别查询去执行非常具体而又精心构造的位置搜索。
混合起来
精确短语匹配 或许是过于严格了。也许我们想要包含 “quick brown fox” 的文档也能够匹配 “quick fox,” , 尽管情形不完全相同。
我们能够通过使用 slop 参数将灵活度引入短语匹配中:
GET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": {
"query": "quick fox",
"slop": 1
}
}
}
}
slop 参数告诉 match_phrase 查询词条相隔多远时仍然能将文档视为匹配 。 相隔多远的意思是为了让查询和文档匹配你需要移动词条多少次?
我们以一个简单的例子开始吧。 为了让查询 quick fox 能匹配一个包含 quick brown fox 的文档, 我们需要 slop 的值为 1:
Pos 1 Pos 2 Pos 3
-----------------------------------------------
Doc: quick brown fox
-----------------------------------------------
Query: quick fox
Slop 1: quick ↳ fox
尽管在使用了 slop 短语匹配中所有的单词都需要出现, 但是这些单词也不必为了匹配而按相同的序列排列。 有了足够大的 slop 值, 单词就能按照任意顺序排列了。
为了使查询 fox quick 匹配我们的文档, 我们需要 slop 的值为 3:
Pos 1 Pos 2 Pos 3
-----------------------------------------------
Doc: quick brown fox
-----------------------------------------------
Query: fox quick
Slop 1: fox|quick ↵ <1>
Slop 2: quick ↳ fox
Slop 3: quick ↳ fox
fox和quick在这步中占据同样的位置。 因此将fox quick转换顺序成quick fox需要两步, 或者值为2的slop。
多值字段
对多值字段使用短语匹配时会发生奇怪的事。 想象一下你索引这个文档:
PUT /my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
然后运行一个对 Abraham Lincoln 的短语查询:
GET /my_index/groups/_search
{
"query": {
"match_phrase": {
"names": "Abraham Lincoln"
}
}
}
令人惊讶的是, 即使 Abraham 和 Lincoln 在 names 数组里属于两个不同的人名, 我们的文档也匹配了查询。 这一切的原因在Elasticsearch数组的索引方式。
在分析 John Abraham 的时候, 产生了如下信息:
- Position 1:
john - Position 2:
abraham
然后在分析 Lincoln Smith 的时候, 产生了:
- Position 3:
lincoln - Position 4:
smith
换句话说, Elasticsearch对以上数组分析生成了与分析单个字符串 John Abraham Lincoln Smith 一样几乎完全相同的语汇单元。 我们的查询示例寻找相邻的 lincoln 和 abraham , 而且这两个词条确实存在,并且它们俩正好相邻, 所以这个查询匹配了。
幸运的是, 在这样的情况下有一种叫做 position_increment_gap 的简单的解决方案, 它在字段映射中配置 。
DELETE /my_index/groups/ <1>
PUT /my_index/_mapping/groups <2>
{
"properties": {
"names": {
"type": "string",
"position_increment_gap": 100
}
}
}
groups以及这个类型内的所有文档。
groups。
position_increment_gap 设置告诉 Elasticsearch 应该为数组中每个新元素增加当前词条 position 的指定值。 所以现在当我们再索引 names 数组时,会产生如下的结果:
- Position 1:
john - Position 2:
abraham - Position 103:
lincoln - Position 104:
smith
现在我们的短语查询可能无法匹配该文档因为 abr
aham 和 lincoln 之间的距离为 100 。 为了匹配这个文档你必须添加值为 100 的 slop 。
越近越好
鉴于一个短语查询仅仅排除了不包含确切查询短语的文档, 而 邻近查询 — 一个 slop 大于 0— 的短语查询将查询词条的邻近度考虑到最终相关度 _score 中。 通过设置一个像 50 或者 100 这样的高 slop 值, 你能够排除单词距离太远的文档, 但是也给予了那些单词临近的的文档更高的分数。
下列对 quick dog 的邻近查询匹配了同时包含 quick 和 dog 的文档, 但是也给了与 quick 和 dog 更加临近的文档更高的分数 :
POST /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": {
"query": "quick dog",
"slop": 50 <1>
}
}
}
}
slop值。
{
"hits": [
{
"_id": "3",
"_score": 0.75, <1>
"_source": {
"title": "The quick brown fox jumps over the quick dog"
}
},
{
"_id": "2",
"_score": 0.28347334, <2>
"_source": {
"title": "The quick brown fox jumps over the lazy dog"
}
}
]
}
quick和dog很接近
quick和dog分开较远
使用邻近度提高相关度
虽然邻近查询很有用, 但是所有词条都出现在文档的要求过于严格了。 我们讨论 全文搜索 一章的 控制精度 也是同样的问题: 如果七个词条中有六个匹配, 那么这个文档对用户而言就已经足够相关了, 但是 match_phrase 查询可能会将它排除在外。
相比将使用邻近匹配作为绝对要求, 我们可以将它作为 信号— 使用, 作为许多潜在查询中的一个, 会对每个文档的最终分值做出贡献 (参考 多数字段)。
实际上我们想将多个查询的分数累计起来意味着我们应该用 bool 查询将它们合并。
我们可以将一个简单的 match 查询作为一个 must 子句。 这个查询将决定哪些文档需要被包含到结果集中。 我们可以用 minimum_should_match 参数去除长尾。 然后我们可以以 should 子句的形式添加更多特定查询。 每一个匹配成功的都会增加匹配文档的相关度。
GET /my_index/my_type/_search
{
"query": {
"bool": {
"must": {
"match": { <1>
"title": {
"query": "quick brown fox",
"minimum_should_match": "30%"
}
}
},
"should": {
"match_phrase": { <2>
"title": {
"query": "quick brown fox",
"slop": 50
}
}
}
}
}
}
must子句从结果集中包含或者排除文档。
should子句增加了匹配到文档的相关度评分。
我们当然可以在 should 子句里面添加其它的查询, 其中每一个查询只针对某一特定方面的相关度。
性能优化
短语查询和邻近查询都比简单的 query 查询代价更高 。 一个 match 查询仅仅是看词条是否存在于倒排索引中,而一个 match_phrase 查询是必须计算并比较多个可能重复词项的位置。
Lucene nightly benchmarks 表明一个简单的 term 查询比一个短语查询大约快 10 倍,比邻近查询(有 slop 的短语 查询)大约快 20 倍。当然,这个代价指的是在搜索时而不是索引时。
term查询有多快。标准全文数据的短语查询通常在几毫秒内完成,因此实际上都是完全可用,即使是在一个繁忙的集群上。在某些特定病理案例下,短语查询可能成本太高了,但比较少见。一个典型例子就是DNA序列,在序列里很多同样的词项在很多位置重复出现。在这里使用高
slop值会到导致位置计算大量增加。
那么我们应该如何限制短语查询和邻近近查询的性能消耗呢?一种有用的方法是减少需要通过短语查询检查的文档总数。
结果集重新评分
在先前的章节中 ,我们讨论了而使用邻近查询来调整相关度,而不是使用它将文档从结果列表中添加或者排除。 一个查询可能会匹配成千上万的结果,但我们的用户很可能只对结果的前几页感兴趣。
一个简单的 match 查询已经通过排序把包含所有含有搜索词条的文档放在结果列表的前面了。事实上,我们只想对这些 顶部文档 重新排序,来给同时匹配了短语查询的文档一个额外的相关度升级。
search API 通过 重新评分 明确支持该功能。重新评分阶段支持一个代价更高的评分算法--比如 phrase 查询--只是为了从每个分片中获得前 K 个结果。 然后会根据它们的最新评分 重新排序。
该请求如下所示:
GET /my_index/my_type/_search
{
"query": {
"match": { <1>
"title": {
"query": "quick brown fox",
"minimum_should_match": "30%"
}
}
},
"rescore": {
"window_size": 50, <2>
"query": { <3>
"rescore_query": {
"match_phrase": {
"title": {
"query": "quick brown fox",
"slop": 50
}
}
}
}
}
}
window_size是每一分片进行重新评分的顶部文档数量。
寻找相关词
短语查询和邻近查询都很好用,但仍有一个缺点。它们过于严格了:为了匹配短语查询,所有词项都必须存在,即使使用了 slop 。
用 slop 得到的单词顺序的灵活性也需要付出代价,因为失去了单词对之间的联系。即使可以识别 sue 、 alligator 和 ate 相邻出现的文档,但无法分辨是 Sue ate 还是 alligator ate 。
当单词相互结合使用的时候,表达的含义比单独使用更丰富。两个子句 I’m not happy I’m working 和 I’m happy I’m not working 包含相同 的单词,也拥有相同的邻近度,但含义截然不同。
如果索引单词对而不是索引独立的单词,就能对这些单词的上下文尽可能多的保留。
对句子 Sue ate the alligator ,不仅要将每一个单词(或者 unigram )作为词项索引
["sue", "ate", "the", "alligator"]
也要将每个单词 以及它的邻近词 作为单个词项索引:
["sue ate", "ate the", "the alligator"]
这些单词对(或者 bigrams )被称为 shingles 。
["sue ate the", "ate the alligator"]Trigrams 提供了更高的精度,但是也大大增加了索引中唯一词项的数量。在大多数情况下,Bigrams 就够了。
当然,只有当用户输入的查询内容和在原始文档中顺序相同时,shingles 才是有用的;对 sue alligator的查询可能会匹配到单个单词,但是不会匹配任何 shingles 。
幸运的是,用户倾向于使用和搜索数据相似的构造来表达搜索意图。但这一点很重要:只是索引 bigrams 是不够的;我们仍然需要 unigrams ,但可以将匹配 bigrams 作为增加相关度评分的信号。
生成 Shingles
Shingles 需要在索引时作为分析过程的一部分被创建。 我们可以将 unigrams 和 bigrams 都索引到单个字段中, 但将它们分开保存在能被独立查询的字段会更清晰。unigrams 字段将构成我们搜索的基础部分,而 bigrams 字段用来提高相关度。
首先,我们需要在创建分析器时使用 shingle 语汇单元过滤器:
DELETE /my_index
PUT /my_index
{
"settings": {
"number_of_shards": 1, <1>
"analysis": {
"filter": {
"my_shingle_filter": {
"type": "shingle",
"min_shingle_size": 2, <2>
"max_shingle_size": 2, <3>
"output_unigrams": false <4>
}
},
"analyzer": {
"my_shingle_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"my_shingle_filter" <5>
]
}
}
}
}
}
2,所以实际上不需要设置。

shingle语汇单元过滤器默认输出 unigrams ,但是我们想让 unigrams 和 bigrams 分开。

my_shingle_analyzer使用我们常规的my_shingles_filter语汇单元过滤器。
首先,用 analyze API 测试下分析器:
GET /my_index/_analyze?analyzer=my_shingle_analyzer
Sue ate the alligator
果然, 我们得到了 3 个词项:
sue ateate thethe alligator
现在我们可以继续创建一个使用新的分析器的字段。
多字段
我们曾谈到将 unigrams 和 bigrams 分开索引更清晰,所以 title 字段将创建成一个多字段(参考 字符串排序与多字段 ):
PUT /my_index/_mapping/my_type
{
"my_type": {
"properties": {
"title": {
"type": "string",
"fields": {
"shingles": {
"type": "string",
"analyzer": "my_shingle_analyzer"
}
}
}
}
}
}
通过这个映射, JSON 文档中的 title 字段将会被以 unigrams (title)和 bigrams (title.shingles)被索引,这意味着可以独立地查询这些字段。
最后,我们可以索引以下示例文档:
POST /my_index/my_type/_bulk
{ "index": { "_id": 1 }}
{ "title": "Sue ate the alligator" }
{ "index": { "_id": 2 }}
{ "title": "The alligator ate Sue" }
{ "index": { "_id": 3 }}
{ "title": "Sue never goes anywhere without her alligator skin purse" }
搜索 Shingles
为了理解添加 shingles 字段的好处 ,让我们首先来看 The hungry alligator ate Sue 进行简单 match查询的结果:
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": "the hungry alligator ate sue"
}
}
}
这个查询返回了所有的三个文档, 但是注意文档 1 和 2 有相同的相关度评分因为他们包含了相同的单词:
{
"hits": [
{
"_id": "1",
"_score": 0.44273707, <1>
"_source": {
"title": "Sue ate the alligator"
}
},
{
"_id": "2",
"_score": 0.44273707, <2>
"_source": {
"title": "The alligator ate Sue"
}
},
{
"_id": "3", <3>
"_score": 0.046571054,
"_source": {
"title": "Sue never goes anywhere without her alligator skin purse"
}
}
]
}
the、alligator和ate,所以获得相同的评分。
minimum_should_match参数排除文档 3 ,参考 控制精度 。
现在在查询里添加 shingles 字段。不要忘了在 shingles 字段上的匹配是充当一 种信号--为了提高相关度评分--所以我们仍然需要将基本 title 字段包含到查询中:
GET /my_index/my_type/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "the hungry alligator ate sue"
}
},
"should": {
"match": {
"title.shingles": "the hungry alligator ate sue"
}
}
}
}
}
仍然匹配到了所有的 3 个文档, 但是文档 2 现在排到了第一名因为它匹配了 shingled 词项 ate sue.
