数据建模
Elasticsearch 是如此与众不同,特别是如果你来自 SQL 的世界。 Elasticsearch 有非常多的优点:高性能、可扩展、近实时搜索,并支持大数据量的数据分析。一切都很容易! 只需下载并开始使用它。
但它不是魔法。为了充分利用 Elasticsearch,你需要了解它的工作机制,以及如何让它如你所需的进行工作。
和专用的关系型数据存储有所不同,Elasticsearch 并没有对处理实体之间的关系给出直接的方法。 一个关系数据库的黄金法则是 --规范化你的数据(范式)-- 但这不适用于 Elasticsearch。 在 关联关系处理 、 嵌套对象 和 父-子关系文档 我们讨论了这些提供的方法的优点和缺点。
然后在 扩容设计 我们谈论 Elasticsearch 提供的快速、灵活的扩容能力。 当然扩容并没有一个放之四海而皆准的方案。你需要考虑这些通过系统产生的数据流的具体特点, 据此设计你的模型。例如日志事件或者社交网络流这些时间序列数据类型,和静态文档集合在处理模型上有着很大的不同。
最后,我们聊一下 Elasticsearch 里面不能伸缩的一件事。
关联关系处理
现实世界有很多重要的关联关系:博客帖子有一些评论,银行账户有多次交易记录,客户有多个银行账户,订单有多个订单明细,文件目录有多个文件和子目录。
关系型数据库被明确设计--毫不意外--用来进行关联关系管理 :
- 每个实体(或 行 ,在关系世界中)可以被 主键 唯一标识。
- 实体 规范化 (范式)。唯一实体的数据只存储一次,而相关实体只存储它的主键。只能在一个具体位置修改这个实体的数据。
- 实体可以进行关联查询,可以跨实体搜索。
- 单个实体的变化是 原子的 , 一致的 , 隔离的 , 和 持久的 。 (可以在 ACID Transactions 中查看更多细节。)
- 大多数关系数据库支持跨多个实体的 ACID 事务。
但是关系型数据库有其局限性,包括对全文检索有限的支持能力。 实体关联查询时间消耗是很昂贵的,关联的越多,消耗就越昂贵。特别是跨服务器进行实体关联时成本极其昂贵,基本不可用。 但单个的服务器上又存在数据量的限制。
Elasticsearch ,和大多数 NoSQL 数据库类似,是扁平化的。索引是独立文档的集合体。 文档是否匹配搜索请求取决于它是否包含所有的所需信息。
Elasticsearch 中单个文档的数据变更是 ACIDic 的, 而涉及多个文档的事务则不是。当一个事务部分失败时,无法回滚索引数据到前一个状态。
扁平化有以下优势:
- 索引过程是快速和无锁的。
- 搜索过程是快速和无锁的。
- 因为每个文档相互都是独立的,大规模数据可以在多个节点上进行分布。
但关联关系仍然非常重要。某些时候,我们需要缩小扁平化和现实世界关系模型的差异。 以下四种常用的方法,用来在 Elasticsearch 中进行关系型数据的管理:
通常都需要结合其中的某几个方法来得到最终的解决方案。
应用层联接
我们通过在我们的应用程序中实现联接可以(部分)模拟关系 数据库。 例如,比方说我们正在对用户和他们的博客文章进行索引。在关系世界中,我们会这样来操作:
PUT /my_index/user/1 <1>
{
"name": "John Smith",
"email": "john@smith.com",
"dob": "1970/10/24"
}
PUT /my_index/blogpost/2 <2>
{
"title": "Relationships",
"body": "It's complicated...",
"user": 1 <3>
}
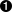
每个文档的
index,type, 和id一起构造成主键。

blogpost通过用户的id链接到用户。index和type并不需要因为在我们的应用程序中已经硬编码。
通过用户的 ID 1 可以很容易的找到博客帖子。
GET /my_index/blogpost/_search
{
"query": {
"filtered": {
"filter": {
"term": { "user": 1 }
}
}
}
}
为了找到用户叫做 John 的博客帖子,我们需要运行两次查询: 第一次会查找所有叫做 John 的用户从而获取他们的 ID 集合,接着第二次会将这些 ID 集合放到类似于前面一个例子的查询:
GET /my_index/user/_search
{
"query": {
"match": {
"name": "John"
}
}
}
GET /my_index/blogpost/_search
{
"query": {
"filtered": {
"filter": {
"terms": { "user": [1] } <1>
}
}
}
}
terms过滤器中。
应用层联接的主要优点是可以对数据进行标准化处理。只能在 user 文档中修改用户的名称。缺点是,为了在搜索时联接文档,必须运行额外的查询。
在这个例子中,只有一个用户匹配我们的第一个查询,但在现实世界中,我们可以很轻易的遇到数以百万计的叫做 John 的用户。 包含所有这些用户的 IDs 会产生一个非常大的查询,这是一个数百万词项的查找。
这种方法适用于第一个实体(例如,在这个例子中 user )只有少量的文档记录的情况,并且最好它们很少改变。这将允许应用程序对结果进行缓存,并避免经常运行第一次查询。
非规范化你的数据
使用 Elasticsearch 得到最好的搜索性能的方法是有目的的通过在索引时进行非规范化 denormalizing。对每个文档保持一定数量的冗余副本可以在需要访问时避免进行关联。
如果我们希望能够通过某个用户姓名找到他写的博客文章,可以在博客文档中包含这个用户的姓名:
PUT /my_index/user/1
{
"name": "John Smith",
"email": "john@smith.com",
"dob": "1970/10/24"
}
PUT /my_index/blogpost/2
{
"title": "Relationships",
"body": "It's complicated...",
"user": {
"id": 1,
"name": "John Smith" <1>
}
}
blogpost文档中。
现在,我们通过单次查询就能够通过 relationships 找到用户 John 的博客文章。
GET /my_index/blogpost/_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "relationships" }},
{ "match": { "user.name": "John" }}
]
}
}
}
数据非规范化的优点是速度快。因为每个文档都包含了所需的所有信息,当这些信息需要在查询进行匹配时,并不需要进行昂贵的联接操作。
字段折叠
一个普遍的需求是需要通过特定字段进行分组。 例如我们需要按照用户名称 分组 返回最相关的博客文章。按照用户名分组意味着进行 terms 聚合。 为能够按照用户 整体 名称进行分组,名称字段应保持 not_analyzed 的形式, 具体说明参考 聚合与分析:
PUT /my_index/_mapping/blogpost
{
"properties": {
"user": {
"properties": {
"name": { <1>
"type": "string",
"fields": {
"raw": { <2>
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
}
}
user.name字段将用来进行全文检索。
user.name.raw字段将用来通过terms聚合进行分组。
然后添加一些数据:
PUT /my_index/user/1
{
"name": "John Smith",
"email": "john@smith.com",
"dob": "1970/10/24"
}
PUT /my_index/blogpost/2
{
"title": "Relationships",
"body": "It's complicated...",
"user": {
"id": 1,
"name": "John Smith"
}
}
PUT /my_index/user/3
{
"name": "Alice John",
"email": "alice@john.com",
"dob": "1979/01/04"
}
PUT /my_index/blogpost/4
{
"title": "Relationships are cool",
"body": "It's not complicated at all...",
"user": {
"id": 3,
"name": "Alice John"
}
}
现在我们来查询标题包含 relationships 并且作者名包含 John 的博客,查询结果再按作者名分组,感谢 top_hits aggregation 提供了按照用户进行分组的功能:
GET /my_index/blogpost/_search
{
"size" : 0, <1>
"query": { <2>
"bool": {
"must": [
{ "match": { "title": "relationships" }},
{ "match": { "user.name": "John" }}
]
}
},
"aggs": {
"users": {
"terms": {
"field": "user.name.raw", <3>
"order": { "top_score": "desc" } <4>
},
"aggs": {
"top_score": { "max": { "script": "_score" }}, <5>
"blogposts": { "top_hits": { "_source": "title", "size": 5 }} <6>
}
}
}
}
blogposts聚合返回的,所以我们可以通过将size设置成 0 来禁止hits常规搜索。
query返回通过relationships查找名称为John的用户的博客文章。
terms聚合为每一个user.name.raw创建一个桶。

top_score聚合对通过users聚合得到的每一个桶按照文档评分对词项进行排序。

top_hits聚合仅为每个用户返回五个最相关的博客文章的title字段。
这里显示简短响应结果:
...
