基础入门
请求体查询
简易 查询 —query-string search— 对于用命令行进行即席查询(ad-hoc)是非常有用的。 然而,为了充分利用查询的强大功能,你应该使用 请求体 search API, 之所以称之为请求体查询(Full-Body Search),因为大部分参数是通过 Http 请求体而非查询字符串来传递的。
请求体查询 —下文简称 查询—不仅可以处理自身的查询请求,还允许你对结果进行片段强调(高亮)、对所有或部分结果进行聚合分析,同时还可以给出 你是不是想找 的建议,这些建议可以引导使用者快速找到他想要的结果。
空查询
让我们以 最简单的 search API 的形式开启我们的旅程,空查询将返回所有索引库(indices)中的所有文档:
GET /_search
{} <1>
这是一个空的请求体。
只用一个查询字符串,你就可以在一个、多个或者 _all 索引库(indices)和一个、多个或者所有types中查询:
GET /index_2014*/type1,type2/_search
{}
同时你可以使用 from 和 size 参数来分页:
GET /_search
{
"from": 30,
"size": 10
}
一个带请求体的 GET 请求?
某些特定语言(特别是 JavaScript)的 HTTP 库是不允许
GET请求带有请求体的。 事实上,一些使用者对于GET请求可以带请求体感到非常的吃惊。而事实是这个RFC文档 RFC 7231— 一个专门负责处理 HTTP 语义和内容的文档 — 并没有规定一个带有请求体的
GET请求应该如何处理!结果是,一些 HTTP 服务器允许这样子,而有一些 — 特别是一些用于缓存和代理的服务器 — 则不允许。对于一个查询请求,Elasticsearch 的工程师偏向于使用
GET方式,因为他们觉得它比POST能更好的描述信息检索(retrieving information)的行为。然而,因为带请求体的GET请求并不被广泛支持,所以searchAPI 同时支持POST请求:POST /_search { "from": 30, "size": 10 }类似的规则可以应用于任何需要带请求体的
GETAPI。
我们将在聚合 聚合 章节深入介绍聚合(aggregations),而现在,我们将聚焦在查询。
相对于使用晦涩难懂的查询字符串的方式,一个带请求体的查询允许我们使用 查询领域特定语言(query domain-specific language) 或者 Query DSL 来写查询语句。
查询表达式
查询表达式(Query DSL)是一种非常灵活又富有表现力的 查询语言。 Elasticsearch 使用它可以以简单的 JSON 接口来展现 Lucene 功能的绝大部分。在你的应用中,你应该用它来编写你的查询语句。它可以使你的查询语句更灵活、更精确、易读和易调试。
要使用这种查询表达式,只需将查询语句传递给 query 参数:
GET /_search
{
"query": YOUR_QUERY_HERE
}
空查询(empty search) —{}— 在功能上等价于使用 match_all 查询, 正如其名字一样,匹配所有文档:
GET /_search
{
"query": {
"match_all": {}
}
}
查询语句的结构
一个查询语句 的典型结构:
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
如果是针对某个字段,那么它的结构如下:
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
举个例子,你可以使用 match 查询语句 来查询 tweet 字段中包含 elasticsearch 的 tweet:
{
"match": {
"tweet": "elasticsearch"
}
}
完整的查询请求如下:
GET /_search
{
"query": {
"match": {
"tweet": "elasticsearch"
}
}
}
合并查询语句
查询语句(Query clauses) 就像一些简单的组合块 ,这些组合块可以彼此之间合并组成更复杂的查询。这些语句可以是如下形式:
- 叶子语句(Leaf clauses) (就像
match语句) 被用于将查询字符串和一个字段(或者多个字段)对比。 - 复合(Compound) 语句 主要用于 合并其它查询语句。 比如,一个
bool语句 允许在你需要的时候组合其它语句,无论是must匹配、must_not匹配还是should匹配,同时它可以包含不评分的过滤器(filters):
{
"bool": {
"must": { "match": { "tweet": "elasticsearch" }},
"must_not": { "match": { "name": "mary" }},