{
"hits": [
{
"_id": "2",
"_score": 0.4883322,
"_source": {
"title": "The alligator ate Sue"
}
},
{
"_id": "1",
"_score": 0.13422975,
"_source": {
"title": "Sue ate the alligator"
}
},
{
"_id": "3",
"_score": 0.014119488,
"_source": {
"title": "Sue never goes anywhere without her alligator skin purse"
}
}
]
}
即使查询包含的单词 hungry 没有在任何文档中出现,我们仍然使用单词邻近度返回了最相关的文档。
Performance性能
shingles 不仅比短语查询更灵活, 而且性能也更好。 shingles 查询跟一个简单的 match 查询一样高效,而不用每次搜索花费短语查询的代价。只是在索引期间因为更多词项需要被索引会付出一些小的代价, 这也意味着有 shingles 的字段会占用更多的磁盘空间。 然而,大多数应用写入一次而读取多次,所以在索引期间优化我们的查询速度是有意义的。
这是一个在 Elasticsearch 里会经常碰到的话题:不需要任何前期进行过多的设置,就能够在搜索的时候有很好的效果。 一旦更清晰的理解了自己的需求,就能在索引时通过正确的为你的数据建模获得更好结果和性能。
部分匹配
敏锐的读者会注意,目前为止本书介绍的所有查询都是针对整个词的操作。为了能匹配,只能查找倒排索引中存在的词,最小的单元为单个词。
但如果想匹配部分而不是全部的词该怎么办? 部分匹配 允许用户指定查找词的一部分并找出所有包含这部分片段的词。
与想象的不太一样,对词进行部分匹配的需求在全文搜索引擎领域并不常见,但是如果读者有 SQL 方面的背景,可能会在某个时候实现一个 低效的全文搜索 用下面的 SQL 语句对全文进行搜索:
WHERE text LIKE "%quick%"
AND text LIKE "%brown%"
AND text LIKE "%fox%"
*fox*会与 “fox” 和 “foxes” 匹配。
当然, Elasticsearch 提供分析过程,倒排索引让我们不需要使用这种粗笨的技术。为了能应对同时匹配 “fox” 和 “foxes” 的情况,只需简单的将它们的词干作为索引形式,没有必要做部分匹配。
也就是说,在某些情况下部分匹配会比较有用, 常见的应用如下:
- 匹配邮编、产品序列号或其他
not_analyzed未分析值,这些值可以是以某个特定前缀开始,也可以是与某种模式匹配的,甚至可以是与某个正则式相匹配的。 - 输入即搜索(search-as-you-type) ——在用户键入搜索词过程的同时就呈现最可能的结果。
- 匹配如德语或荷兰语这样有长组合词的语言,如: Weltgesundheitsorganisation (世界卫生组织,英文 World Health Organization)。
本章始于检验 not_analyzed 精确值字段的前缀匹配。
邮编与结构化数据
我们会使用美国目前使用的邮编形式(United Kingdom postcodes 标准)来说明如何用部分匹配查询结构化数据。 这种邮编形式有很好的结构定义。例如,邮编 W1V 3DG 可以分解成如下形式:
W1V:这是邮编的外部,它定义了邮件的区域和行政区:W代表区域( 1 或 2 个字母)1V代表行政区( 1 或 2 个数字,可能跟着一个字符)
3DG:内部定义了街道或建筑:3代表街区区块( 1 个数字)DG代表单元( 2 个字母)
假设将邮编作为 not_analyzed 的精确值字段索引,所以可以为其创建索引,如下:
PUT /my_index
{
"mappings": {
"address": {
"properties": {
"postcode": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
然后索引一些邮编:
PUT /my_index/address/1
{ "postcode": "W1V 3DG" }
PUT /my_index/address/2
{ "postcode": "W2F 8HW" }
PUT /my_index/address/3
{ "postcode": "W1F 7HW" }
PUT /my_index/address/4
{ "postcode": "WC1N 1LZ" }
PUT /my_index/address/5
{ "postcode": "SW5 0BE" }
现在这些数据已可查询。
prefix 前缀查询
为了找到所有以 W1 开始的邮编,可以使用简单的 prefix 查询:
GET /my_index/address/_search
{
"query": {
"prefix": {
"postcode": "W1"
}
}
}
prefix 查询是一个词级别的底层的查询,它不会在搜索之前分析查询字符串,它假定传入前缀就正是要查找的前缀。
prefix查询不做相关度评分计算,它只是将所有匹配的文档返回,并为每条结果赋予评分值1。它的行为更像是过滤器而不是查询。prefix查询和prefix过滤器这两者实际的区别就是过滤器是可以被缓存的,而查询不行。
之前已经提过:“只能在倒排索引中找到存在的词”,但我们并没有对这些邮编的索引进行特殊处理,每个邮编还是以它们精确值的方式存在于每个文档的索引中,那么 prefix 查询是如何工作的呢?
回想倒排索引包含了一个有序的唯一词列表(本例是邮编)。 对于每个词,倒排索引都会将包含词的文档 ID 列入 倒排表(postings list) 。与示例对应的倒排索引是:
Term: Doc IDs:
-------------------------
"SW5 0BE" | 5
"W1F 7HW" | 3
"W1V 3DG" | 1
"W2F 8HW" | 2
"WC1N 1LZ" | 4
-------------------------
为了支持前缀匹配,查询会做以下事情:
- 扫描词列表并查找到第一个以
W1开始的词。 - 搜集关联的文档 ID 。
- 移动到下一个词。
- 如果这个词也是以
W1开头,查询跳回到第二步再重复执行,直到下一个词不以W1为止。
这对于小的例子当然可以正常工作,但是如果倒排索引中有数以百万的邮编都是以 W1 开头时,前缀查询则需要访问每个词然后计算结果!
前缀越短所需访问的词越多。如果我们要以 W 作为前缀而不是 W1 ,那么就可能需要做千万次的匹配。

prefix查询或过滤对于一些特定的匹配是有效的,但使用方式还是应当注意。 当字段中词的集合很小时,可以放心使用,但是它的伸缩性并不好,会对我们的集群带来很多压力。可以使用较长的前缀来限制这种影响,减少需要访问的量。
本章后面会介绍另一个索引时的解决方案,这个方案能使前缀匹配更高效,不过在此之前,需要先看看两个相关的查询: wildcard 和 regexp (模糊和正则)。
通配符与正则表达式查询
与 prefix 前缀查询的特性类似, wildcard 通配符查询也是一种底层基于词的查询, 与前缀查询不同的是它允许指定匹配的正则式。它使用标准的 shell 通配符查询: ? 匹配任意字符, * 匹配 0 或多个字符。
这个查询会匹配包含 W1F 7HW 和 W2F 8HW 的文档:
GET /my_index/address/_search
{
"query": {
"wildcard": {
"postcode": "W?F*HW" <1>
}
}
}
?匹配1和2,*与空格及7和8匹配。
设想如果现在只想匹配 W 区域的所有邮编,前缀匹配也会包括以 WC 开头的所有邮编,与通配符匹配碰到的问题类似,如果想匹配只以 W 开始并跟随一个数字的所有邮编, regexp 正则式查询允许写出这样更复杂的模式:
GET /my_index/address/_search
{
"query": {
"regexp": {
"postcode": "W[0-9].+" <1>
}
}
}
W开头,紧跟 0 至 9 之间的任何一个数字,然后接一或多个其他字符。
wildcard 和 regexp 查询的工作方式与 prefix 查询完全一样,它们也需要扫描倒排索引中的词列表才能找到所有匹配的词,然后依次获取每个词相关的文档 ID ,与 prefix 查询的唯一不同是:它们能支持更为复杂的匹配模式。
这也意味着需要同样注意前缀查询存在性能问题,对有很多唯一词的字段执行这些查询可能会消耗非常多的资源,所以要避免使用左通配这样的模式匹配(如: *foo 或 .*foo 这样的正则式)。
数据在索引时的预处理有助于提高前缀匹配的效率,而通配符和正则表达式查询只能在查询时完成,尽管这些查询有其应用场景,但使用仍需谨慎。
prefix、wildcard和regexp查询是基于词操作的,如果用它们来查询analyzed字段,它们会检查字段里面的每个词,而不是将字段作为整体来处理。
比方说包含 “Quick brown fox” (快速的棕色狐狸)的 title 字段会生成词: quick 、 brown 和 fox 。
会匹配以下这个查询:
{ "regexp": { "title": "br.*" }}
但是不会匹配以下两个查询:
{ "regexp": { "title": "Qu.*" }} <1>
{ "regexp": { "title": "quick br*" }} <2>
quick而不是Quick。
quick和brown在词表中是分开的。
查询时输入即搜索
把邮编的事情先放一边,让我们先看看前缀查询是如何在全文查询中起作用的。 用户已经渐渐习惯在输完查询内容之前,就能为他们展现搜索结果,这就是所谓的 即时搜索(instant search) 或 输入即搜索(search-as-you-type) 。不仅用户能在更短的时间内得到搜索结果,我们也能引导用户搜索索引中真实存在的结果。
例如,如果用户输入 johnnie walker bl ,我们希望在它们完成输入搜索条件前就能得到:Johnnie Walker Black Label 和 Johnnie Walker Blue Label 。
生活总是这样,就像猫的花色远不只一种!我们希望能找到一种最简单的实现方式。并不需要对数据做任何准备,在查询时就能对任意的全文字段实现 输入即搜索(search-as-you-type) 的查询。
在 短语匹配 中,我们引入了 match_phrase 短语匹配查询,它匹配相对顺序一致的所有指定词语,对于查询时的输入即搜索,可以使用 match_phrase 的一种特殊形式, match_phrase_prefix 查询:
{
"match_phrase_prefix" : {
"brand" : "johnnie walker bl"
}
}
这种查询的行为与 match_phrase 查询一致,不同的是它将查询字符串的最后一个词作为前缀使用,换句话说,可以将之前的例子看成如下这样:
johnnie- 跟着
walker - 跟着以
bl开始的词
如果通过 validate-query API 运行这个查询查询,explanation 的解释结果为:
"johnnie walker bl*"
与 match_phrase 一样,它也可以接受 slop 参数(参照 slop )让相对词序位置不那么严格:
{
"match_phrase_prefix" : {
"brand" : {
"query": "walker johnnie bl", <1>
"slop": 10
}
}
}
slop值使匹配时的词序有更大的灵活性。
但是只有查询字符串的最后一个词才能当作前缀使用。
在之前的 前缀查询 中,我们警告过使用前缀的风险,即 prefix 查询存在严重的资源消耗问题,短语查询的这种方式也同样如此。 前缀 a 可能会匹配成千上万的词,这不仅会消耗很多系统资源,而且结果的用处也不大。
可以通过设置 max_expansions 参数来限制前缀扩展的影响, 一个合理的值是可能是 50 :
{
"match_phrase_prefix" : {
"brand" : {
"query": "johnnie walker bl",
"max_expansions": 50
}
}
}
参数 max_expansions 控制着可以与前缀匹配的词的数量,它会先查找第一个与前缀 bl 匹配的词,然后依次查找搜集与之匹配的词(按字母顺序),直到没有更多可匹配的词或当数量超过 max_expansions 时结束。
不要忘记,当用户每多输入一个字符时,这个查询又会执行一遍,所以查询需要快,如果第一个结果集不是用户想要的,他们会继续输入直到能搜出满意的结果为止。
索引时优化
到目前为止,所有谈论过的解决方案都是在 查询时(query time) 实现的。 这样做并不需要特殊的映射或特殊的索引模式,只是简单使用已经索引的数据。
查询时的灵活性通常会以牺牲搜索性能为代价,有时候将这些消耗从查询过程中转移到别的地方是有意义的。在实时 web 应用中, 100 毫秒可能是一个难以忍受的巨大延迟。
可以通过在索引时处理数据提高搜索的灵活性以及提升系统性能。为此仍然需要付出应有的代价:增加的索引空间与变慢的索引能力,但这与每次查询都需要付出代价不同,索引时的代价只用付出一次。
用户会感谢我们。
Ngrams 在部分匹配的应用
之前提到:“只能在倒排索引中找到存在的词。” 尽管 prefix 、 wildcard 、 regexp 查询告诉我们这种说法并不完全正确,但单个词的查找 确实 要比在词列表中盲目挨个查找的效率要高得多。 在搜索之前准备好供部分匹配的数据可以提高搜索的性能。
在索引时准备数据意味着要选择合适的分析链,这里部分匹配使用的工具是 n-gram 。可以将 n-gram 看成一个在词语上 滑动窗口 , n 代表这个 “窗口” 的长度。如果我们要 n-gram quick 这个词 —— 它的结果取决于 n 的选择长度:
- 长度 1(unigram): [
q,u,i,c,k] - 长度 2(bigram): [
qu,ui,ic,ck] - 长度 3(trigram): [
qui,uic,ick] - 长度 4(four-gram): [
quic,uick] - 长度 5(five-gram): [
quick]
朴素的 n-gram 对 词语内部的匹配 非常有用,即在 Ngram 匹配复合词 介绍的那样。但对于输入即搜索(search-as-you-type)这种应用场景,我们会使用一种特殊的 n-gram 称为 边界 n-grams (edge n-grams)。所谓的边界 n-gram 是说它会固定词语开始的一边,以单词 quick 为例,它的边界 n-gram 的结果为:
qququiquicquick
可能会注意到这与用户在搜索时输入 “quick” 的字母次序是一致的,换句话说,这种方式正好满足即时搜索(instant search)!