"hits": {
"total": 2,
"max_score": 0,
"hits": [] <1>
},
"aggregations": {
"users": {
"buckets": [
{
"key": "John Smith", <2>
"doc_count": 1,
"blogposts": {
"hits": { <3>
"total": 1,
"max_score": 0.35258877,
"hits": [
{
"_index": "my_index",
"_type": "blogpost",
"_id": "2",
"_score": 0.35258877,
"_source": {
"title": "Relationships"
}
}
]
}
},
"top_score": { <4>
"value": 0.3525887727737427
}
},
...
size为 0 ,所以hits数组是空的。
blogposts.hits数组包含针对这个用户的顶层查询结果。
用户桶按照每个用户最相关的博客文章进行排序。
使用 top_hits 聚合等效执行一个查询返回这些用户的名字和他们最相关的博客文章,然后为每一个用户执行相同的查询,以获得最好的博客。但前者的效率要好很多。
每一个桶返回的顶层查询命中结果是基于最初主查询进行的一个轻量 迷你查询 结果集。这个迷你查询提供了一些你期望的常用特性,例如高亮显示以及分页功能。
非规范化和并发
当然,数据非规范化也有弊端。 第一个缺点是索引会更大因为每个博客文章文档的 _source 将会更大,并且这里有很多的索引字段。这通常不是一个大问题。数据写到磁盘将会被高度压缩,而且磁盘已经很廉价了。Elasticsearch 可以愉快地应付这些额外的数据。
更重要的问题是,如果用户改变了他的名字,他所有的博客文章也需要更新了。幸运的是,用户不经常更改名称。即使他们做了, 用户也不可能写超过几千篇博客文章,所以更新博客文章通过 scroll 和 bulkAPIs 大概耗费不到一秒。
然而,让我们考虑一个更复杂的场景,其中的变化很常见,影响深远,而且非常重要,并发。
在这个例子中,我们将在 Elasticsearch 模拟一个文件系统的目录树,非常类似 Linux 文件系统:根目录是 / ,每个目录可以包含文件和子目录。
我们希望能够搜索到一个特定目录下的文件,等效于:
grep "some text" /clinton/projects/elasticsearch/*
这就要求我们索引文件所在目录的路径:
PUT /fs/file/1
{
"name": "README.txt", <1>
"path": "/clinton/projects/elasticsearch",
"contents": "Starting a new Elasticsearch project is easy..." <2>
}
事实上,我们也应当索引
directory文档,如此我们可以在目录内列出所有的文件和子目录,但为了简洁,我们将忽略这个需求。
我们也希望能够搜索到一个特定目录下的目录树包含的的任何文件,相当于此:
grep -r "some text" /clinton
为了支持这一点,我们需要对路径层次结构进行索引:
/clinton/clinton/projects/clinton/projects/elasticsearch
这种层次结构能够通过 path 字段使用 path_hierarchy tokenizer 自动生成:
PUT /fs
{
"settings": {
"analysis": {
"analyzer": {
"paths": { <1>
"tokenizer": "path_hierarchy"
}
}
}
}
}
paths分析器在默认设置中使用path_hierarchytokenizer。
file 类型的映射看起来如下所示:
PUT /fs/_mapping/file
{
"properties": {
"name": { <1>
"type": "string",
"index": "not_analyzed"
},
"path": { <2>
"type": "string",
"index": "not_analyzed",
"fields": {
"tree": { <3>
"type": "string",
"analyzer": "paths"
}
}
}
}
}
name字段将包含确切名称。
path字段将包含确切的目录名称,而path.tree字段将包含路径层次结构。
一旦索引建立并且文件已被编入索引,我们可以执行一个搜索,在 /clinton/projects/elasticsearch 目录中包含 elasticsearch 的文件,如下所示:
GET /fs/file/_search
{
"query": {
"filtered": {
"query": {
"match": {
"contents": "elasticsearch"
}
},
"filter": {
"term": { <1>
"path": "/clinton/projects/elasticsearch"
}
}
}
}
}
所有在 /clinton 下面的任何子目录存放的文件将在 path.tree 字段中包含 /clinton 词项。所以我们能够搜索 /clinton 的任何子目录中的所有文件,如下所示:
GET /fs/file/_search
{
"query": {
"filtered": {
"query": {
"match": {
"contents": "elasticsearch"
}
},
"filter": {
"term": { <1>
"path.tree": "/clinton"
}
}
}
}
}
重命名文件和目录
到目前为止一切顺利。 重命名一个文件很容易--所需要的只是一个简单的 update 或 index 请求。 你甚至可以使用 optimistic concurrency control 确保你的变化不会与其他用户的变化发生冲突:
PUT /fs/file/1?version=2 <1>
{
"name": "README.asciidoc",
"path": "/clinton/projects/elasticsearch",
"contents": "Starting a new Elasticsearch project is easy..."
}
version编号确保该更改仅应用于该索引中具有此相同的版本号的文档。
我们甚至可以重命名一个目录,但这意味着更新所有存在于该目录下路径层次结构中的所有文件。 这可能快速或缓慢,取决于有多少文件需要更新。我们所需要做的就是使用 scroll 来检索所有的文件, 以及 bulk API 来更新它们。这个过程不是原子的,但是所有的文件将会迅速转移到他们的新存放位置。
解决并发问题
当我们允许多个人 同时 重命名文件或目录时,问题就来了。 设想一下,你正在对一个包含了成百上千文件的目录 /clinton 进行重命名操作。 同时,另一个用户对这个目录下的单个文件 /clinton/projects/elasticsearch/README.txt 进行重命名操作。 这个用户的修改操作,尽管在你的操作后开始,但可能会更快的完成。
以下有两种情况可能出现:
- 你决定使用
version(版本)号,在这种情况下,当与README.txt文件重命名的版本号产生冲突时,你的批量重命名操作将会失败。 - 你没有使用版本控制,你的变更将覆盖其他用户的变更。
问题的原因是 Elasticsearch 不支持 ACID 事务。 对单个文件的变更是 ACIDic 的,但包含多个文档的变更不支持。
如果你的主要数据存储是关系数据库,并且 Elasticsearch 仅仅作为一个搜索引擎 或一种提升性能的方法,可以首先在数据库中执行变更动作,然后在完成后将这些变更复制到 Elasticsearch。 通过这种方式,你将受益于数据库 ACID 事务支持,并且在 Elasticsearch 中以正确的顺序产生变更。 并发在关系数据库中得到了处理。
如果你不使用关系型存储,这些并发问题就需要在 Elasticsearch 的事务水准进行处理。 以下是三个切实可行的使用 Elasticsearch 的解决方案,它们都涉及某种形式的锁:
- 全局锁
- 文档锁
- 树锁
当使用一个外部系统替代 Elasticsearch 时,本节中所描述的解决方案可以通过相同的原则来实现。
全局锁
通过在任何时间只允许一个进程来进行变更动作,我们可以完全避免并发问题。 大多数的变更只涉及少量文件,会很快完成。一个顶级目录的重命名操作会对其他变更造成较长时间的阻塞,但可能很少这样做。
因为在 Elasticsearch 文档级别的变更支持 ACIDic,我们可以使用一个文档是否存在的状态作为一个全局锁。 为了请求得到锁,我们尝试 create 全局锁文档:
PUT /fs/lock/global/_create
{}
如果这个 create 请求因冲突异常而失败,说明另一个进程已被授予全局锁,我们将不得不稍后再试。 如果请求成功了,我们自豪的成为全局锁的主人,然后可以继续完成我们的变更。一旦完成,我们就必须通过删除全局锁文档来释放锁:
DELETE /fs/lock/global
根据变更的频繁程度以及时间消耗,一个全局锁能对系统造成大幅度的性能限制。 我们可以通过让我们的锁更细粒度的方式来增加并行度。
文档锁
我们可以使用前面描述相同的方法技术来锁定个体文档,而不是锁定整个文件系统。 我们可以使用 scrolled search 检索所有的文档,这些文档会被变更影响因此每一个文档都创建了一个锁文件:
PUT /fs/lock/_bulk
{ "create": { "_id": 1}} <1>
{ "process_id": 123 } <2>
{ "create": { "_id": 2}}
{ "process_id": 123 }
lock文档的 ID 将与应被锁定的文件的 ID 相同。
process_id代表要执行变更进程的唯一 ID。
如果一些文件已被锁定,部分的 bulk 请求将失败,我们将不得不再次尝试。
当然,如果我们试图再次锁定 所有 的文件, 我们前面使用的 create 语句将会失败,因为所有文件都已被我们锁定! 我们需要一个 update 请求带 upsert 参数以及下面这个 script ,而不是一个简单的 create语句:
if ( ctx._source.process_id != process_id ) { <1>
assert false; <2>
}
ctx.op = 'noop'; <3>
process_id是传递到脚本的一个参数。
assert false将引发异常,导致更新失败。
op从update更新到noop防止更新请求作出任何改变,但仍返回成功。
完整的 update 请求如下所示:
POST /fs/lock/1/_update
{
"upsert": { "process_id": 123 },
"script": "if ( ctx._source.process_id != process_id )
{ assert false }; ctx.op = 'noop';"
"params": {
"process_id": 123
}
}
如果文档并不存在, upsert 文档将会被插入--和前面 create 请求相同。 但是,如果该文件 确实 存在,该脚本会查看存储在文档上的 process_id 。 如果 process_id 匹配,更新不会执行( noop )但脚本会返回成功。 如果两者并不匹配, assert false 抛出一个异常,你也知道了获取锁的尝试已经失败。
一旦所有锁已成功创建,你就可以继续进行你的变更。
之后,你必须释放所有的锁,通过检索所有的锁文档并进行批量删除,可以完成锁的释放:
POST /fs/_refresh <1>
GET /fs/lock/_search?scroll=1m <2>
{
"sort" : ["_doc"],
"query": {
"match" : {
"process_id" : 123
}
}
}
PUT /fs/lock/_bulk
{ "delete": { "_id": 1}}
{ "delete": { "_id": 2}}
refresh调用确保所有lock文档对搜索请求可见。
scroll查询。
文档级锁可以实现细粒度的访问控制,但是为数百万文档创建锁文件开销也很大。 在某些情况下,你可以用少得多的工作量实现细粒度的锁定,如以下目录树场景中所示。
树锁
在前面的例子中,我们可以锁定的目录树的一部分,而不是锁定每一个涉及的文档。 我们将需要独占访问我们要重命名的文件或目录,它可以通过 独占锁 文档来实现:
{ "lock_type": "exclusive" }
同时我们需要共享锁定所有的父目录,通过 共享锁 文档:
{
"lock_type": "shared",
"lock_count": 1 <1>
}
lock_count记录持有共享锁进程的数量。
对 /clinton/projects/elasticsearch/README.txt 进行重命名的进程需要在这个文件上有 独占锁 , 以及在 /clinton 、 /clinton/projects 和 /clinton/projects/elasticsearch 目录有 共享锁 。
一个简单的 create 请求将满足独占锁的要求,但共享锁需要脚本的更新来实现一些额外的逻辑:
if (ctx._source.lock_type == 'exclusive') {
assert false; <1>
}
ctx._source.lock_count++ <2>
lock_type是exclusive(独占)的,assert语句将抛出一个异常,导致更新请求失败。
lock_count进行增量处理。
这个脚本处理了 lock 文档已经存在的情况,但我们还需要一个用来处理的文档还不存在情况的 upsert 文档。 完整的更新请求如下:
POST /fs/lock/%2Fclinton/_update <1>
{
"upsert": { <2>
"lock_type": "shared",
"lock_count": 1
},
"script": "if (ctx._source.lock_type == 'exclusive')
{ assert false }; ctx._source.lock_count++"
}
/clinton,经过URL编码后成为%2fclinton。
upsert文档如果不存在,则会被插入。
一旦我们成功地在所有的父目录中获得一个共享锁,我们尝试在文件本身 create 一个独占锁:
PUT /fs/lock/%2Fclinton%2fprojects%2felasticsearch%2fREADME.txt/_create
{ "lock_type": "exclusive" }
现在,如果有其他人想要重新命名 /clinton 目录,他们将不得不在这条路径上获得一个独占锁:
PUT /fs/lock/%2Fclinton/_create
{ "lock_type": "exclusive" }
这个请求将失败,因为一个具有相同 ID 的 lock 文档已经存在。 另一个用户将不得不等待我们的操作完成以及释放我们的锁。独占锁只能这样被删除:
DELETE /fs/lock/%2Fclinton%2fprojects%2felasticsearch%2fREADME.txt
共享锁需要另一个脚本对 lock_count 递减,如果计数下降到零,删除 lock 文档:
if (--ctx._source.lock_count == 0) {
ctx.op = 'delete' <1>
}
lock_count达到0,ctx.op会从update被修改成delete。
此更新请求将为每级父目录由下至上的执行,从最长路径到最短路径:
POST /fs/lock/%2Fclinton%2fprojects%2felasticsearch/_update
{
"script": "if (--ctx._source.lock_count == 0) { ctx.op = 'delete' } "
}
树锁用最小的代价提供了细粒度的并发控制。当然,它不适用于所有的情况--数据模型必须有类似于目录树的顺序访问路径才能使用。
一个进程的意外死亡给我们留下了2个问题:
- 我们如何知道我们可以释放的死亡进程中所持有的锁?