"should": { "match": { "tweet": "full text" }},
"filter": { "range": { "age" : { "gt" : 30 }} }
}
}
一条复合语句可以合并 任何 其它查询语句,包括复合语句,了解这一点是很重要的。这就意味着,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑。
例如,以下查询是为了找出信件正文包含 business opportunity 的星标邮件,或者在收件箱正文包含business opportunity 的非垃圾邮件:
{
"bool": {
"must": { "match": { "email": "business opportunity" }},
"should": [
{ "match": { "starred": true }},
{ "bool": {
"must": { "match": { "folder": "inbox" }},
"must_not": { "match": { "spam": true }}
}}
],
"minimum_should_match": 1
}
}
到目前为止,你不必太在意这个例子的细节,我们会在后面详细解释。最重要的是你要理解到,一条复合语句可以将多条语句 — 叶子语句和其它复合语句 — 合并成一个单一的查询语句。
查询与过滤
Elasticsearch 使用的查询语言(DSL) 拥有一套查询组件,这些组件可以以无限组合的方式进行搭配。这套组件可以在以下两种情况下使用:过滤情况(filtering context)和查询情况(query context)。
当使用于 过滤情况 时,查询被设置成一个“不评分”或者“过滤”查询。即,这个查询只是简单的问一个问题:“这篇文档是否匹配?”。回答也是非常的简单,yes 或者 no ,二者必居其一。
created时间是否在2013与2014这个区间?status字段是否包含published这个单词?lat_lon字段表示的位置是否在指定点的10km范围内?
当使用于 查询情况 时,查询就变成了一个“评分”的查询。和不评分的查询类似,也要去判断这个文档是否匹配,同时它还需要判断这个文档匹配的有 多好(匹配程度如何)。 此查询的典型用法是用于查找以下文档:
- 查找与
full text search这个词语最佳匹配的文档 - 包含
run这个词,也能匹配runs、running、jog或者sprint - 包含
quick、brown和fox这几个词 — 词之间离的越近,文档相关性越高 - 标有
lucene、search或者java标签 — 标签越多,相关性越高
一个评分查询计算每一个文档与此查询的 相关程度,同时将这个相关程度分配给表示相关性的字段 _score,并且按照相关性对匹配到的文档进行排序。这种相关性的概念是非常适合全文搜索的情况,因为全文搜索几乎没有完全 “正确” 的答案。
自 Elasticsearch 问世以来,查询与过滤(queries and filters)就独自成为 Elasticsearch 的组件。但从 Elasticsearch 2.0 开始,过滤(filters)已经从技术上被排除了,同时所有的查询(queries)拥有变成不评分查询的能力。
然而,为了明确和简单,我们用 "filter" 这个词表示不评分、只过滤情况下的查询。你可以把 "filter" 、 "filtering query" 和 "non-scoring query" 这几个词视为相同的。
相似的,如果单独地不加任何修饰词地使用 "query" 这个词,我们指的是 "scoring query" 。
性能差异
过滤查询(Filtering queries)只是简单的检查包含或者排除,这就使得计算起来非常快。考虑到至少有一个过滤查询(filtering query)的结果是 “稀少的”(很少匹配的文档),并且经常使用不评分查询(non-scoring queries),结果会被缓存到内存中以便快速读取,所以有各种各样的手段来优化查询结果。
相反,评分查询(scoring queries)不仅仅要找出 匹配的文档,还要计算每个匹配文档的相关性,计算相关性使得它们比不评分查询费力的多。同时,查询结果并不缓存。
多亏倒排索引(inverted index),一个简单的评分查询在匹配少量文档时可能与一个涵盖百万文档的filter表现的一样好,甚至会更好。但是在一般情况下,一个filter 会比一个评分的query性能更优异,并且每次都表现的很稳定。
过滤(filtering)的目标是减少那些需要通过评分查询(scoring queries)进行检查的文档。
如何选择查询与过滤
通常的规则是,使用 查询(query)语句来进行