索引时输入即搜索
设置索引时输入即搜索的第一步是需要定义好分析链, 我们已在 配置分析器 中讨论过,这里会对这些步骤再次说明。
准备索引
第一步需要配置一个自定义的 edge_ngram token 过滤器,称为 autocomplete_filter :
{
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
}
}
这个配置的意思是:对于这个 token 过滤器接收的任意词项,过滤器会为之生成一个最小固定值为 1 ,最大为 20 的 n-gram 。
然后会在一个自定义分析器 autocomplete 中使用上面这个 token 过滤器:
{
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter" <1>
]
}
}
}
这个分析器使用 standard 分词器将字符串拆分为独立的词,并且将它们都变成小写形式,然后为每个词生成一个边界 n-gram,这要感谢 autocomplete_filter 起的作用。
创建索引、实例化 token 过滤器和分析器的完整示例如下:
PUT /my_index
{
"settings": {
"number_of_shards": 1, <1>
"analysis": {
"filter": {
"autocomplete_filter": { <2>
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter" <3>
]
}
}
}
}
}
可以拿 analyze API 测试这个新的分析器确保它行为正确:
GET /my_index/_analyze?analyzer=autocomplete
quick brown
结果表明分析器能正确工作,并返回以下词:
qququiquicquickbbrbrobrowbrown
可以用 update-mapping API 将这个分析器应用到具体字段:
PUT /my_index/_mapping/my_type
{
"my_type": {
"properties": {
"name": {
"type": "string",
"analyzer": "autocomplete"
}
}
}
}
现在创建一些测试文档:
POST /my_index/my_type/_bulk
{ "index": { "_id": 1 }}
{ "name": "Brown foxes" }
{ "index": { "_id": 2 }}
{ "name": "Yellow furballs" }
查询字段
如果使用简单 match 查询测试查询 “brown fo” :
GET /my_index/my_type/_search
{
"query": {
"match": {
"name": "brown fo"
}
}
}
可以看到两个文档同时 都能 匹配,尽管 Yellow furballs 这个文档并不包含 brown 和 fo :
{
"hits": [
{
"_id": "1",
"_score": 1.5753809,
"_source": {
"name": "Brown foxes"
}
},
{
"_id": "2",
"_score": 0.012520773,
"_source": {
"name": "Yellow furballs"
}
}
]
}
如往常一样, validate-query API 总能提供一些线索:
GET /my_index/my_type/_validate/query?explain
{
"query": {
"match": {
"name": "brown fo"
}
}
}
explanation 表明查询会查找边界 n-grams 里的每个词:
name:b name:br name:bro name:brow name:brown name:f name:fo
name:f 条件可以满足第二个文档,因为 furballs 是以 f 、 fu 、 fur 形式索引的。回过头看这并不令人惊讶,相同的 autocomplete 分析器同时被应用于索引时和搜索时,这在大多数情况下是正确的,只有在少数场景下才需要改变这种行为。
我们需要保证倒排索引表中包含边界 n-grams 的每个词,但是我们只想匹配用户输入的完整词组( brown和 fo ), 可以通过在索引时使用 autocomplete 分析器,并在搜索时使用 standard 标准分析器来实现这种想法,只要改变查询使用的搜索分析器 analyzer 参数即可:
GET /my_index/my_type/_search
{
"query": {
"match": {
"name": {
"query": "brown fo",
"analyzer": "standard" <1>
}
}
}
}
name字段analyzer的设置。
换种方式,我们可以在映射中,为 name 字段分别指定 index_analyzer 和 search_analyzer 。因为我们只想改变 search_analyzer ,这里只要更新现有的映射而不用对数据重新创建索引:
PUT /my_index/my_type/_mapping
{
"my_type": {
"properties": {
"name": {
"type": "string",
"index_analyzer": "autocomplete",
"search_analyzer": "standard"
}
}
}
}
autocomplete分析器生成边界 n-grams 的每个词。
standard分析器只搜索用户输入的词。
如果再次请求 validate-query API ,当前的解释为:
name:brown name:fo
再次执行查询就能正确返回 Brown foxes 这个文档。
因为大多数工作是在索引时完成的,所有的查询只要查找 brown 和 fo 这两个词,这比使用 match_phrase_prefix 查找所有以 fo 开始的词的方式要高效许多。
补全提示(Completion Suggester)
使用边界 n-grams 进行输入即搜索(search-as-you-type)的查询设置简单、灵活且快速,但有时候它并不够快,特别是当试图立刻获得反馈时,延迟的问题就会凸显,很多时候不搜索才是最快的搜索方式。
Elasticsearch 里的 completion suggester 采用与上面完全不同的方式,需要为搜索条件生成一个所有可能完成的词列表,然后将它们置入一个 有限状态机(finite state transducer) 内,这是个经优化的图结构。为了搜索建议提示,Elasticsearch 从图的开始处顺着匹配路径一个字符一个字符地进行匹配,一旦它处于用户输入的末尾,Elasticsearch 就会查找所有可能结束的当前路径,然后生成一个建议列表。
本数据结构存于内存中,能使前缀查找非常快,比任何一种基于词的查询都要快很多,这对名字或品牌的自动补全非常适用,因为这些词通常是以普通顺序组织的:用 “Johnny Rotten” 而不是 “Rotten Johnny” 。
当词序不是那么容易被预见时,边界 n-grams 比完成建议者(Completion Suggester)更合适。即使说不是所有猫都是一个花色,那这只猫的花色也是相当特殊的。
边界 n-grams 与邮编
边界 n-gram 的方式可以用来查询结构化的数据, 比如 本章之前示例 中的邮编(postcode)。当然 postcode 字段需要 analyzed 而不是 not_analyzed ,不过可以用 keyword 分词器来处理它,就好像他们是 not_analyzed 的一样。
keyword分词器是一个非操作型分词器,这个分词器不做任何事情,它接收的任何字符串都会被原样发出,因此它可以用来处理not_analyzed的字段值,但这也需要其他的一些分析转换,如将字母转换成小写。
下面示例使用 keyword 分词器将邮编转换成 token 流,这样就能使用边界 n-gram token 过滤器:
{
"analysis": {
"filter": {
"postcode_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 8
}
},
"analyzer": {
"postcode_index": { <1>
"tokenizer": "keyword",
"filter": [ "postcode_filter" ]
},
"postcode_search": { <2>
"tokenizer": "keyword"
}
}
}
}
postcode_index分析器使用postcode_filter将邮编转换成边界 n-gram 形式。
postcode_search分析器可以将搜索词看成not_analyzed未分析的。
Ngrams 在复合词的应用
最后,来看看 n-gram 是如何应用于搜索复合词的语言中的。 德语的特点是它可以将许多小词组合成一个庞大的复合词以表达它准确或复杂的意义。例如:
Aussprachewörterbuch
发音字典(Pronunciation dictionary)
Militärgeschichte
战争史(Military history)
Weißkopfseeadler
秃鹰(White-headed sea eagle, or bald eagle)
Weltgesundheitsorganisation
世界卫生组织(World Health Organization)
Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz
法案考虑代理监管牛和牛肉的标记的职责(The law concerning the delegation of duties for the supervision of cattle marking and the labeling of beef)
有些人希望在搜索 “Wörterbuch”(字典)的时候,能在结果中看到 “Aussprachewörtebuch”(发音字典)。同样,搜索 “Adler”(鹰)的时候,能将 “Weißkopfseeadler”(秃鹰)包括在结果中。
处理这种语言的一种方式可以用 组合词 token 过滤器(compound word token filter) 将复合词拆分成各自部分,但这种方式的结果质量依赖于组合词字典的质量。
另一种方式就是将所有的词用 n-gram 进行处理,然后搜索任何匹配的片段——能匹配的片段越多,文档的相关度越大。
假设某个 n-gram 是一个词上的滑动窗口,那么任何长度的 n-gram 都可以遍历这个词。我们既希望选择足够长的值让拆分的词项具有意义,又不至于因为太长而生成过多的唯一词。一个长度为 3 的 trigram 可能是一个不错的开始:
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"trigrams_filter": {
"type": "ngram",
"min_gram": 3,
"max_gram": 3
}
},
"analyzer": {
"trigrams": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"trigrams_filter"
]
}
}
}
},
"mappings": {
"my_type": {
"properties": {
"text": {
"type": "string",
"analyzer": "trigrams"
}
}
}
}
}
text字段用trigrams分析器索引它的内容,这里 n-gram 的长度是 3 。
使用 analyze API 测试 trigram 分析器:
GET /my_index/_analyze?analyzer=trigrams
Weißkopfseeadler
返回以下词项:
wei, eiß, ißk, ßko, kop, opf, pfs, fse, see, eea,ead, adl, dle, ler
索引前述示例中的复合词来测试:
POST /my_index/my_type/_bulk
{ "index": { "_id": 1 }}
{ "text": "Aussprachewörterbuch" }
{ "index": { "_id": 2 }}
{ "text": "Militärgeschichte" }
{ "index": { "_id": 3 }}
{ "text": "Weißkopfseeadler" }
{ "index": { "_id": 4 }}
{ "text": "Weltgesundheitsorganisation" }
{ "index": { "_id": 5 }}
{ "text": "Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz" }
“Adler”(鹰)的搜索转化为查询三个词 adl 、 dle 和 ler :
GET /my_index/my_type/_search
{
"query": {
"match": {
"text": "Adler"
}
}
}
正好与 “Weißkopfsee-adler” 相匹配:
{
"hits": [
{
"_id": "3",
"_score": 3.3191128,
"_source": {
"text": "Weißkopfseeadler"
}
}
]
}
类似查询 “Gesundheit”(健康)可以与 “Welt-gesundheit-sorganisation” 匹配,同时也能与 “Militär-ges-chichte” 和 “Rindfleischetikettierungsüberwachungsaufgabenübertragungs-ges-etz” 匹配,因为它们同时都有 trigram 生成的 ges :
使用合适的 minimum_should_match 可以将这些奇怪的结果排除,只有当 trigram 最少匹配数满足要求时,文档才能被认为是匹配的:
GET /my_index/my_type/_search
{
"query": {
"match": {
"text": {
"query": "Gesundheit",
"minimum_should_match": "80%"
}
}
}
}
这有点像全文搜索中霰弹枪式的策略,可能会导致倒排索引内容变多,尽管如此,在索引具有很多复合词的语言,或词之间没有空格的语言(如:泰语)时,它仍不失为一种通用且有效的方法。
这种技术可以用来提升 召回率 ——搜索结果中相关的文档数。它通常会与其他技术一起使用,例如 shingles(参见 shingles 瓦片词 ),以提高精度和每个文档的相关度评分。
控制相关度
处理结构化数据(比如:时间、数字、字符串、枚举)的数据库, 只需检查文档(或关系数据库里的行)是否与查询匹配。
布尔的是/非匹配是全文搜索的基础,但不止如此,我们还要知道每个文档与查询的相关度,在全文搜索引擎中不仅需要找到匹配的文档,还需根据它们相关度的高低进行排序。
全文相关的公式或 相似算法(similarity algorithms) 会将多个因素合并起来,为每个文档生成一个相关度评分 _score 。本章中,我们会验证各种可变部分,然后讨论如何来控制它们。
当然,相关度不只与全文查询有关,也需要将结构化的数据考虑其中。可能我们正在找一个度假屋,需要一些的详细特征(空调、海景、免费 WiFi ),匹配的特征越多相关度越高。可能我们还希望有一些其他的考虑因素,如回头率、价格、受欢迎度或距离,当然也同时考虑全文查询的相关度。
所有的这些都可以通过 Elasticsearch 强大的评分基础来实现。
本章会先从理论上介绍 Lucene 是如何计算相关度的,然后通过实际例子说明如何控制相关度的计算过程。
相关度评分背后的理论
Lucene(或 Elasticsearch)使用 布尔模型(Boolean model) 查找匹配文档, 并用一个名为 实用评分函数(practical scoring function) 的公式来计算相关度。这个公式借鉴了 词频/逆向文档频率(term frequency/inverse document frequency) 和 向量空间模型(vector space model),同时也加入了一些现代的新特性,如协调因子(coordination factor),字段长度归一化(field length normalization),以及词或查询语句权重提升。
不要紧张!这些概念并没有像它们字面看起来那么复杂,尽管本小节提到了算法、公式和数学模型,但内容还是让人容易理解的,与理解算法本身相比,了解这些因素如何影响结果更为重要。
布尔模型
布尔模型(Boolean Model) 只是在查询中使用 AND 、 OR 和 NOT (与、或和非)这样的条件来查找匹配的文档,以下查询:
full AND text AND search AND (elasticsearch OR lucene)
会将所有包括词 full 、 text 和 search ,以及 elasticsearch 或 lucene 的文档作为结果集。
这个过程简单且快速,它将所有可能不匹配的文档排除在外。
词频/逆向文档频率(TF/IDF)
当匹配到一组文档后,需要根据相关度排序这些文档,不是所有的文档都包含所有词,有些词比其他的词更重要。一个文档的相关度评分部分取决于每个查询词在文档中的 权重 。
词的权重由三个因素决定,在 什么是相关 中已经有所介绍,有兴趣可以了解下面的公式,但并不要求记住。
词频
词在文档中出现的频度是多少? 频度越高,权重 越高 。 5 次提到同一词的字段比只提到 1 次的更相关。词频的计算方式如下:
tf(t in d) = √frequency
t在文档d的词频(tf)是该词在文档中出现次数的平方根。
如果不在意词在某个字段中出现的频次,而只在意是否出现过,则可以在字段映射中禁用词频统计:
PUT /my_index
{
"mappings": {
"doc": {
"properties": {
"text": {
"type": "string",
"index_options": "docs"
}
}
}
}
}
index_options设置为docs可以禁用词频统计及词频位置,这个映射的字段不会计算词的出现次数,对于短语或近似查询也不可用。要求精确查询的not_analyzed字符串字段会默认使用该设置。
逆向文档频率
词在集合所有文档里出现的频率是多少?频次越高,权重 越低 。 常用词如 and 或 the 对相关度贡献很少,因为它们在多数文档中都会出现,一些不常见词如 elastic 或 hippopotamus 可以帮助我们快速缩小范围找到感兴趣的文档。逆向文档频率的计算公式如下:
idf(t) = 1 + log ( numDocs / (docFreq + 1))
t的逆向文档频率(idf)是:索引中文档数量除以所有包含该词的文档数,然后求其对数。
字段长度归一值
字段的长度是多少? 字段越短,字段的权重 越高 。如果词出现在类似标题 title 这样的字段,要比它出现在内容 body 这样的字段中的相关度更高。字段长度的归一值公式如下:
norm(d) = 1 / √numTerms
norm)是字段中词数平方根的倒数。
字段长度的归一值对全文搜索非常重要, 许多其他字段不需要有归一值。无论文档是否包括这个字段,索引中每个文档的每个 string 字段都大约占用 1 个 byte 的空间。对于 not_analyzed 字符串字段的归一值默认是禁用的,而对于 analyzed 字段也可以通过修改字段映射禁用归一值:
PUT /my_index
{
"mappings": {
"doc": {
"properties": {
"text": {
"type": "string",
"norms": { "enabled": false }
}
}
}
}
}
对于有些应用场景如日志,归一值不是很有用,要关心的只是字段是否包含特殊的错误码或者特定的浏览器唯一标识符。字段的长度对结果没有影响,禁用归一值可以节省大量内存空间。
结合使用
以下三个因素——词频(term frequency)、逆向文档频率(inverse document frequency)和字段长度归一值(field-length norm)——是在索引时计算并存储的。 最后将它们结合在一起计算单个词在特定文档中的 权重 。
当用 explain 查看一个简单的 term 查询时(参见 explain ),可以发现与计算相关度评分的因子就是前面章节介绍的这些:
PUT /my_index/doc/1
{ "text" : "quick brown fox" }
GET /my_index/doc/_search?explain
{
"query": {
"term": {
"text": "fox"
}
}
}
以上请求(简化)的 explanation 解释如下:
weight(text:fox in 0) [PerFieldSimilarity]: 0.15342641 <1>
result of:
fieldWeight in 0 0.15342641
product of:
tf(freq=1.0), with freq of 1: 1.0 <2>
idf(docFreq=1, maxDocs=1): 0.30685282 <3>
fieldNorm(doc=0): 0.5 <4>
fox在文档的内部 Lucene doc ID 为0,字段是text里的最终评分。
fox在该文档text字段中只出现了一次。
fox在所有文档text字段索引的逆向文档频率。
当然,查询通常不止一个词,所以需要一种合并多词权重的方式——向量空间模型(vector space model)。
向量空间模型
向量空间模型(vector space model) 提供一种比较多词查询的方式,单个评分代表文档与查询的匹配程度,为了做到这点,这个模型将文档和查询都以 向量(vectors) 的形式表示:
向量实际上就是包含多个数的一维数组,例如:
[1,2,5,22,3,8]
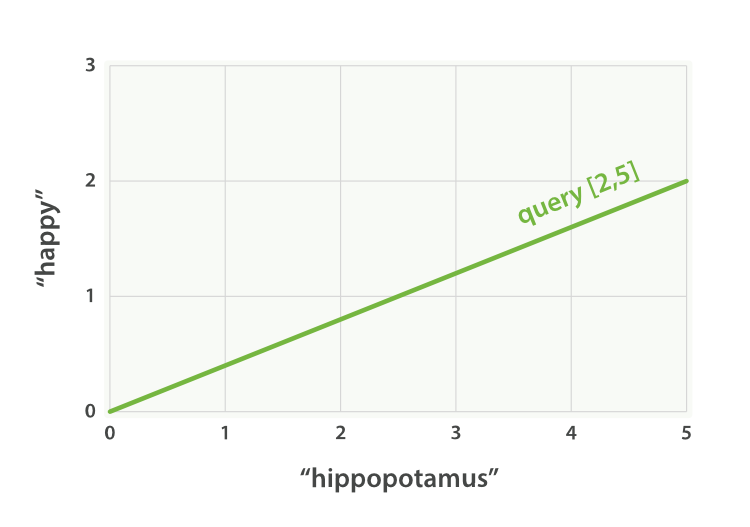
在向量空间模型里, 向量空间模型里的每个数字都代表一个词的 权重 ,与 词频/逆向文档频率(term frequency/inverse document frequency) 计算方式类似。
设想如果查询 “happy hippopotamus” ,常见词 happy 的权重较低,不常见词 hippopotamus 权重较高,假设 happy 的权重是 2 , hippopotamus 的权重是 5 ,可以将这个二维向量—— [2,5] ——在坐标系下作条直线,线的起点是 (0,0) 终点是 (2,5) ,如图 图 27 “表示 “happy hippopotamus” 的二维查询向量” 。
图 27. 表示 “happy hippopotamus” 的二维查询向量
现在,设想我们有三个文档:
- I am happy in summer 。
- After Christmas I’m a hippopotamus 。
- The happy hippopotamus helped Harry 。
可以为每个文档都创建包括每个查询词—— happy 和 hippopotamus ——权重的向量,然后将这些向量置入同一个坐标系中,如图 图 28 ““happy hippopotamus” 查询及文档向量” :
- 文档 1:
(happy,____________)——[2,0] - 文档 2:
( ___ ,hippopotamus)——[0,5] - 文档 3:
(happy,hippopotamus)——[2,5]
图 28. “happy hippopotamus” 查询及文档向量
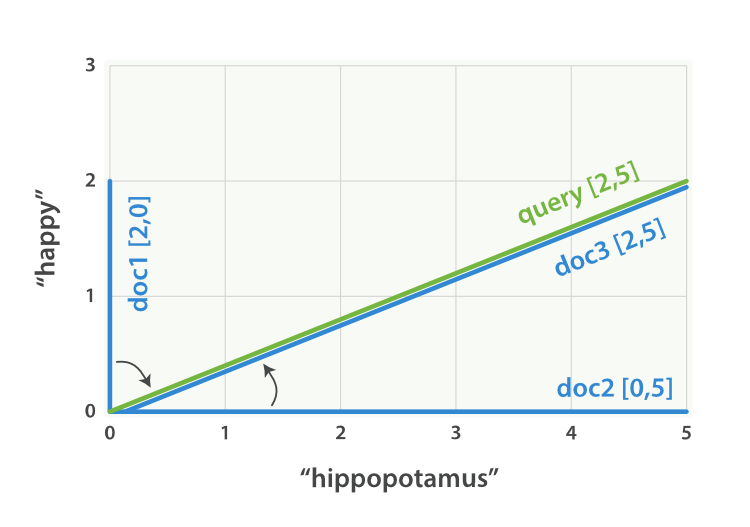
向量之间是可以比较的,只要测量查询向量和文档向量之间的角度就可以得到每个文档的相关度,文档 1 与查询之间的角度最大,所以相关度低;文档 2 与查询间的角度较小,所以更相关;文档 3 与查询的角度正好吻合,完全匹配。
关于比较两个向量的更多信息可以参考 余弦近似度(cosine similarity)。
现在已经讲完评分计算的基本理论,我们可以继续了解 Lucene 是如何实现评分计算的。
Lucene 的实用评分函数
对于多词查询, Lucene 使用 布尔模型(Boolean model) 、 TF/IDF 以及 向量空间模型(vector space model) ,然后将它们组合到单个高效的包里以收集匹配文档并进行评分计算。
一个多词查询
GET /my_index/doc/_search
{
"query": {
"match": {
"text": "quick fox"
}
}
}
会在内部被重写为:
GET /my_index/doc/_search
{
"query": {
"bool": {
"should": [
{"term": { "text": "quick" }},
{"term": { "text": "fox" }}
]
}
}
}
bool 查询实现了布尔模型,在这个例子中,它会将包括词 quick 和 fox 或两者兼有的文档作为查询结果。
只要一个文档与查询匹配,Lucene 就会为查询计算评分,然后合并每个匹配词的评分结果。这里使用的评分计算公式叫做 实用评分函数(practical scoring function) 。看似很高大上,但是别被吓到——多数的组件都已经介绍过,下一步会讨论它引入的一些新元素。
score(q,d) = <1>
queryNorm(q) <2>
· coord(q,d) <3>
· ∑ ( <4>
tf(t in d) <5>
· idf(t)² <6>
· t.getBoost() <7>
· norm(t,d) <8>
) (t in q) <9>
score(q,d)是文档d与查询q的相关度评分。
queryNorm(q)是 查询归一化 因子 (新)。
coord(q,d)是 协调 因子 (新)。
查询
q中每个词t对于文档d的权重和。
tf(t in d)是词t在文档d中的 [词频]

idf(t)是词t的 逆向文档频率 。

t.getBoost()是查询中使用的 boost(新)。

norm(t,d)是 字段长度归一值 ,与 索引时字段层 boost (如果存在)的和(新)。
上节已介绍过 score 、 tf 和 idf 。现在来介绍 queryNorm 、 coord 、 t.getBoost 和 norm 。
我们会在本章后面继续探讨 查询时的权重提升 的问题,但是首先需要了解查询归一化、协调和索引时字段层面的权重提升等概念。
查询归一因子
查询归一因子 ( queryNorm )试图将查询 归一化 , 这样就能将两个不同的查询结果相比较。
尽管查询归一值的目的是为了使查询结果之间能够相互比较,但是它并不十分有效,因为相关度评分_score的目的是为了将当前查询的结果进行排序,比较不同查询结果的相关度评分没有太大意义。
这个因子是在查询过程的最前面计算的,具体的计算依赖于具体查询,一个典型的实现如下:
queryNorm = 1 / √sumOfSquaredWeights
sumOfSquaredWeights是查询里每个词的 IDF 的平方和。
查询协调
协调因子 ( coord ) 可以为那些查询词包含度高的文档提供奖励,文档里出现的查询词越多,它越有机会成为好的匹配结果。
设想查询 quick brown fox ,每个词的权重都是 1.5 。如果没有协调因子,最终评分会是文档里所有词权重的总和。例如:
- 文档里有
fox→ 评分: 1.5 - 文档里有
quick fox→ 评分: 3.0 - 文档里有
quick brown fox→ 评分: 4.5
协调因子将评分与文档里匹配词的数量相乘,然后除以查询里所有词的数量,如果使用协调因子,评分会变成:
- 文档里有
fox→ 评分:1.5 * 1 / 3= 0.5 - 文档里有
quick fox→ 评分:3.0 * 2 / 3= 2.0 - 文档里有
quick brown fox→ 评分:4.5 * 3 / 3= 4.5
协调因子能使包含所有三个词的文档比只包含两个词的文档评分要高出很多。
回想将查询 quick brown fox 重写成 bool 查询的形式:
GET /_search
{
"query": {
"bool": {
"should": [
{ "term": { "text": "quick" }},
{ "term": { "text": "brown" }},
{ "term": { "text": "fox" }}
]
}
}
}
bool 查询默认会对所有 should 语句使用协调功能,不过也可以将其禁用。为什么要这样做?通常的回答是——无须这样。查询协调通常是件好事,当使用 bool 查询将多个高级查询如 match 查询包裹的时候,让协调功能开启是有意义的,匹配的语句越多,查询请求与返回文档间的重叠度就越高。
但在某些高级应用中,将协调功能关闭可能更好。设想正在查找同义词 jump 、 leap 和 hop 时,并不关心会出现多少个同义词,因为它们都表示相同的意思,实际上,只有其中一个同义词会出现,这是不使用协调因子的一个好例子:
GET /_search
{
"query": {
"bool": {
"disable_coord": true,
"should": [
{ "term": { "text": "jump" }},
{ "term": { "text": "hop" }},
{ "term": { "text": "leap" }}
]
}
}
}
当使用同义词的时候(参照: 同义词 ),Lucene 内部是这样的:重写的查询会禁用同义词的协调功能。大多数禁用操作的应用场景是自动处理的,无须为此担心。
索引时字段层权重提升
我们会讨论 查询时的权重提升,让字段 权重提升 就是让某个字段比其他字段更重要。 当然在索引时也能做到如此。实际上,权重的提升会被应用到字段的每个词,而不是字段本身。
将提升值存储在索引中无须更多空间,这个字段层索引时的提升值与字段长度归一值(参见 字段长度归一值 )一起作为单个字节存于索引, norm(t,d) 是前面公式的返回值。
我们不建议在建立索引时对字段提升权重,有以下原因:
- 将提升值与字段长度归一值合在单个字节中存储会丢失字段长度归一值的精度,这样会导致 Elasticsearch 不知如何区分包含三个词的字段和包含五个词的字段。
- 要想改变索引时的提升值,就必须重新为所有文档建立索引,与此不同的是,查询时的提升值可以随着每次查询的不同而更改。
如果一个索引时权重提升的字段有多个值,提升值会按照每个值来自乘,这会导致该字段的权重急剧上升。
查询时赋予权重 是更为简单、清楚、灵活的选择。
了解了查询归一化、协同和索引时权重提升这些方式后,可以进一步了解相关度计算最有用的工具:查询时的权重提升。
查询时权重提升
在 语句优先级(Prioritizing Clauses) 中,我们解释过如何在搜索时使用 boost 参数让一个查询语句比其他语句更重要。 例如:
GET /_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {
"query": "quick brown fox",
"boost": 2 <1>
}
}
},
{
"match": { <2>
"content": "quick brown fox"
}
}
]
}
}
}
title查询语句的重要性是content查询的 2 倍,因为它的权重提升值为2。
boost的查询语句的值为1。
查询时的权重提升 是可以用来影响相关度的主要工具,任意类型的查询都能接受 boost 参数。 将 boost设置为 2 ,并不代表最终的评分 _score 是原值的两倍;实际的权重值会经过归一化和一些其他内部优化过程。尽管如此,它确实想要表明一个提升值为 2 的句子的重要性是提升值为 1 语句的两倍。
在实际应用中,无法通过简单的公式得出某个特定查询语句的 “正确” 权重提升值,只能通过不断尝试获得。需要记住的是 boost 只是影响相关度评分的其中一个因子;它还需要与其他因子相互竞争。在前例中, title 字段相对 content 字段可能已经有一个 “缺省的” 权重提升值,这因为在 字段长度归一值 中,标题往往比相关内容要短,所以不要想当然的去盲目提升一些字段的权重。选择权重,检查结果,如此反复。
提升索引权重
当在多个索引中搜索时, 可以使用参数 indices_boost 来提升整个索引的权重,在下面例子中,当要为最近索引的文档分配更高权重时,可以这么做:
GET /docs_2014_*/_search <1>
{
"indices_boost": { <2>
"docs_2014_10": 3,
"docs_2014_09": 2
},
"query": {
"match": {
"text": "quick brown fox"
}
}
}
docs_2014_开始的索引。
docs_2014_10中的所有文件的权重是3,索引docs_2014_09中是2,其他所有匹配的索引权重为默认值1。
t.getBoost()
这些提升值在 Lucene 的 实用评分函数 中可以通过 t.getBoost() 获得。 权重提升不会被应用于它在查询表达式中出现的层,而是会被合并下转至每个词中。 t.getBoost() 始终返回当前词的权重或当前分析链上查询的权重。
explain的输出是相当复杂的,在explanation里面完全看不到boost值,也完全无法访问上面提到的t.getBoost()方法,权重值融合在queryNorm中并应用到每个词。尽管说,queryNorm对于每个词都是相同的,还是会发现一个权重提升过的词的queryNorm值要高于一个没有提升过的。
使用查询结构修改相关度
Elasticsearch 的查询表达式相当灵活, 可以通过调整查询结构中查询语句的所处层次,从而或多或少改变其重要性,比如,设想下面这个查询:
quick OR brown OR red OR fox
可以将所有词都放在 bool 查询的同一层中:
GET /_search
{
"query": {
"bool": {
"should": [
{ "term": { "text": "quick" }},
{ "term": { "text": "brown" }},
{ "term": { "text": "red" }},
{ "term": { "text": "fox" }}
]
}
}
}
这个查询可能最终给包含 quick 、 red 和 brown 的文档评分与包含 quick 、 red 、 fox 文档的评分相同,这里 Red 和 brown 是同义词,可能只需要保留其中一个,而我们真正要表达的意思是想做以下查询:
quick OR (brown OR red) OR fox
根据标准的布尔逻辑,这与原始的查询是完全一样的,但是我们已经在 组合查询(Combining Queries)中看到, bool 查询不关心文档匹配的 程度 ,只关心是否能匹配。
上述查询有个更好的方式:
GET /_search
{
"query": {
"bool": {
"should": [
{ "term": { "text": "quick" }},
{ "term": { "text": "fox" }},
{
"bool": {
"should": [