我们如何清理死去的进程没有完成的变更?
这些主题超出了本书的范围,但是如果你决定使用锁,你需要给对他们进行一些思考。
当非规范化成为很多项目的一个很好的选择,采用锁方案的需求会带来复杂的实现逻辑。 作为替代方案,Elasticsearch 提供两个模型帮助我们处理相关联的实体: 嵌套的对象 和 父子关系 。
嵌套对象
由于在 Elasticsearch 中单个文档的增删改都是原子性操作,那么将相关实体数据都存储在同一文档中也就理所当然。 比如说,我们可以将订单及其明细数据存储在一个文档中。又比如,我们可以将一篇博客文章的评论以一个 comments 数组的形式和博客文章放在一起:
PUT /my_index/blogpost/1
{
"title": "Nest eggs",
"body": "Making your money work...",
"tags": [ "cash", "shares" ],
"comments": [ <1>
{
"name": "John Smith",
"comment": "Great article",
"age": 28,
"stars": 4,
"date": "2014-09-01"
},
{
"name": "Alice White",
"comment": "More like this please",
"age": 31,
"stars": 5,
"date": "2014-10-22"
}
]
}
comments字段会自动映射为object类型。
由于所有的信息都在一个文档中,当我们查询时就没有必要去联合文章和评论文档,查询效率就很高。
但是当我们使用如下查询时,上面的文档也会被当做是符合条件的结果:
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "Alice" }},
{ "match": { "age": 28 }} <1>
]
}
}
}
正如我们在 对象数组 中讨论的一样,出现上面这种问题的原因是 JSON 格式的文档被处理成如下的扁平式键值对的结构。
{
"title": [ eggs, nest ],
"body": [ making, money, work, your ],
"tags": [ cash, shares ],
"comments.name": [ alice, john, smith, white ],
"comments.comment": [ article, great, like, more, please, this ],
"comments.age": [ 28, 31 ],
"comments.stars": [ 4, 5 ],
"comments.date": [ 2014-09-01, 2014-10-22 ]
}
Alice 和 31 、 John 和 2014-09-01 之间的相关性信息不再存在。虽然 object 类型 (参见 内部对象) 在存储 单一对象 时非常有用,但对于对象数组的搜索而言,毫无用处。
嵌套对象 就是来解决这个问题的。将 comments 字段类型设置为 nested 而不是 object 后,每一个嵌套对象都会被索引为一个 隐藏的独立文档 ,举例如下:
{ <1>
"comments.name": [ john, smith ],
"comments.comment": [ article, great ],
"comments.age": [ 28 ],
"comments.stars": [ 4 ],
"comments.date": [ 2014-09-01 ]
}
{ <2>
"comments.name": [ alice, white ],
"comments.comment": [ like, more, please, this ],
"comments.age": [ 31 ],
"comments.stars": [ 5 ],
"comments.date": [ 2014-10-22 ]
}
{ <3>
"title": [ eggs, nest ],
"body": [ making, money, work, your ],
"tags": [ cash, shares ]
}
嵌套文档
嵌套文档
在独立索引每一个嵌套对象后,对象中每个字段的相关性得以保留。我们查询时,也仅仅返回那些真正符合条件的文档。
不仅如此,由于嵌套文档直接存储在文档内部,查询时嵌套文档和根文档联合成本很低,速度和单独存储几乎一样。
嵌套文档是隐藏存储的,我们不能直接获取。如果要增删改一个嵌套对象,我们必须把整个文档重新索引才可以。值得注意的是,查询的时候返回的是整个文档,而不是嵌套文档本身。
嵌套对象映射
设置一个字段为 nested 很简单 — 你只需要将字段类型 object 替换为 nested 即可:
PUT /my_index
{
"mappings": {
"blogpost": {
"properties": {
"comments": {
"type": "nested", <1>
"properties": {
"name": { "type": "string" },
"comment": { "type": "string" },
"age": { "type": "short" },
"stars": { "type": "short" },
"date": { "type": "date" }
}
}
}
}
}
}
nested字段类型的设置参数与object相同。
这就是需要设置的一切。至此,所有 comments 对象会被索引在独立的嵌套文档中。可以查看 nested 类型参考文档 获取更多详细信息。
嵌套对象查询
由于嵌套对象 被索引在独立隐藏的文档中,我们无法直接查询它们。 相应地,我们必须使用 nested 查询去获取它们:
GET /my_index/blogpost/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "eggs" <1>
}
},
{
"nested": {
"path": "comments", <2>
"query": {
"bool": {
"must": [ <3>
{
"match": {
"comments.name": "john"
}
},
{
"match": {
"comments.age": 28
}
}
]
}
}
}
}
]
}}}
title子句是查询根文档的。
nested子句作用于嵌套字段comments。在此查询中,既不能查询根文档字段,也不能查询其他嵌套文档。
comments.name和comments.age子句操作在同一个嵌套文档中。
nested字段可以包含其他的nested字段。同样地,nested查询也可以包含其他的nested查询。而嵌套的层次会按照你所期待的被应用。
nested 查询肯定可以匹配到多个嵌套的文档。每一个匹配的嵌套文档都有自己的相关度得分,但是这众多的分数最终需要汇聚为可供根文档使用的一个分数。
默认情况下,根文档的分数是这些嵌套文档分数的平均值。可以通过设置 score_mode 参数来控制这个得分策略,相关策略有 avg (平均值), max (最大值), sum (加和) 和 none (直接返回 1.0 常数值分数)。
GET /my_index/blogpost/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "eggs"
}
},
{
"nested": {
"path": "comments",
"score_mode": "max", <1>
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "john"
}
},
{
"match": {
"comments.age": 28
}
}
]
}
}
}
}
]
}
}
}
_score给根文档使用。
nested查询放在一个布尔查询的filter子句中,其表现就像一个nested查询,只是score_mode参数不再生效。因为它被用于不打分的查询中 — 只是符合或不符合条件,不必打分 — 那么score_mode就没有任何意义,因为根本就没有要打分的地方。
使用嵌套字段排序
尽管嵌套字段的值存储于独立的嵌套文档中,但依然有方法按照嵌套字段的值排序。 让我们添加另一个记录,以使得结果更有意思:
PUT /my_index/blogpost/2
{
"title": "Investment secrets",
"body": "What they don't tell you ...",
"tags": [ "shares", "equities" ],
"comments": [
{
"name": "Mary Brown",
"comment": "Lies, lies, lies",
"age": 42,
"stars": 1,
"date": "2014-10-18"
},
{
"name": "John Smith",
"comment": "You're making it up!",
"age": 28,
"stars": 2,
"date": "2014-10-16"
}
]
}
假如我们想要查询在10月份收到评论的博客文章,并且按照 stars 数的最小值来由小到大排序,那么查询语句如下:
GET /_search
{
"query": {
"nested": { <1>
"path": "comments",
"filter": {
"range": {
"comments.date": {
"gte": "2014-10-01",
"lt": "2014-11-01"
}
}
}
}
},
"sort": {
"comments.stars": { <2>
"order": "asc", <3>
"mode": "min", <4>
"nested_path": "comments", <5>
"nested_filter": {
"range": {
"comments.date": {
"gte": "2014-10-01",
"lt": "2014-11-01"
}
}
}
}
}
}
nested查询将结果限定为在10月份收到过评论的博客文章。
comment.stars字段的最小值 (min) 来由小到大 (asc) 排序。
nested_path和nested_filter和query子句中的nested查询相同,原因在下面有解释。
我们为什么要用 nested_path 和 nested_filter 重复查询条件呢?原因在于,排序发生在查询执行之后。 查询条件限定了在10月份收到评论的博客文档,但返回的是博客文档。如果我们不在排序子句中加入 nested_filter , 那么我们对博客文档的排序将基于博客文档的所有评论,而不是仅仅在10月份接收到的评论。
嵌套聚合
在查询的时候,我们使用 nested 查询 就可以获取嵌套对象的信息。同理, nested 聚合允许我们对嵌套对象里的字段进行聚合操作。
GET /my_index/blogpost/_search
{
"size" : 0,
"aggs": {
"comments": { <1>
"nested": {
"path": "comments"
},
"aggs": {
"by_month": {
"date_histogram": { <2>
"field": "comments.date",
"interval": "month",
"format": "yyyy-MM"
},
"aggs": { <3>
"avg_stars": {
"avg": {
"field": "comments.stars"
}
}
}
}
}
}
}
}
nested聚合 “进入” 嵌套的comments对象。
从下面的结果可以看出聚合是在嵌套文档层面进行的:
...
"aggregations": {
"comments": {
"doc_count": 4, <1>
"by_month": {
"buckets": [
{
"key_as_string": "2014-09",
"key": 1409529600000,
"doc_count": 1, <2>
"avg_stars": {
"value": 4
}
},
{
"key_as_string": "2014-10",
"key": 1412121600000,
"doc_count": 3, <3>
"avg_stars": {
"value": 2.6666666666666665
}
}
]
}
}
}
...
comments对象 :1个对象在9月的桶里,3个对象在10月的桶里。
逆向嵌套聚合
nested 聚合 只能对嵌套文档的字段进行操作。 根文档或者其他嵌套文档的字段对它是不可见的。 然而,通过 reverse_nested 聚合,我们可以 走出 嵌套层级,回到父级文档进行操作。
例如,我们要基于评论者的年龄找出评论者感兴趣 tags 的分布。 comment.age 是一个嵌套字段,但 tags在根文档中:
GET /my_index/blogpost/_search
{
"size" : 0,
"aggs": {
"comments": {
"nested": { <1>
"path": "comments"
},
"aggs": {
"age_group": {
"histogram": { <2>
"field": "comments.age",
"interval": 10
},
"aggs": {
"blogposts": {
"reverse_nested": {}, <3>
"aggs": {
"tags": {
"terms": { <4>
"field": "tags"
}
}
}
}
}
}
}
}
}
}
nested聚合进入comments对象。
histogram聚合基于comments.age做分组,每10年一个分组。
reverse_nested聚合退回根文档。
terms聚合计算每个分组年龄段的评论者最常用的标签词。
简略结果如下所示:
..
"aggregations": {
"comments": {
"doc_count": 4, <1>
"age_group": {
"buckets": [
{
"key": 20, <2>
"doc_count": 2, <3>
"blogposts": {
"doc_count": 2, <4>
"tags": {
"doc_count_error_upper_bound": 0,
"buckets": [ <5>
{ "key": "shares", "doc_count": 2 },
{ "key": "cash", "doc_count": 1 },
{ "key": "equities", "doc_count": 1 }
]
}
}
},
...
shares、cash、equities。
嵌套对象的使用时机
嵌套对象 在只有一个主要实体时非常有用,这个主要实体包含有限个紧密关联但又不是很重要的实体,例如我们的 blogpost 对象包含评论对象。 在基于评论的内容查找博客文章时, nested 查询有很大的用处,并且可以提供更快的查询效率。
嵌套模型的缺点如下:
- 当对嵌套文档做增加、修改或者删除时,整个文档都要重新被索引。嵌套文档越多,这带来的成本就越大。
- 查询结果返回的是整个文档,而不仅仅是匹配的嵌套文档。尽管目前有计划支持只返回根文档中最佳匹配的嵌套文档,但目前还不支持。
有时你需要在主文档和其关联实体之间做一个完整的隔离设计。这个隔离是由 父子关联 提供的。
父-子关系文档
父-子关系文档 在实质上类似于 nested model :允许将一个对象实体和另外一个对象实体关联起来。 而这两种类型的主要区别是:在 nested objects 文档中,所有对象都是在同一个文档中,而在父-子关系文档中,父对象和子对象都是完全独立的文档。
父-子关系的主要作用是允许把一个 type 的文档和另外一个 type 的文档关联起来,构成一对多的关系:一个父文档可以对应多个子文档 。与 nested objects 相比,父-子关系的主要优势有:
- 更新父文档时,不会重新索引子文档。
- 创建,修改或删除子文档时,不会影响父文档或其他子文档。这一点在这种场景下尤其有用:子文档数量较多,并且子文档创建和修改的频率高时。
- 子文档可以作为搜索结果独立返回。
Elasticsearch 维护了一个父文档和子文档的映射关系,得益于这个映射,父-子文档关联查询操作非常快。但是这个映射也对父-子文档关系有个限制条件:父文档和其所有子文档,都必须要存储在同一个分片中。
父-子文档ID映射存储在 Doc Values 中。当映射完全在内存中时, Doc Values 提供对映射的快速处理能力,另一方面当映射非常大时,可以通过溢出到磁盘提供足够的扩展能力
父-子关系文档映射
建立父-子文档映射关系时只需要指定某一个文档 type 是另一个文档 type 的父亲。 该关系可以在如下两个时间点设置:1)创建索引时;2)在子文档 type 创建之前更新父文档的 mapping。
举例说明,有一个公司在多个城市有分公司,并且每一个分公司下面都有很多员工。有这样的需求:按照分公司、员工的维度去搜索,并且把员工和他们工作的分公司联系起来。针对该需求,用嵌套模型是无法实现的。当然,如果使用 application-side-joins 或者 data denormalization 也是可以实现的,但是为了演示的目的,在这里我们使用父-子文档。
我们需要告诉Elasticsearch,在创建员工 employee 文档 type 时,指定分公司 branch 的文档 type 为其父亲。
PUT /company
{
"mappings": {
"branch": {},
"employee": {
"_parent": {
"type": "branch" <1>
}
}
}
}
employee文档 是branch文档的子文档。
构建父-子文档索引
为父文档创建索引与为普通文档创建索引没有区别。父文档并不需要知道它有哪些子文档。
POST /company/branch/_bulk
{ "index": { "_id": "london" }}
{ "name": "London Westminster", "city": "London", "country": "UK" }
{ "index": { "_id": "liverpool" }}
{ "name": "Liverpool Central", "city": "Liverpool", "country": "UK" }
{ "index": { "_id": "paris" }}
{ "name": "Champs Élysées", "city": "Paris", "country": "France" }
创建子文档时,用户必须要通过 parent 参数来指定该子文档的父文档 ID:
PUT /company/employee/1?parent=london <1>
{
"name": "Alice Smith",
"dob": "1970-10-24",
"hobby": "hiking"
}
employee文档的父文档 ID 是london。
父文档 ID 有两个作用:创建了父文档和子文档之间的关系,并且保证了父文档和子文档都在同一个分片上。
在 路由一个文档到一个分片中 中,我们解释了 Elasticsearch 如何通过路由值来决定该文档属于哪一个分片,路由值默认为该文档的 _id 。分片路由的计算公式如下:
shard = hash(routing) % number_of_primary_shards
如果指定了父文档的 ID,那么就会使用父文档的 ID 进行路由,而不会使用当前文档 _id 。也就是说,如果父文档和子文档都使用相同的值进行路由,那么父文档和子文档都会确定分布在同一个分片上。
在执行单文档的请求时需要指定父文档的 ID,单文档请求包括:通过 GET 请求获取一个子文档;创建、更新或删除一个子文档。而执行搜索请求时是不需要指定父文档的ID,这是因为搜索请求是向一个索引中的所有分片发起请求,而单文档的操作是只会向存储该文档的分片发送请求。因此,如果操作单个子文档时不指定父文档的 ID,那么很有可能会把请求发送到错误的分片上。
父文档的 ID 应该在 bulk API 中指定
POST /company/employee/_bulk
{ "index": { "_id": 2, "parent": "london" }}
{ "name": "Mark Thomas", "dob": "1982-05-16", "hobby": "diving" }
{ "index": { "_id": 3, "parent": "liverpool" }}
{ "name": "Barry Smith", "dob": "1979-04-01", "hobby": "hiking" }
{ "index": { "_id": 4, "parent": "paris" }}
{ "name": "Adrien Grand", "dob": "1987-05-11", "hobby": "horses" }
如果你想要改变一个子文档的
parent值,仅通过更新这个子文档是不够的,因为新的父文档有可能在另外一个分片上。因此,你必须要先把子文档删除,然后再重新索引这个子文档。
通过子文档查询父文档
has_child 的查询和过滤可以通过子文档的内容来查询父文档。 例如,我们根据如下查询,可查出所有80后员工所在的分公司:
GET /company/branch/_search
{
"query": {
"has_child": {
"type": "employee",
"query": {
"range": {
"dob": {
"gte": "1980-01-01"
}
}
}
}
}
}
类似于 nested query ,has_child 查询可以匹配多个子文档 ,并且每一个子文档的评分都不同。但是由于每一个子文档都带有评分,这些评分如何规约成父文档的总得分取决于 score_mode 这个参数。该参数有多种取值策略:默认为 none ,会忽略子文档的评分,并且会给父文档评分设置为 1.0 ; 除此以外还可以设置成 avg 、 min 、 max 和 sum 。
下面的查询将会同时返回 london 和 liverpool ,不过由于 Alice Smith 要比 Barry Smith 更加匹配查询条件,因此 london 会得到一个更高的评分。
GET /company/branch/_search
{
"query": {
"has_child": {
"type": "employee",
"score_mode": "max",
"query": {
"match": {
"name": "Alice Smith"
}
}
}
}
}

score_mode 为默认的 none 时,会显著地比其模式要快,这是因为Elasticsearch不需要计算每一个子文档的评分。只有当你真正需要关心评分结果时,才需要为 score_mode 设值,例如设成 avg 、 min 、 max 或 sum 。
min_children 和 max_children
has_child 的查询和过滤都可以接受这两个参数:min_children 和 max_children 。 使用这两个参数时,只有当子文档数量在指定范围内时,才会返回父文档。