{ "term": { "text": "brown" }},
{ "term": { "text": "red" }}
]
}
}
]
}
}
}
现在, red 和 brown 处于相互竞争的层次, quick 、 fox 以及 red OR brown 则是处于顶层且相互竞争的词。
我们已经讨论过如何使用 match 、multi_match 、term 、bool 和 dis_max 查询修改相关度评分。本章后面的内容会介绍另外三个与相关度评分有关的查询: boosting 查询、 constant_score 查询和 function_score 查询。
Not Quite Not
在互联网上搜索 “Apple”,返回的结果很可能是一个公司、水果和各种食谱。 我们可以在 bool 查询中用 must_not 语句来排除像 pie 、 tart 、 crumble 和 tree 这样的词,从而将查询结果的范围缩小至只返回与 “Apple” (苹果)公司相关的结果:
GET /_search
{
"query": {
"bool": {
"must": {
"match": {
"text": "apple"
}
},
"must_not": {
"match": {
"text": "pie tart fruit crumble tree"
}
}
}
}
}
但谁又敢保证在排除 tree 或 crumble 这种词后,不会错失一个与苹果公司特别相关的文档呢?有时, must_not 条件会过于严格。
权重提升查询
boosting 查询 恰恰能解决这个问题。 它仍然允许我们将关于水果或甜点的结果包括到结果中,但是使它们降级——即降低它们原来可能应有的排名:
GET /_search
{
"query": {
"boosting": {
"positive": {
"match": {
"text": "apple"
}
},
"negative": {
"match": {
"text": "pie tart fruit crumble tree"
}
},
"negative_boost": 0.5
}
}
}
它接受 positive 和 negative 查询。只有那些匹配 positive 查询的文档罗列出来,对于那些同时还匹配 negative 查询的文档将通过文档的原始 _score 与 negative_boost 相乘的方式降级后的结果。
为了达到效果, negative_boost 的值必须小于 1.0 。在这个示例中,所有包含负向词的文档评分 _score都会减半。
忽略 TF/IDF
有时候我们根本不关心 TF/IDF , 只想知道一个词是否在某个字段中出现过。可能搜索一个度假屋并希望它能尽可能有以下设施:
- WiFi
- Garden(花园)
- Pool(游泳池)
这个度假屋的文档如下:
{ "description": "A delightful four-bedroomed house with ... " }
可以用简单的 match 查询进行匹配:
GET /_search
{
"query": {
"match": {
"description": "wifi garden pool"
}
}
}
但这并不是真正的 全文搜索 ,此种情况下,TF/IDF 并无用处。我们既不关心 wifi 是否为一个普通词,也不关心它在文档中出现是否频繁,关心的只是它是否曾出现过。实际上,我们希望根据房屋不同设施的数量对其排名——设施越多越好。如果设施出现,则记 1 分,不出现记 0 分。
constant_score 查询
在 constant_score 查询中,它可以包含查询或过滤,为任意一个匹配的文档指定评分 1 ,忽略 TF/IDF 信息:
GET /_search
{
"query": {
"bool": {
"should": [
{ "constant_score": {
"query": { "match": { "description": "wifi" }}
}},
{ "constant_score": {
"query": { "match": { "description": "garden" }}
}},
{ "constant_score": {
"query": { "match": { "description": "pool" }}
}}
]
}
}
}
或许不是所有的设施都同等重要——对某些用户来说有些设施更有价值。如果最重要的设施是游泳池,那我们可以为更重要的设施增加权重:
GET /_search
{
"query": {
"bool": {
"should": [
{ "constant_score": {
"query": { "match": { "description": "wifi" }}
}},
{ "constant_score": {
"query": { "match": { "description": "garden" }}
}},
{ "constant_score": {
"boost": 2 <1>
"query": { "match": { "description": "pool" }}
}}
]
}
}
}
pool语句的权重提升值为2,而其他的语句为1。
我们可以给 features 字段加上 not_analyzed 类型来提升度假屋文档的匹配能力:
{ "features": [ "wifi", "pool", "garden" ] }
默认情况下,一个 not_analyzed 字段会禁用 字段长度归一值(field-length norms) 的功能, 并将 index_options 设为 docs 选项,禁用 词频 ,但还是存在问题:每个词的 倒排文档频率 仍然会被考虑。
可以采用与之前相同的方法 constant_score 查询来解决这个问题:
GET /_search
{
"query": {
"bool": {
"should": [
{ "constant_score": {
"query": { "match": { "features": "wifi" }}
}},
{ "constant_score": {
"query": { "match": { "features": "garden" }}
}},
{ "constant_score": {
"boost": 2
"query": { "match": { "features": "pool" }}
}}
]
}
}
}
实际上,每个设施都应该看成一个过滤器,对于度假屋来说要么具有某个设施要么没有——过滤器因为其性质天然合适。而且,如果使用过滤器,我们还可以利用缓存。
这里的问题是:过滤器无法计算评分。这样就需要寻求一种方式将过滤器和查询间的差异抹平。 function_score 查询不仅正好可以扮演这个角色,而且有更强大的功能。
function_score 查询
function_score 查询 是用来控制评分过程的终极武器,它允许为每个与主查询匹配的文档应用一个函数,以达到改变甚至完全替换原始查询评分 _score 的目的。
实际上,也能用过滤器对结果的 子集 应用不同的函数,这样一箭双雕:既能高效评分,又能利用过滤器缓存。
Elasticsearch 预定义了一些函数:
weight为每个文档应用一个简单而不被规范化的权重提升值:当
weight为2时,最终结果为2 * _score。field_value_factor使用这个值来修改
_score,如将popularity或votes(受欢迎或赞)作为考虑因素。random_score为每个用户都使用一个不同的随机评分对结果排序,但对某一具体用户来说,看到的顺序始终是一致的。
衰减函数 ——
linear、exp、gauss将浮动值结合到评分
_score中,例如结合publish_date获得最近发布的文档,结合geo_location获得更接近某个具体经纬度(lat/lon)地点的文档,结合price获得更接近某个特定价格的文档。script_score如果需求超出以上范围时,用自定义脚本可以完全控制评分计算,实现所需逻辑。
如果没有 function_score 查询,就不能将全文查询与最新发生这种因子结合在一起评分,而不得不根据评分 _score 或时间 date 进行排序;这会相互影响抵消两种排序各自的效果。这个查询可以使两个效果融合:可以仍然根据全文相关度进行排序,但也会同时考虑最新发布文档、流行文档、或接近用户希望价格的产品。正如所设想的,查询要考虑所有这些因素会非常复杂,让我们先从简单的例子开始,然后顺着梯子慢慢向上爬,增加复杂度。
按受欢迎度提升权重
设想有个网站供用户发布博客并且可以让他们为自己喜欢的博客点赞, 我们希望将更受欢迎的博客放在搜索结果列表中相对较上的位置,同时全文搜索的评分仍然作为相关度的主要排序依据,可以简单的通过存储每个博客的点赞数来实现它:
PUT /blogposts/post/1
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 6
}
在搜索时,可以将 function_score 查询与 field_value_factor 结合使用, 即将点赞数与全文相关度评分结合:
GET /blogposts/post/_search
{
"query": {
"function_score": { <1>
"query": { <2>
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": { <3>
"field": "votes" <4>
}
}
}
}
function_score查询将主查询和函数包括在内。
field_value_factor函数会被应用到每个与主query匹配的文档。
votes字段都 必须 有值供function_score计算。如果 没有 文档的votes字段有值,那么就 必须 使用missing属性 提供的默认值来进行评分计算。
在前面示例中,每个文档的最终评分 _score 都做了如下修改:
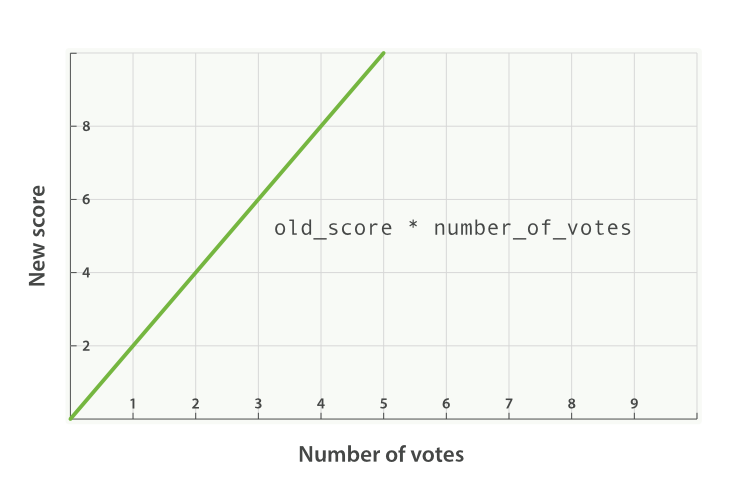
new_score = old_score * number_of_votes
然而这并不会带来出人意料的好结果,全文评分 _score 通常处于 0 到 10 之间,如下图 图 29 “受欢迎度的线性关系基于 _score 的原始值 2.0” 中,有 10 个赞的博客会掩盖掉全文评分,而 0 个赞的博客的评分会被置为 0 。
图 29. 受欢迎度的线性关系基于 _score 的原始值2.0
modifier
一种融入受欢迎度更好方式是用 modifier 平滑 votes 的值。 换句话说,我们希望最开始的一些赞更重要,但是其重要性会随着数字的增加而降低。 0 个赞与 1 个赞的区别应该比 10 个赞与 11 个赞的区别大很多。
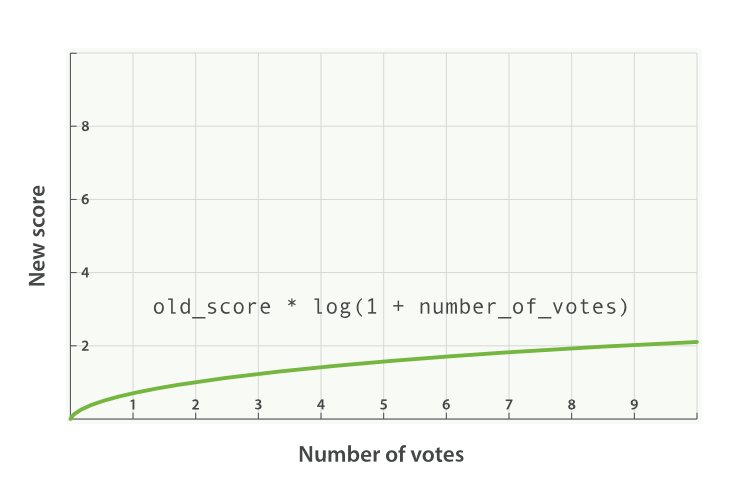
对于上述情况,典型的 modifier 应用是使用 log1p 参数值,公式如下:
new_score = old_score * log(1 + number_of_votes)
log 对数函数使 votes 赞字段的评分曲线更平滑,如图 图 30 “受欢迎度的对数关系基于 _score 的原始值 2.0” :
图 30. 受欢迎度的对数关系基于 _score 的原始值 2.0
带 modifier 参数的请求如下:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p" <1>
}
}
}
}
modifier为log1p。
修饰语 modifier 的值可以为: none (默认状态)、 log 、 log1p 、 log2p 、 ln 、 ln1p 、 ln2p 、 square 、 sqrt 以及 reciprocal 。想要了解更多信息请参照: field_value_factor 文档.