如下查询只会返回至少有两个雇员的分公司:
GET /company/branch/_search
{
"query": {
"has_child": {
"type": "employee",
"min_children": 2, <1>
"query": {
"match_all": {}
}
}
}
}
至少有两个雇员的分公司才会符合查询条件。
带有 min_children 和 max_children 参数的 has_child 查询或过滤,和允许评分的 has_child 查询的性能非常接近。
>
has_child Filter
has_child查询和过滤在运行机制上类似, 区别是has_child过滤不支持score_mode参数。has_child过滤仅用于筛选内容--如内部的一个filtered查询--和其他过滤行为类似:包含或者排除,但没有进行评分。has_child 过滤的结果没有被缓存,但是 has_child 过滤内部的过滤方法适用于通常的缓存规则。
通过父文档查询子文档
虽然 nested 查询只能返回最顶层的文档 ,但是父文档和子文档本身是彼此独立并且可被单独查询的。我们使用 has_child 语句可以基于子文档来查询父文档,使用 has_parent 语句可以基于父文档来查询子文档。
has_parent 和 has_child 非常相似,下面的查询将会返回所有在 UK 工作的雇员:
GET /company/employee/_search
{
"query": {
"has_parent": {
"type": "branch", <1>
"query": {
"match": {
"country": "UK"
}
}
}
}
}
type是branch的所有子文档
has_parent 查询也支持 score_mode 这个参数,但是该参数只支持两种值: none (默认)和 score 。每个子文档都只有一个父文档,因此这里不存在将多个评分规约为一个的情况, score_mode 的取值仅为 score 和 none 。
不带评分的 has_parent 查询
当
has_parent查询用于非评分模式(比如 filter 查询语句)时,score_mode参数就不再起作用了。因为这种模式只是简单地包含或排除文档,没有评分,那么score_mode参数也就没有意义了。
子文档聚合
在父-子文档中支持 子文档聚合,这一点和 嵌套聚合 类似。但是,对于父文档的聚合查询是不支持的(和 reverse_nested 类似)。
我们通过下面的例子来演示按照国家维度查看最受雇员欢迎的业余爱好:
GET /company/branch/_search
{
"size" : 0,
"aggs": {
"country": {
"terms": { <1>
"field": "country"
},
"aggs": {
"employees": {
"children": { <2>
"type": "employee"
},
"aggs": {
"hobby": {
"terms": { <3>
"field": "hobby"
}
}
}
}
}
}
}
}
country是branch文档的一个字段。
employeetype 的子文档将其父文档聚合在一起。
hobby是employee子文档的一个字段。
祖辈与孙辈关系
父子关系可以延展到更多代关系,比如生活中孙辈与祖辈的关系 — 唯一的要求是满足这些关系的文档必须在同一个分片上被索引。
让我们把上一个例子中的 country 类型设定为 branch 类型的父辈:
PUT /company
{
"mappings": {
"country": {},
"branch": {
"_parent": {
"type": "country" <1>
}
},
"employee": {
"_parent": {
"type": "branch" <2>
}
}
}
}
branch是country的子辈。
employee是branch的子辈。
country 和 branch 之间是一层简单的父子关系,所以我们的 操作步骤 与之前保持一致:
POST /company/country/_bulk
{ "index": { "_id": "uk" }}
{ "name": "UK" }
{ "index": { "_id": "france" }}
{ "name": "France" }
POST /company/branch/_bulk
{ "index": { "_id": "london", "parent": "uk" }}
{ "name": "London Westmintster" }
{ "index": { "_id": "liverpool", "parent": "uk" }}
{ "name": "Liverpool Central" }
{ "index": { "_id": "paris", "parent": "france" }}
{ "name": "Champs Élysées" }
parent ID 使得每一个 branch 文档被路由到与其父文档 country 相同的分片上进行操作。然而,当我们使用相同的方法来操作 employee 这个孙辈文档时,会发生什么呢?
PUT /company/employee/1?parent=london
{
"name": "Alice Smith",
"dob": "1970-10-24",
"hobby": "hiking"
}
employee 文档的路由依赖其父文档 ID — 也就是 london — 但是 london 文档的路由却依赖 其本身的 父文档 ID — 也就是 uk 。此种情况下,孙辈文档很有可能最终和父辈、祖辈文档不在同一分片上,导致不满足祖辈和孙辈文档必须在同一个分片上被索引的要求。
解决方案是添加一个额外的 routing 参数,将其设置为祖辈的文档 ID ,以此来保证三代文档路由到同一个分片上。索引请求如下所示:
PUT /company/employee/1?parent=london&routing=uk <1>
{
"name": "Alice Smith",
"dob": "1970-10-24",
"hobby": "hiking"
}
routing的值会取代parent的值作为路由选择。
parent 参数的值仍然可以标识 employee 文档与其父文档的关系,但是 routing 参数保证该文档被存储到其父辈和祖辈的分片上。routing 值在所有的文档请求中都要添加。
联合多代文档进行查询和聚合是可行的,只需要一代代的进行设定即可。例如,我们要找到哪些国家的雇员喜欢远足旅行,此时只需要联合 country 和 branch,以及 branch 和 employee:
GET /company/country/_search
{
"query": {
"has_child": {
"type": "branch",
"query": {
"has_child": {
"type": "employee",
"query": {
"match": {
"hobby": "hiking"
}
}
}
}
}
}
}
实际使用中的一些建议
当文档索引性能远比查询性能重要 的时候,父子关系是非常有用的,但是它也是有巨大代价的。其查询速度会比同等的嵌套查询慢5到10倍!
全局序号和延迟
父子关系使用了全局序数 来加速文档间的联合。不管父子关系映射是否使用了内存缓存或基于硬盘的 doc values,当索引变更时,全局序数要重建。
一个分片中父文档越多,那么全局序数的重建就需要更多的时间。父子关系更适合于父文档少、子文档多的情况。
全局序数默认情况下是延迟构建的:在refresh后的第一个父子查询会触发全局序数的构建。而这个构建会导致用户使用时感受到明显的迟缓。你可以使用全局序数预加载 来将全局序数构建的开销由query阶段转移到refresh阶段,设置如下:
PUT /company
{
"mappings": {
"branch": {},
"employee": {
"_parent": {
"type": "branch",
"fielddata": {
"loading": "eager_global_ordinals" <1>
}
}
}
}
}
_parent字段的全局序数会被构建。
当父文档过多时,全局序数的构建会耗费很多时间。此时可以通过增加 refresh_interval 来减少 refresh 的次数,延长全局序数的有效时间,这也很大程度上减小了全局序数每秒重建的cpu消耗。
多代使用和结语
多代文档的联合查询(查看 祖辈与孙辈关系)虽然看起来很吸引人 ,但必须考虑如下的代价:
- 联合越多,性能越差。
- 每一代的父文档都要将其字符串类型的
_id字段存储在内存中,这会占用大量内存。
当你考虑父子关系是否适合你现有关系模型时,请考虑下面这些建议 :
- 尽量少地使用父子关系,仅在子文档远多于父文档时使用。
- 避免在一个查询中使用多个父子联合语句。
- 在 has_child 查询中使用 filter 上下文,或者设置 score_mode 为 none 来避免计算文档得分。
- 保证父 IDs 尽量短,以便在 doc values 中更好地压缩,被临时载入时占用更少的内存。
最重要的是: 先考虑下我们之前讨论过的其他方式来达到父子关系的效果。
扩容设计
一些公司每天使用 Elasticsearch 索引检索 PB 级数据, 但我们中的大多数都起步于规模稍逊的项目。即使我们立志成为下一个 Facebook,我们的银行卡余额却也跟不上梦想的脚步。 我们需要为今日所需而构建,但也要允许我们可以灵活而又快速地进行水平扩展。
Elasticsearch 为了可扩展性而生。它可以良好地运行于你的笔记本电脑又或者一个拥有数百节点的集群,同时用户体验基本相同。 由小规模集群增长为大规模集群的过程几乎完全自动化并且无痛。由大规模集群增长为超大规模集群需要一些规划和设计,但还是相对地无痛。
当然这一切并不是魔法。Elasticsearch 也有它的局限性。如果你了解这些局限性并能够与之相处,集群扩容的过程将会是愉快的。 如果你对 Elasticsearch 处理不当,那么你将处于一个充满痛苦的世界。
Elasticsearch 的默认设置会伴你走过很长的一段路,但为了发挥它最大的效用,你需要考虑数据是如何流经你的系统的。 我们将讨论两种常见的数据流:时序数据(时间驱动相关性,例如日志或社交网络数据流),以及基于用户的数据(拥有很大的文档集但可以按用户或客户细分)。
这一章将帮助你在遇到不愉快之前做出正确的选择。
扩容的单元
在 动态更新索引,我们介绍了一个分片即一个 Lucene 索引 ,一个 Elasticsearch 索引即一系列分片的集合。 你的应用程序与索引进行交互,Elasticsearch 帮助你将请求路由至相应的分片。
一个分片即为 扩容的单元 。 一个最小的索引拥有一个分片。 这可能已经完全满足你的需求了 — 单个分片即可存储大量的数据 — 但这限制了你的可扩展性。
想象一下我们的集群由一个节点组成,在集群内我们拥有一个索引,这个索引只含一个分片:
PUT /my_index
{
"settings": {
"number_of_shards": 1, <1>
"number_of_replicas": 0
}
}
这个设置值也许很小,但它满足我们当前的需求而且运行代价低。
在美好的一天,互联网发现了我们,一个节点再也承受不了我们的流量。 我们决定根据 图 49 “一个只有一个分片的索引无扩容因子” 添加一个节点。这将会发生什么呢?
图 49. 一个只有一个分片的索引无扩容因子

答案是:什么都不会发生。因为我们只有一个分片,已经没有什么可以放在第二个节点上的了。 我们不能增加索引的分片数因为它是 route documents to shards 算法中的重要元素:
shard = hash(routing) % number_of_primary_shards
我们当前的选择只有一个就是将数据重新索引至一个拥有更多分片的一个更大的索引,但这样做将消耗的时间是我们无法提供的。 通过事先规划,我们可以使用 预分配 的方式来完全避免这个问题。
分片预分配
一个分片存在于单个节点, 但一个节点可以持有多个分片。想象一下我们创建拥有两个主分片的索引而不是一个:
PUT /my_index
{
"settings": {
"number_of_shards": 2, <1>
"number_of_replicas": 0
}
}
当只有一个节点时,两个分片都将被分配至相同的节点。 从我们应用程序的角度来看,一切都和之前一样运作着。应用程序和索引进行通讯,而不是分片,现在还是只有一个索引。
这时,我们加入第二个节点,Elasticsearch 会自动将其中一个分片移动至第二个节点,如 图 50 “一个拥有两个分片的索引可以利用第二个节点” 描绘的那样, 当重新分配完成后,每个分片都将接近至两倍于之前的计算能力。
图 50. 一个拥有两个分片的索引可以利用第二个节点
我们已经可以通过简单地将一个分片通过网络复制到一个新的节点来加倍我们的处理能力。 最棒的是,我们零停机地做到了这一点。在分片移动过程中,所有的索引搜索请求均在正常运行。
在 Elasticsearch 中新添加的索引默认被指定了五个主分片。 这意味着我们最多可以将那个索引分散到五个节点上,每个节点一个分片。 它具有很高的处理能力,还未等你去思考这一切就已经做到了!
分片分裂
用户经常在问,为什么 Elasticsearch 不支持 分片分裂(shard-splitting)— 将每个分片分裂为两个或更多部分的能力。 原因就是分片分裂是一个糟糕的想法:
- 分裂一个分片几乎等于重新索引你的数据。它是一个比仅仅将分片从一个节点复制到另一个节点更重量级的操作。
- 分裂是指数的。起初你你有一个分片,然后分裂为两个,然后四个,八个,十六个,等等。分裂并不会刚好地把你的处理能力提升 50%。
分片分裂需要你拥有足够的能力支撑另一份索引的拷贝。通常来说,当你意识到你需要横向扩展时,你已经没有足够的剩余空间来做分裂了。
Elasticsearch 通过另一种方式来支持分片分裂。你总是可以把你的数据重新索引至一个拥有适当分片个数的新索引(参阅 重新索引你的数据)。 和移动分片比起来这依然是一个更加密集的操作,依然需要足够的剩余空间来完成,但至少你可以控制新索引的分片个数了。
海量分片
当新手们在了解过 分片预分配 之后做的第一件事就是对自己说:
我不知道这个索引将来会变得多大,并且过后我也不能更改索引的大小,所以为了保险起见,还是给它设为 1000 个分片吧… -- 一个新手的话
一千个分片——当真?在你买来 一千个节点 之前,你不觉得你可能需要再三思考你的数据模型然后将它们重新索引吗?
一个分片并不是没有代价的。记住:
- 一个分片的底层即为一个 Lucene 索引,会消耗一定文件句柄、内存、以及 CPU 运转。
- 每一个搜索请求都需要命中索引中的每一个分片,如果每一个分片都处于不同的节点还好, 但如果多个分片都需要在同一个节点上竞争使用相同的资源就有些糟糕了。
- 用于计算相关度的词项统计信息是基于分片的。如果有许多分片,每一个都只有很少的数据会导致很低的相关度。 适当的预分配是好的。但上千个分片就有些糟糕。我们很难去定义分片是否过多了,这取决于它们的大小以及如何去使用它们。 一百个分片但很少使用还好,两个分片但非常频繁地使用有可能就有点多了。 监控你的节点保证它们留有足够的空闲资源来处理一些特殊情况。
横向扩展应当分阶段进行。为下一阶段准备好足够的资源。 只有当你进入到下一个阶段,你才有时间思考需要作出哪些改变来达到这个阶段。
容量规划
如果一个分片太少而 1000 个又太多,那么我怎么知道我需要多少分片呢? 一般情况下这是一个无法回答的问题。因为实在有太多相关的因素了:你使用的硬件、文档的大小和复杂度、文档的索引分析方式、运行的查询类型、执行的聚合以及你的数据模型等等。
幸运的是,在特定场景下这是一个容易回答的问题,尤其是你自己的场景:
- 基于你准备用于生产环境的硬件创建一个拥有单个节点的集群。
- 创建一个和你准备用于生产环境相同配置和分析器的索引,但让它只有一个主分片无副本分片。
- 索引实际的文档(或者尽可能接近实际)。
- 运行实际的查询和聚合(或者尽可能接近实际)。
基本来说,你需要复制真实环境的使用方式并将它们全部压缩到单个分片上直到它“挂掉。” 实际上 挂掉 的定义也取决于你:一些用户需要所有响应在 50 毫秒内返回;另一些则乐于等上 5 秒钟。
一旦你定义好了单个分片的容量,很容易就可以推算出整个索引的分片数。 用你需要索引的数据总数加上一部分预期的增长,除以单个分片的容量,结果就是你需要的主分片个数。
先看看有没有办法优化你对 Elasticsearch 的使用方式。也许你有低效的查询,缺少足够的内存,又或者你开启了 swap?
我们见过一些新手对于初始性能感到沮丧,立即就着手调优垃圾回收又或者是线程数,而不是处理简单问题例如去掉通配符查询。
副本分片
目前为止我们只讨论过主分片,但我们身边还有另一个工具:副本分片。 副本分片的主要目的就是为了故障转移,正如在 集群内的原理 中讨论的:如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色。
在索引写入时,副本分片做着与主分片相同的工作。新文档首先被索引进主分片然后再同步到其它所有的副本分片。增加副本数并不会增加索引容量。
无论如何,副本分片可以服务于读请求,如果你的索引也如常见的那样是偏向查询使用的,那你可以通过增加副本的数目来提升查询性能,但也要为此 增加额外的硬件资源。
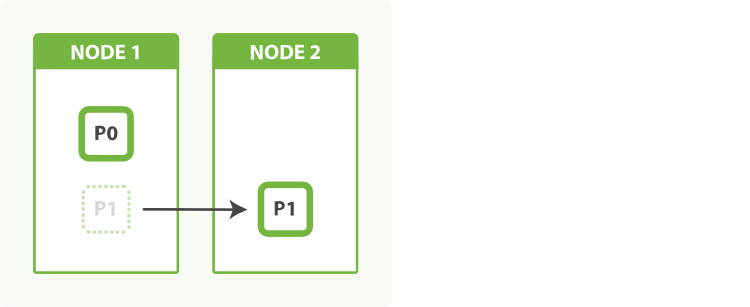
让我们回到那个有着两个主分片索引的例子。我通过增加第二个节点来提升索引容量。 增加额外的节点不会帮助我们提升索引写入能力,但我们可以通过增加副本数在搜索时利用额外的硬件:
PUT /my_index/_settings
{
"number_of_replicas": 1
}
拥有两个主分片,加上每个主分片的一个副本,总共给予我们四个分片:每个节点一个,如图所示 图 51 “一个拥有两个主分片一份副本的索引可以在四个节点中横向扩展”。
图 51. 一个拥有两个主分片一份副本的索引可以在四个节点中横向扩展
通过副本进行负载均衡
搜索性能取决于最慢的节点的响应时间,所以尝试均衡所有节点的负载是一个好想法。 如果我们只是增加一个节点而不是两个,最终我们会有两个节点各持有一个分片,而另一个持有两个分片做着两倍的工作。
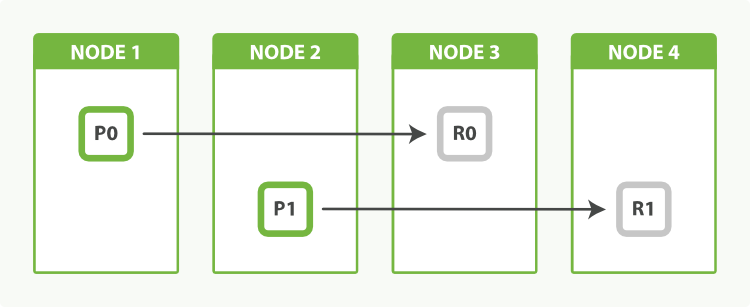
我们可以通过调整副本数量来平衡这些。通过分配两份副本而不是一个,最终我们会拥有六个分片,刚好可以平均分给三个节点,如图所示 图 52 “通过调整副本数来均衡节点负载”:
PUT /my_index/_settings
{
"number_of_replicas": 2
}
作为奖励,我们同时提升了我们的可用性。我们可以容忍丢失两个节点而仍然保持一份完整数据的拷贝。
图 52. 通过调整副本数来均衡节点负载
多索引
最后,记住没有任何规则限制你的应用程序只使用一个索引。 当我们发起一个搜索请求时,它被转发至索引中每个分片的一份拷贝(一个主分片或一个副本分片),如果我们向多个索引发出同样的请求,会发生完全相同的事情——只不过会涉及更多的分片。
当你需要在不停服务的情况下增加容量时,下面有一些有用的建议。相较于将数据迁移到更大的索引中,你可以仅仅做下面这些操作:
- 创建一个新的索引来存储新的数据。
- 同时搜索两个索引来获取新数据和旧数据。
实际上,通过一点预先计划,添加一个新索引可以通过一种完全透明的方式完成,你的应用程序根本不会察觉到任何的改变。
在 索引别名和零停机,我们提到过使用索引别名来指向当前版本的索引。 举例来说,给你的索引命名为 tweets_v1 而不是 tweets 。你的应用程序会与 tweets 进行交互,但事实上它是一个指向 tweets_v1 的别名。 这允许你将别名切换至一个更新版本的索引而保持服务运转。
我们可以使用一个类似的技术通过增加一个新索引来扩展容量。这需要一点点规划,因为你需要两个别名:一个用于搜索另一个用于索引数据:
PUT /tweets_1/_alias/tweets_search <1>
PUT /tweets_1/_alias/tweets_index <2>
tweets_search与tweets_index这两个别名都指向索引tweets_1。
新文档应当索引至 tweets_index ,同时,搜索请求应当对别名 tweets_search 发出。目前,这两个别名指向同一个索引。
当我们需要额外容量时,我们可以创建一个名为 tweets_2 的索引,并且像这样更新别名:
POST /_aliases
{
"actions": [
{ "add": { "index": "tweets_2", "alias": "tweets_search" }}, <1>
{ "remove": { "index": "tweets_1", "alias": "tweets_index" }}, <2>
{ "add": { "index": "tweets_2", "alias": "tweets_index" }} <3>
]
}
tweets_2到别名tweets_search。
tweets_index由tweets_1切换至tweets_2。
一个搜索请求可以以多个索引为目标,所以将搜索别名指向 tweets_1 以及 tweets_2 是完全有效的。 然而,索引写入请求只能以单个索引为目标。因此,我们必须将索引写入的别名只指向新的索引。
GET请求,像一个索引写入请求那样,只能以单个索引为目标。 这导致在通过ID获取文档这样的场景下有一点复杂。作为代替,你可以对tweets_1以及tweets_2运行一个ids查询 搜索请求, 或者multi-get请求。
在服务运行中使用多索引来扩展索引容量对于一些使用场景有着特别的好处,像我们将在下一节中讨论的基于时间的数据例如日志或社交事件流。
基于时间的数据
Elasticsearch 的常用案例之一便是日志记录, 它实在太常见了以至于 Elasticsearch 提供了一个集成的日志平台叫做 ELK stack— Elasticsearch,Logstash,以及 Kibana ——来让这项工作变得简单。