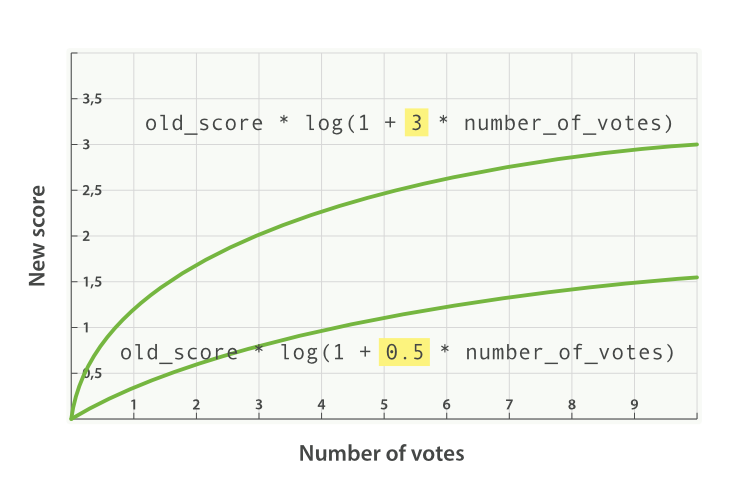
factor
可以通过将 votes 字段与 factor 的积来调节受欢迎程度效果的高低:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 2 <1>
}
}
}
}
添加了 factor 会使公式变成这样:
new_score = old_score * log(1 + factor * number_of_votes)
factor 值大于 1 会提升效果, factor 值小于 1 会降低效果,如图 图 31 “受欢迎度的对数关系基于多个不同因子” 。
图 31. 受欢迎度的对数关系基于多个不同因子
boost_mode
或许将全文评分与 field_value_factor 函数值乘积的效果仍然可能太大, 我们可以通过参数 boost_mode来控制函数与查询评分 _score 合并后的结果,参数接受的值为:
multiply评分
_score与函数值的积(默认)sum评分
_score与函数值的和min评分
_score与函数值间的较小值max评分
_score与函数值间的较大值replace函数值替代评分
_score
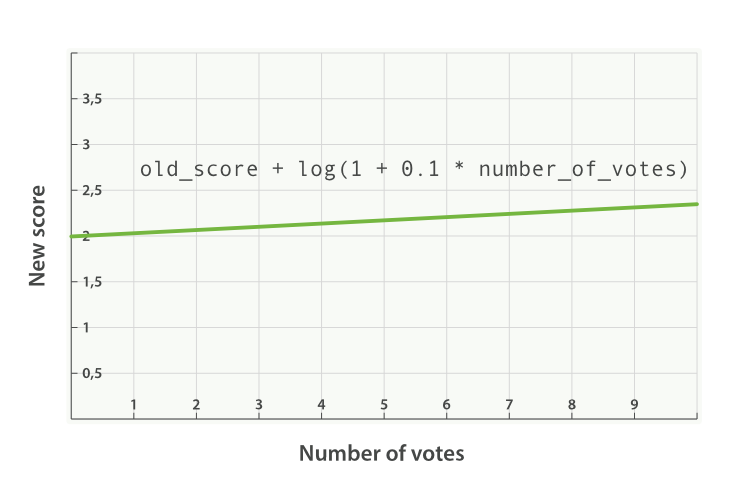
与使用乘积的方式相比,使用评分 _score 与函数值求和的方式可以弱化最终效果,特别是使用一个较小 factor 因子时:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum"
}
}
}
_score。
之前请求的公式现在变成下面这样(参见 图 32 “使用 sum 结合受欢迎程度” ):
new_score = old_score + log(1 + 0.1 * number_of_votes)
图 32. 使用 sum 结合受欢迎程度
max_boost
最后,可以使用 max_boost 参数限制一个函数的最大效果:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum",
"max_boost": 1.5
}
}
}
field_value_factor函数的结果如何,最终结果都不会大于1.5。
max_boost只对函数的结果进行限制,不会对最终评分_score产生直接影响。
过滤集提升权重
回到 忽略 TF/IDF 里处理过的问题,我们希望根据每个度假屋的特性数量来评分, 当时我们希望能用缓存的过滤器来影响评分,现在 function_score 查询正好可以完成这件事情。
到目前为止,我们展现的都是为所有文档应用单个函数的使用方式,现在会用过滤器将结果划分为多个子集(每个特性一个过滤器),并为每个子集使用不同的函数。
在下面例子中,我们会使用 weight 函数,它与 boost 参数类似可以用于任何查询。有一点区别是 weight没有被 Luence 归一化成难以理解的浮点数,而是直接被应用。
查询的结构需要做相应变更以整合多个函数:
GET /_search
{
"query": {
"function_score": {
"filter": { <1>
"term": { "city": "Barcelona" }
},
"functions": [ <2>
{
"filter": { "term": { "features": "wifi" }}, <3>
"weight": 1
},
{
"filter": { "term": { "features": "garden" }}, <4>
"weight": 1
},
{
"filter": { "term": { "features": "pool" }}, <5>
"weight": 2 <6>
}
],
"score_mode": "sum", <7>
}
}
}
function_score查询有个filter过滤器而不是query查询。
functions关键字存储着一个将被应用的函数列表。
filter过滤器(可选的)匹配的文档。
pool比其他特性更重要,所以它有更高weight。
score_mode指定各个函数的值进行组合运算的方式。
这个新特性需要注意的地方会在以下小节介绍。
过滤 vs. 查询
首先要注意的是 filter 过滤器代替了 query 查询, 在本例中,我们无须使用全文搜索,只想找到 city字段中包含 Barcelona 的所有文档,逻辑用过滤比用查询表达更清晰。过滤器返回的所有文档的评分 _score 的值为 1 。 function_score 查询接受 query 或 filter ,如果没有特别指定,则默认使用 match_all 查询。
函数 functions
functions 关键字保持着一个将要被使用的函数列表。 可以为列表里的每个函数都指定一个 filter 过滤器,在这种情况下,函数只会被应用到那些与过滤器匹配的文档,例子中,我们为与过滤器匹配的文档指定权重值 weight 为 1 (为与 pool 匹配的文档指定权重值为 2 )。
评分模式 score_mode
每个函数返回一个结果,所以需要一种将多个结果缩减到单个值的方式,然后才能将其与原始评分 _score合并。评分模式 score_mode 参数正好扮演这样的角色, 它接受以下值:
multiply函数结果求积(默认)。
sum函数结果求和。
avg函数结果的平均值。
max函数结果的最大值。
min函数结果的最小值。
first使用首个函数(可以有过滤器,也可能没有)的结果作为最终结果
在本例中,我们将每个过滤器匹配结果的权重 weight 求和,并将其作为最终评分结果,所以会使用 sum评分模式。
不与任何过滤器匹配的文档会保有其原始评分, _score 值的为 1 。
随机评分
你可能会想知道 一致随机评分(consistently random scoring) 是什么,又为什么会使用它。 之前的例子是个很好的应用场景,前例中所有的结果都会返回 1 、 2 、 3 、 4 或 5 这样的最终评分 _score ,可能只有少数房子的评分是 5 分,而有大量房子的评分是 2 或 3 。
作为网站的所有者,总会希望让广告有更高的展现率。在当前查询下,有相同评分 _score 的文档会每次都以相同次序出现,为了提高展现率,在此引入一些随机性可能会是个好主意,这能保证有相同评分的文档都能有均等相似的展现机率。
我们想让每个用户看到不同的随机次序,但也同时希望如果是同一用户翻页浏览时,结果的相对次序能始终保持一致。这种行为被称为 一致随机(consistently random) 。
random_score 函数会输出一个 0 到 1 之间的数, 当种子 seed 值相同时,生成的随机结果是一致的,例如,将用户的会话 ID 作为 seed :
GET /_search
{
"query": {
"function_score": {
"filter": {
"term": { "city": "Barcelona" }
},
"functions": [
{
"filter": { "term": { "features": "wifi" }},
"weight": 1
},
{
"filter": { "term": { "features": "garden" }},
"weight": 1
},
{
"filter": { "term": { "features": "pool" }},
"weight": 2
},
{
"random_score": { <1>
"seed": "the users session id" <2>
}
}
],
"score_mode": "sum"
}
}
}
random_score语句没有任何过滤器filter,所以会被应用到所有文档。
seed,让该用户的随机始终保持一致,相同的种子seed会产生相同的随机结果。
当然,如果增加了与查询匹配的新文档,无论是否使用一致随机,其结果顺序都会发生变化。
越近越好
很多变量都可以影响用户对于度假屋的选择, 也许用户希望离市中心近点,但如果价格足够便宜,也有可能选择一个更远的住处,也有可能反过来是正确的:愿意为最好的位置付更多的价钱。
如果我们添加过滤器排除所有市中心方圆 1 千米以外的度假屋,或排除所有每晚价格超过 £100 英镑的,我们可能会将用户愿意考虑妥协的那些选择排除在外。
function_score 查询会提供一组 衰减函数(decay functions) , 让我们有能力在两个滑动标准,如地点和价格,之间权衡。
有三种衰减函数—— linear 、 exp 和 gauss (线性、指数和高斯函数),它们可以操作数值、时间以及经纬度地理坐标点这样的字段。所有三个函数都能接受以下参数:
origin中心点 或字段可能的最佳值,落在原点
origin上的文档评分_score为满分1.0。scale衰减率,即一个文档从原点
origin下落时,评分_score改变的速度。(例如,每 £10 欧元或每 100 米)。decay从原点
origin衰减到scale所得的评分_score,默认值为0.5。offset以原点
origin为中心点,为其设置一个非零的偏移量offset覆盖一个范围,而不只是单个原点。在范围-offset <= origin <= +offset内的所有评分_score都是1.0。
这三个函数的唯一区别就是它们衰减曲线的形状,用图来说明会更为直观(参见 图 33 “衰减函数曲线”)。
图 33. 衰减函数曲线
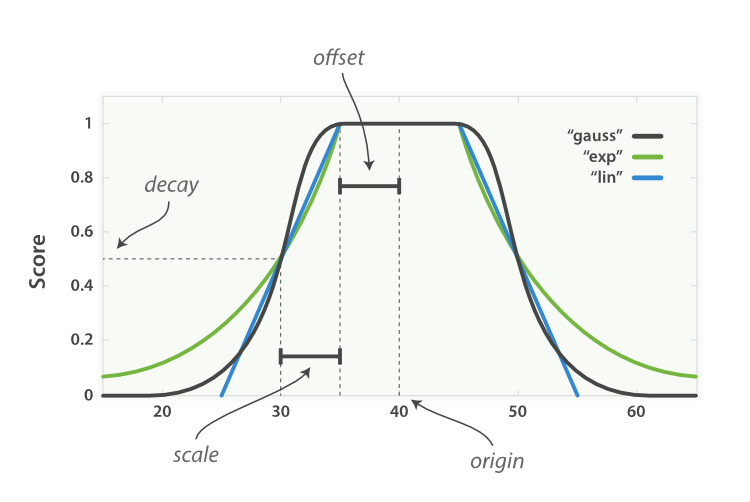
图 图 33 “衰减函数曲线” 中所有曲线的原点 origin (即中心点)的值都是 40 , offset 是 5 ,也就是在范围 40 - 5 <= value <= 40 + 5 内的所有值都会被当作原点 origin 处理——所有这些点的评分都是满分 1.0 。
在此范围之外,评分开始衰减,衰减率由 scale 值(此例中的值为 5 )和 衰减值 decay (此例中为默认值 0.5 )共同决定。结果是所有三个曲线在 origin +/- (offset + scale) 处的评分都是 0.5 ,即点 30和 50 处。
linear 、 exp 和 gauss (线性、指数和高斯)函数三者之间的区别在于范围( origin +/- (offset + scale) )之外的曲线形状:
linear线性函数是条直线,一旦直线与横轴 0 相交,所有其他值的评分都是0.0。exp指数函数是先剧烈衰减然后变缓。gauss高斯函数是钟形的——它的衰减速率是先缓慢,然后变快,最后又放缓。
选择曲线的依据完全由期望评分 _score 的衰减速率来决定,即距原点 origin 的值。
回到我们的例子:用户希望租一个离伦敦市中心近( { "lat": 51.50, "lon": 0.12} )且每晚不超过 £100 英镑的度假屋,而且与距离相比, 我们的用户对价格更为敏感,这样查询可以写成:
GET /_search
{
"query": {
"function_score": {
"functions": [
{
"gauss": {
"location": { <1>
"origin": { "lat": 51.5, "lon": 0.12 },
"offset": "2km",
"scale": "3km"
}
}
},
{
"gauss": {
"price": { <2>
"origin": "50", <3>
"offset": "50",
"scale": "20"
}
},
"weight": 2 <4>
}
]
}
}
}
location字段以地理坐标点geo_point映射。
price字段是数值。
origin为什么是50而不是100。
price语句是location语句权重的两倍。