Logstash 采集、解析日志并在将它们写入Elasticsearch之前格式化。 Elasticsearch 扮演了一个集中式的日志服务角色, Kibana 是一个 图形化前端可以很容易地实时查询以及可视化你的网络变化。
搜索引擎中大多数使用场景都是增长缓慢相对稳定的文档集合。搜索查找最相关的文档,而不关心它是何时创建的。
日志——以及其他基于时间的数据流例如社交网络活动——实际上有很大不同。 索引中文档数量迅速增长,通常随时间加速。 文档几乎不会更新,基本以最近文档为搜索目标。随着时间推移,文档逐渐失去价值。
我们需要调整索引设计使其能够工作于这种基于时间的数据流。
按时间范围索引
如果我们为此种类型的文档建立一个超大索引,我们可能会很快耗尽存储空间。日志事件会不断的进来,不会停顿也不会中断。 我们可以使用 scroll 查询和批量删除来删除旧的事件。但这种方法 非常低效 。当你删除一个文档,它只会被 标记 为被删除(参见 删除和更新)。 在包含它的段被合并之前不会被物理删除。
替代方案是,我们使用一个 时间范围索引 。你可以着手于一个按年的索引 (logs_2014) 或按月的索引 (logs_2014-10) 。 也许当你的网页变得十分繁忙时,你需要切换到一个按天的索引 (logs_2014-10-24) 。删除旧数据十分简单:只需要删除旧的索引。
这种方法有这样的优点,允许你在需要的时候进行扩容。你不需要预先做任何艰难的决定。每天都是一个新的机会来调整你的索引时间范围来适应当前需求。 应用相同的逻辑到决定每个索引的大小上。起初也许你需要的仅仅是每周一个主分片。过一阵子,也许你需要每天五个主分片。这都不重要——任何时间你都可以调整到新的环境。
别名可以帮助我们更加透明地在索引间切换。 当创建索引时,你可以将 logs_current 指向当前索引来接收新的日志事件, 当检索时,更新 last_3_months 来指向所有最近三个月的索引:
POST /_aliases
{
"actions": [
{ "add": { "alias": "logs_current", "index": "logs_2014-10" }}, <1>
{ "remove": { "alias": "logs_current", "index": "logs_2014-09" }}, <2>
{ "add": { "alias": "last_3_months", "index": "logs_2014-10" }}, <3>
{ "remove": { "alias": "last_3_months", "index": "logs_2014-07" }} <4>
]
}
logs_current由九月切换至十月。
last_3_months并且删掉七月。
索引模板
Elasticsearch 不要求你在使用一个索引前创建它。 对于日志记录类应用,依赖于自动创建索引比手动创建要更加方便。
Logstash 使用事件中的时间戳来生成索引名。 默认每天被索引至不同的索引中,因此一个 @timestamp 为 2014-10-01 00:00:01 的事件将被发送至索引 logstash-2014.10.01 中。 如果那个索引不存在,它将被自动创建。
通常我们想要控制一些新建索引的设置(settings)和映射(mappings)。也许我们想要限制分片数为 1,并且禁用 _all 域。 索引模板可以用于控制何种设置(settings)应当被应用于新创建的索引:
PUT /_template/my_logs <1>
{
"template": "logstash-*", <2>
"order": 1, <3>
"settings": {
"number_of_shards": 1 <4>
},
"mappings": {
"_default_": { <5>
"_all": {
"enabled": false
}
}
},
"aliases": {
"last_3_months": {} <6>
}
}
my_logs的模板。
logstash-为起始的索引。
logstash模板,因为默认模板的order更低。
1。
_all域。
last_3_months别名中。
这个模板指定了所有名字以 logstash- 为起始的索引的默认设置,不论它是手动还是自动创建的。 如果我们认为明天的索引需要比今天更大的容量,我们可以更新这个索引以使用更多的分片。
这个模板还将新建索引添加至了 last_3_months 别名中,然而从那个别名中删除旧的索引则需要手动执行。
数据过期
随着时间推移,基于时间数据的相关度逐渐降低。 有可能我们会想要查看上周、上个月甚至上一年度发生了什么,但是大多数情况,我们只关心当前发生的。
按时间范围索引带来的一个好处是可以方便地删除旧数据:只需要删除那些变得不重要的索引就可以了。
DELETE /logs_2013*
删除整个索引比删除单个文档要更加高效:Elasticsearch 只需要删除整个文件夹。
但是删除索引是 终极手段 。在我们决定完全删除它之前还有一些事情可以做来帮助数据更加优雅地过期。
迁移旧索引
随着数据被记录,很有可能存在一个 热点 索引——今日的索引。 所有新文档都会被加到那个索引,几乎所有查询都以它为目标。那个索引应当使用你最好的硬件。
Elasticsearch 是如何得知哪台是你最好的服务器呢?你可以通过给每台服务器指定任意的标签来告诉它。 例如,你可以像这样启动一个节点:
./bin/elasticsearch --node.box_type strong
box_type 参数是完全随意的——你可以将它随意命名只要你喜欢——但你可以用这些任意的值来告诉 Elasticsearch 将一个索引分配至何处。
我们可以通过按以下配置创建今日的索引来确保它被分配到我们最好的服务器上:
PUT /logs_2014-10-01
{
"settings": {
"index.routing.allocation.include.box_type" : "strong"
}
}
昨日的索引不再需要我们最好的服务器了,我们可以通过更新索引设置将它移动到标记为 medium 的节点上:
POST /logs_2014-09-30/_settings
{
"index.routing.allocation.include.box_type" : "medium"
}
索引优化(Optimize)
昨日的索引不大可能会改变。 日志事件是静态的:已经发生的过往不会再改变了。如果我们将每个分片合并至一个段(Segment),它会占用更少的资源更快地响应查询。 我们可以通过optimize API来做到。
对还分配在 strong 主机上的索引进行优化(Optimize)操作将会是一个糟糕的想法, 因为优化操作将消耗节点上大量 I/O 并对索引今日日志造成冲击。但是 medium 的节点没有做太多类似的工作,我们可以安全地在上面进行优化。
昨日的索引有可能拥有副本分片。 如果我们下发一个优化(Optimize)请求, 它会优化主分片和副本分片,这有些浪费。然而,我们可以临时移除副本分片,进行优化,然后再恢复副本分片:
POST /logs_2014-09-30/_settings
{ "number_of_replicas": 0 }
POST /logs_2014-09-30/_optimize?max_num_segments=1
POST /logs_2014-09-30/_settings
{ "number_of_replicas": 1 }
当然,没有副本我们将面临磁盘故障而导致丢失数据的风险。你可能想要先通过snapshot-restore API备份数据。
关闭旧索引
当索引变得更“老”,它们到达一个几乎不会再被访问的时间点。 我们可以在这个阶段删除它们,但也许你想将它们留在这里以防万一有人在半年后还想要访问它们。
这些索引可以被关闭。它们还会存在于集群中,但它们不会消耗磁盘空间以外的资源。重新打开一个索引要比从备份中恢复快得多。
在关闭之前,值得我们去刷写索引来确保没有事务残留在事务日志中。一个空白的事务日志会使得索引在重新打开时恢复得更快:
POST /logs_2014-01-*/_flush <1>
POST /logs_2014-01-*/_close <2>
POST /logs_2014-01-*/_open <3>
openAPI 来重新打开它们。
归档旧索引
最后,非常旧的索引 可以通过snapshot-restore API归档至长期存储例如共享磁盘或者 Amazon S3,以防日后你可能需要访问它们。 当存在备份时我们就可以将索引从集群中删除了。
基于用户的数据
通常来说,用户使用 Elasticsearch 的原因是他们需要添加全文检索或者需要分析一个已经存在的应用。 他们创建一个索引来存储所有文档。公司里的其他人也逐渐发现了 Elasticsearch 带来的好处,也想把他们的数据添加到 Elasticsearch 中去。
幸运的是,Elasticsearch 支持多租户所以每个用户可以在相同的集群中拥有自己的索引。 有人偶尔会想要搜索所有用户的文档,这种情况可以通过搜索所有索引实现,但大多数情况下用户只关心它们自己的文档。
一些用户有着比其他人更多的文档,一些用户可能有比其他人更多的搜索次数, 所以这种对指定每个索引主分片和副本分片数量能力的需要应该很适合使用“一个用户一个索引”的模式。 类似地,较为繁忙的索引可以通过分片分配过滤指定到高配的节点。(参见 迁移旧索引。)
大多数 Elasticsearch 的用户读到这里就已经够了。简单的“一个用户一个索引”对大多数场景都可以满足了。
对于例外的场景,你可能会发现需要支持很大数量的用户,都是相似的需求。一个例子可能是为一个拥有几千个邮箱账户的论坛提供搜索服务。 一些论坛可能有巨大的流量,但大多数都很小。将一个有着单个分片的索引用于一个小规模论坛已经是足够的了——一个分片可以承载很多个论坛的数据。
我们需要的是一种可以在用户间共享资源的方法,给每个用户他们拥有自己的索引这种印象,而不在小用户上浪费资源。
共享索引
我们可以为许多的小论坛使用一个大的共享的索引, 将论坛标识索引进一个字段并且将它用作一个过滤器:
PUT /forums
{
"settings": {
"number_of_shards": 10 <1>
},
"mappings": {
"post": {
"properties": {
"forum_id": { <2>
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
PUT /forums/post/1
{
"forum_id": "baking", <3>
"title": "Easy recipe for ginger nuts",
...
}
forum_id来标识它属于哪个论坛。
我们可以把 forum_id 用作一个过滤器来针对单个论坛进行搜索。这个过滤器可以排除索引中绝大部分的数据(属于其它论坛的数据),缓存会保证快速的响应:
GET /forums/post/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "ginger nuts"
}
},
"filter": {
"term": {
"forum_id": {
"baking"
}
}
}
}
}
}
这个办法行得通,但我们可以做得更好。 来自于同一个论坛的帖子可以简单地容纳于单个分片,但它们现在被打散到了这个索引的所有十个分片中。 这意味着每个搜索请求都必须被转发至所有十个分片的一个主分片或者副本分片。 如果能够保证所有来自于同一个论坛的所有帖子都被存储于同一个分片可能会是个好想法。
在 路由一个文档到一个分片中,我们说过一个文档将通过使用如下公式来分配到一个指定分片:
shard = hash(routing) % number_of_primary_shards
routing 的值默认为文档的 _id ,但我们可以覆盖它并且提供我们自己自定义的路由值,例如 forum_id。 所有有着相同 routing 值的文档都将被存储于相同的分片:
PUT /forums/post/1?routing=baking <1>
{
"forum_id": "baking", <2>
"title": "Easy recipe for ginger nuts",
...
}
forum_id用于路由值保证所有来自相同论坛的帖子都存储于相同的分片。
当我们搜索一个指定论坛的帖子时,我们可以传递相同的 routing 值来保证搜索请求仅在存有我们文档的分片上执行:
GET /forums/post/_search?routing=baking <1>
{
"query": {
"bool": {
"must": {
"match": {
"title": "ginger nuts"
}
},
"filter": {
"term": { <2>
"forum_id": {
"baking"
}
}
}
}
}
}
routing值的分片上执行。
多个论坛可以通过传递一个逗号分隔的列表来指定 routing 值,然后将每个 forum_id 包含于一个 terms查询:
GET /forums/post/_search?routing=baking,cooking,recipes
{
"query": {
"bool": {
"must": {
"match": {
"title": "ginger nuts"
}
},
"filter": {
"terms": {
"forum_id": {
[ "baking", "cooking", "recipes" ]
}
}
}
}
}
}
这种方式从技术上来说比较高效,由于要为每一个查询或者索引请求指定 routing 和 terms 的值看起来有一点的笨拙。 索引别名可以帮你解决这些!
利用别名实现一个用户一个索引
为了保持设计的简洁,我们想让我们的应用认为我们为每个用户都有一个专门的索引——或者按照我们的例子每个论坛一个——尽管实际上我们用的是一个大的shared index。 因此,我们需要一种方式将 routing 值及过滤器隐含于 forum_id 中。
索引别名可以帮你做到这些。当你将一个别名与一个索引关联起来,你可以指定一个过滤器和一个路由值:
PUT /forums/_alias/baking
{
"routing": "baking",
"filter": {
"term": {
"forum_id": "baking"
}
}
}
现在我们可以将 baking 别名视为一个单独的索引。索引至 baking 别名的文档会自动地应用我们自定义的路由值:
PUT /baking/post/1 <1>
{
"forum_id": "baking", <2>
"title": "Easy recipe for ginger nuts",
...
}
forumn_id字段,但自定义路由值已经是隐含的了。
对 baking 别名上的查询只会在自定义路由值关联的分片上运行,并且结果也自动按照我们指定的过滤器进行了过滤:
GET /baking/post/_search
{
"query": {
"match": {
"title": "ginger nuts"
}
}
}
当对多个论坛进行搜索时可以指定多个别名:
GET /baking,recipes/post/_search <1>
{
"query": {
"match": {
"title": "ginger nuts"
}
}
}
routing的值都会应用,返回对结果会匹配任意一个过滤器。
一个大的用户
大规模流行论坛都是从小论坛起步的。 有一天我们会发现我们共享索引中的一个分片要比其它分片更加繁忙,因为这个分片中一个论坛的文档变得更加热门。 这时,那个论坛需要属于它自己的索引。
我们用来提供一个用户一个索引的索引别名给了我们一个简洁的迁移论坛方式。
第一步就是为那个论坛创建一个新的索引,并为其分配合理的分片数,可以满足一定预期的数据增长:
PUT /baking_v1
{
"settings": {
"number_of_shards": 3
}
}
第二步就是将共享的索引中的数据迁移到专用的索引中,可以通过scroll查询和bulk API来实现。 当迁移完成时,可以更新索引别名指向那个新的索引:
POST /_aliases
{
"actions": [
{ "remove": { "alias": "baking", "index": "forums" }},
{ "add": { "alias": "baking", "index": "baking_v1" }}
]
}
更新索引别名的操作是原子性的;就像在拨动一个开关。你的应用程序还是在与 baking API 交互并且对于它已经指向一个专用的索引毫无感知。
专用的索引不再需要过滤器或者自定义的路由值了。我们可以依赖于 Elasticsearch 默认使用的 _id 字段来做分区。
最后一步是从共享的索引中删除旧的文档,可以通过搜索之前的路由值以及论坛 ID 然后进行批量删除操作来实现。
一个用户一个索引模型的优雅之处在于它允许你减少资源消耗,保持快速的响应时间,同时拥有在需要时零宕机时间扩容的能力。
扩容并不是无限的
贯彻整个章节我们讨论了多种 Elasticsearch 可以做到的扩容方式。 大多数的扩容问题可以通过添加节点来解决。但有一种资源是有限制的,因此值得我们认真对待:集群状态。
集群状态 是一种数据结构,贮存下列集群级别的信息:
- 集群级别的设置
- 集群中的节点
- 索引以及它们的设置、映射、分析器、预热器(Warmers)和别名
- 与每个索引关联的分片以及它们分配到的节点
你可以通过如下请求查看当前的集群状态:
GET /_cluster/state
集群状态存在于集群中的每个节点, 包括客户端节点。 这就是为什么任何一个节点都可以将请求直接转发至被请求数据的节点——每个节点都知道每个文档应该在哪里。
只有主节点被允许更新集群状态。想象一下一个索引请求引入了一个之前未知的字段。持有那个文档的主分片所在的节点必须将新的映射转发到主节点上。 主节点把更改合并到集群状态中,然后向所有集群中的所有节点发布一个新的版本。
搜索请求 使用 集群状态,但它们不会产生修改。同样,文档级别的增删改查请求也不会对集群状态产生修改。当然,除非它们引入了一个需要更新映射的新的字段了。 总的来说,集群状态是静态的不会成为瓶颈。
然而,需要记住的是相同的数据结构需要在每个节点的内存中保存,并且当它发生更改时必须发布到每一个节点。 集群状态的数据量越大,这个操作就会越久。
我们见过最常见的集群状态问题就是引入了太多的字段。一个用户可能会决定为每一个 IP 地址或者每个 referer URL 使用一个单独的字段。 下面这个例子通过为每一个唯一的 referer 使用一个不同的字段名来保持对页面浏览量的计数:
POST /counters/pageview/home_page/_update
{
"script": "ctx._source[referer]++",
"params": {
"referer": "http://www.foo.com/links?bar=baz"
}
}
这种方式十分的糟糕!它会生成数百万个字段,这些都需要被存储在集群状态中。 每当见到一个新的 referer ,都有一个新的字段需要加入那个已经膨胀的集群状态中,这都需要被发布到集群的每个节点中去。
更好的方式是使用 nested objects, 它使用一个字段作为参数名—referer—另一个字段作为关联的值—count :
"counters": [
{ "referer": "http://www.foo.com/links?bar=baz", "count": 2 },
{ "referer": "http://www.linkbait.com/article_3", "count": 10 },
...
]
这种嵌套的方式有可能会增加文档数量,但 Elasticsearch 生来就是为了解决它的。重要的是保持集群状态小而敏捷。
最终,不管你的初衷有多好,你可能会发现集群节点数量、索引、映射对于一个集群来说还是太大了。 此时,可能有必要将这个问题拆分到多个集群中了。感谢tribe nodes, 你甚至可以向多个集群发出搜索请求,就好像我们有一个巨大的集群那样。