location 语句可以简单理解为:
- 以伦敦市中作为原点
origin。 - 所有距原点
origin2km范围内的位置的评分是1.0。 - 距中心
5km(offset + scale)的位置的评分是0.5。
理解 price 价格语句
price 语句使用了一个小技巧:用户希望选择 £100 英镑以下的度假屋,但是例子中的原点被设置成 £50 英镑,价格不能为负,但肯定是越低越好,所以 £0 到 £100 英镑内的所有价格都认为是比较好的。
如果我们将原点 origin 被设置成 £100 英镑,那么低于 £100 英镑的度假屋的评分会变低,与其这样不如将原点 origin 和偏移量 offset 同时设置成 £50 英镑,这样就能使只有在价格高于 £100 英镑( origin + offset )时评分才会变低。
weight参数可以被用来调整每个语句的贡献度,权重weight的默认值是1.0。这个值会先与每个句子的评分相乘,然后再通过score_mode的设置方式合并。
脚本评分
最后,如果所有 function_score 内置的函数都无法满足应用场景,可以使用 script_score 函数自行实现逻辑。
举个例子,想将利润空间作为因子加入到相关度评分计算,在业务中,利润空间和以下三点相关:
price度假屋每晚的价格。- 会员用户的级别——某些等级的用户可以在每晚房价高于某个
threshold阀值价格的时候享受折扣discount。 - 用户享受折扣后,经过议价的每晚房价的利润
margin。
计算每个度假屋利润的算法如下:
if (price < threshold) {
profit = price * margin
} else {
profit = price * (1 - discount) * margin;
}
我们很可能不想用绝对利润作为评分,这会弱化其他如地点、受欢迎度和特性等因子的作用,而是将利润用目标利润 target 的百分比来表示,高于 目标的利润空间会有一个正向评分(大于 1.0 ),低于目标的利润空间会有一个负向分数(小于 1.0 ):
if (price < threshold) {
profit = price * margin
} else {
profit = price * (1 - discount) * margin
}
return profit / target
Elasticsearch 里使用 Groovy 作为默认的脚本语言,它与JavaScript很像, 上面这个算法用 Groovy 脚本表示如下:
price = doc['price'].value <1>
margin = doc['margin'].value <2>
if (price < threshold) { <3>
return price * margin / target
}
return price * (1 - discount) * margin / target <4>
price和margin变量可以分别从文档的price和margin字段提取。
threshold、discount和target是作为参数params传入的。
最终我们将 script_score 函数与其他函数一起使用:
GET /_search
{
"function_score": {
"functions": [
{ ...location clause... }, <1>
{ ...price clause... }, <2>
{
"script_score": {
"params": { <3>
"threshold": 80,
"discount": 0.1,
"target": 10
},
"script": "price = doc['price'].value; margin = doc['margin'].value;
if (price < threshold) { return price * margin / target };
return price * (1 - discount) * margin / target;" <4>
}
}
]
}
}
location和price语句在 衰减函数 中解释过。
params传递,我们可以查询时动态改变脚本无须重新编译。
\n或;符号替代。
这个查询根据用户对地点和价格的需求,返回用户最满意的文档,同时也考虑到我们对于盈利的要求。
script_score函数提供了巨大的灵活性, 可以通过脚本访问文档里的所有字段、当前评分_score甚至词频、逆向文档频率和字段长度规范值这样的信息(参见 see 脚本对文本评分)。有人说使用脚本对性能会有影响,如果确实发现脚本执行较慢,可以有以下三种选择:
- 尽可能多的提前计算各种信息并将结果存入每个文档中。
- Groovy 很快,但没 Java 快。 可以将脚本用原生的 Java 脚本重新实现。(参见 原生 Java 脚本)。
- 仅对那些最佳评分的文档应用脚本,使用 重新评分 中提到的
rescore功能。
可插拔的相似度算法
在进一步讨论相关度和评分之前,我们会以一个更高级的话题结束本章节的内容:可插拔的相似度算法(Pluggable Similarity Algorithms)。 Elasticsearch 将 实用评分算法 作为默认相似度算法,它也能够支持其他的一些算法,这些算法可以参考 相似度模块 文档。
Okapi BM25
能与 TF/IDF 和向量空间模型媲美的就是 Okapi BM25 ,它被认为是 当今最先进的 排序函数。 BM25 源自 概率相关模型(probabilistic relevance model) ,而不是向量空间模型,但这个算法也和 Lucene 的实用评分函数有很多共通之处。
BM25 同样使用词频、逆向文档频率以及字段长归一化,但是每个因子的定义都有细微区别。与其详细解释 BM25 公式,倒不如将关注点放在 BM25 所能带来的实际好处上。
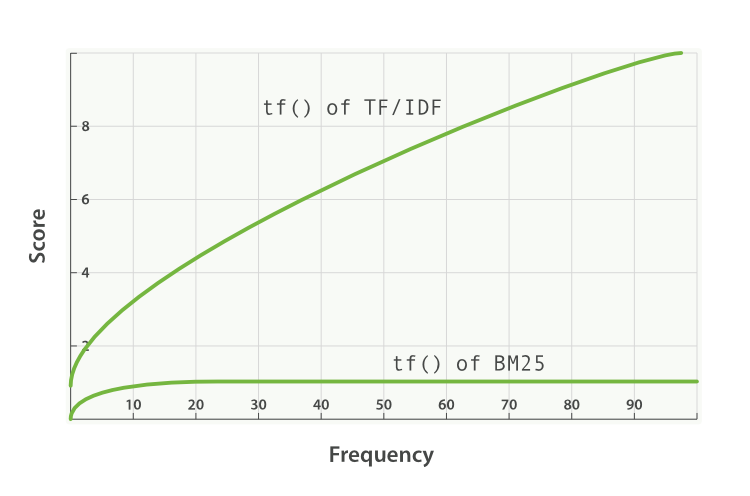
词频饱和度
TF/IDF 和 BM25 同样使用 逆向文档频率 来区分普通词(不重要)和非普通词(重要), 同样认为(参见 词频 )文档里的某个词出现次数越频繁,文档与这个词就越相关。
不幸的是,普通词随处可见, 实际上一个普通词在同一个文档中大量出现的作用会由于该词在 所有 文档中的大量出现而被抵消掉。
曾经有个时期,将 最 普通的词(或 停用词 ,参见 停用词)从索引中移除被认为是一种标准实践, TF/IDF 正是在这种背景下诞生的。TF/IDF 没有考虑词频上限的问题,因为高频停用词已经被移除了。
Elasticsearch 的 standard 标准分析器( string 字段默认使用)不会移除停用词,因为尽管这些词的重要性很低,但也不是毫无用处。这导致:在一个相当长的文档中,像 the 和 and 这样词出现的数量会高得离谱,以致它们的权重被人为放大。
另一方面,BM25 有一个上限,文档里出现 5 到 10 次的词会比那些只出现一两次的对相关度有着显著影响。但是如图 TF/IDF 与 BM25 的词频饱和度 所见,文档中出现 20 次的词几乎与那些出现上千次的词有着相同的影响。
这就是 非线性词频饱和度(nonlinear term-frequency saturation) 。
图 34. TF/IDF 与 BM25 的词频饱和度
字段长度归一化(Field-length normalization)
在 字段长归一化 中,我们提到过 Lucene 会认为较短字段比较长字段更重要:字段某个词的频度所带来的重要性会被这个字段长度抵消,但是实际的评分函数会将所有字段以同等方式对待。它认为所有较短的 title 字段比所有较长的 body 字段更重要。
BM25 当然也认为较短字段应该有更多的权重,但是它会分别考虑每个字段内容的平均长度,这样就能区分短 title 字段和 长 title 字段。
title字段因为其长度比body字段 自然 有更高的权重提升值。由于字段长度的差异只能应用于单字段,这种自然的权重提升会在使用 BM25 时消失。
BM25 调优
不像 TF/IDF ,BM25 有一个比较好的特性就是它提供了两个可调参数:
k1这个参数控制着词频结果在词频饱和度中的上升速度。默认值为
1.2。值越小饱和度变化越快,值越大饱和度变化越慢。b这个参数控制着字段长归一值所起的作用,
0.0会禁用归一化,1.0会启用完全归一化。默认值为0.75。
在实践中,调试 BM25 是另外一回事, k1 和 b 的默认值适用于绝大多数文档集合,但最优值还是会因为文档集不同而有所区别,为了找到文档集合的最优值,就必须对参数进行反复修改验证。
更改相似度
相似度算法可以按字段指定, 只需在映射中为不同字段选定即可:
PUT /my_index
{
"mappings": {
"doc": {
"properties": {
"title": {
"type": "string",
"similarity": "BM25" <1>
},
"body": {
"type": "string",
"similarity": "default" <2>
}
}
}
}
title字段使用 BM25 相似度算法。
body字段用默认相似度算法(参见 实用评分函数)。
目前,Elasticsearch 不支持更改已有字段的相似度算法 similarity 映射,只能通过为数据重新建立索引来达到目的。
配置 BM25
配置相似度算法和配置分析器很相似, 自定义相似度算法可以在创建索引时指定,例如:
PUT /my_index
{
"settings": {
"similarity": {
"my_bm25": { <1>
"type": "BM25",
"b": 0 <2>
}
}
},
"mappings": {
"doc": {
"properties": {
"title": {
"type": "string",
"similarity": "my_bm25" <3>
},
"body": {
"type": "string",
"similarity": "BM25" <4>
}
}
}
}
}
BM25,名为my_bm25的自定义相似度算法。
title字段使用自定义相似度算法my_bm25。
body使用内置相似度算法BM25。
调试相关度是最后 10% 要做的事情
本章介绍了 Lucene 是如何基于 TF/IDF 生成评分的。理解评分过程是非常重要的, 这样就可以根据具体的业务对评分结果进行调试、调节、减弱和定制。
实践中,简单的查询组合就能提供很好的搜索结果,但是为了获得 具有成效 的搜索结果,就必须反复推敲修改前面介绍的这些调试方法。
通常,经过对策略字段应用权重提升,或通过对查询语句结构的调整来强调某个句子的重要性这些方法,就足以获得良好的结果。有时,如果 Lucene 基于词的 TF/IDF 模型不再满足评分需求(例如希望基于时间或距离来评分),则需要更具侵略性的调整。
除此之外,相关度的调试就有如兔子洞,一旦跳进去就很难再出来。 最相关 这个概念是一个难以触及的模糊目标,通常不同人对文档排序又有着不同的想法,这很容易使人陷入持续反复调整而没有明显进展的怪圈。
我们强烈建议不要陷入这种怪圈,而要监控测量搜索结果。监控用户点击最顶端结果的频次,这可以是前 10 个文档,也可以是第一页的;用户不查看首次搜索的结果而直接执行第二次查询的频次;用户来回点击并查看搜索结果的频次,等等诸如此类的信息。
这些都是用来评价搜索结果与用户之间相关程度的指标。如果查询能返回高相关的文档,用户会选择前五中的一个,得到想要的结果,然后离开。不相关的结果会让用户来回点击并尝试新的搜索条件。
一旦有了这些监控手段,想要调试查询就并不复杂,稍作调整,监控用户的行为改变并做适当反复尝试。本章介绍的一些工具就只是工具而已,要想物尽其用并将搜索结果提高到 极高的 水平,唯一途径就是需要具备能评价度量用户行为的强大能力。