全文 搜索或者其它任何需要影响 相关性得分 的搜索。除此以外的情况都使用过滤(filters)。
最重要的查询
虽然 Elasticsearch 自带了很多的查询,但经常用到的也就那么几个。我们将在 深入搜索 章节详细讨论那些查询的细节,接下来我们对最重要的几个查询进行简单介绍。
match_all 查询
match_all 查询简单的 匹配所有文档。在没有指定查询方式时,它是默认的查询:
{ "match_all": {}}
它经常与 filter 结合使用--例如,检索收件箱里的所有邮件。所有邮件被认为具有相同的相关性,所以都将获得分值为 1 的中性 _score。
match 查询
无论你在任何字段上进行的是全文搜索还是精确查询,match 查询是你可用的标准查询。
如果你在一个全文字段上使用 match 查询,在执行查询前,它将用正确的分析器去分析查询字符串:
{ "match": { "tweet": "About Search" }}
如果在一个精确值的字段上使用它, 例如数字、日期、布尔或者一个 not_analyzed 字符串字段,那么它将会精确匹配给定的值:
{ "match": { "age": 26 }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
{ "match": { "tag": "full_text" }}
对于精确值的查询,你可能需要使用 filter 语句来取代 query,因为 filter 将会被缓存。接下来,我们将看到一些关于 filter 的例子。
不像我们在 轻量 搜索 章节介绍的字符串查询(query-string search), match 查询不使用类似 +user_id:2 +tweet:search 的查询语法。它只是去查找给定的单词。这就意味着将查询字段暴露给你的用户是安全的;你需要控制那些允许被查询字段,不易于抛出语法异常。
multi_match 查询
multi_match 查询可以在多个字段上执行相同的 match 查询:
{
"multi_match": {
"query": "full text search",
"fields": [ "title", "body" ]
}
}
range 查询
range 查询找出那些落在指定区间内的数字或者时间:
{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
被允许的操作符如下:
gt大于
gte大于等于
lt小于
lte小于等于
term 查询
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些 not_analyzed 的字符串:
{ "term": { "age": 26 }}
{ "term": { "date": "2014-09-01" }}
{ "term": { "public": true }}
{ "term": { "tag": "full_text" }}
term 查询对于输入的文本不 分析 ,所以它将给定的值进行精确查询。
terms 查询
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件:
{ "terms": { "tag": [ "search", "full_text", "nosql" ] }}
和 term 查询一样,terms 查询对于输入的文本不分析。它查询那些精确匹配的值(包括在大小写、重音、空格等方面的差异)。
exists 查询和 missing 查询
exists 查询和 missing 查询被用于查找那些指定字段中有值 (exists) 或无值 (missing) 的文档。这与SQL中的 IS_NULL (missing) 和 NOT IS_NULL (exists) 在本质上具有共性:
{
"exists": {
"field": "title"
}
}
这些查询经常用于某个字段有值的情况和某个字段缺值的情况。
组合多查询
现实的查询需求从来都没有那么简单;它们需要在多个字段上查询多种多样的文本,并且根据一系列的标准来过滤。为了构建类似的高级查询,你需要一种能够将多查询组合成单一查询的查询方法。
你可以用 bool 查询来实现你的需求。这种查询将多查询组合在一起,成为用户自己想要的布尔查询。它接收以下参数:
must文档 必须 匹配这些条件才能被包含进来。
must_not文档 必须不 匹配这些条件才能被包含进来。
should如果满足这些语句中的任意语句,将增加
_score,否则,无任何影响。它们主要用于修正每个文档的相关性得分。filter必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
由于这是我们看到的第一个包含多个查询的查询,所以有必要讨论一下相关性得分是如何组合的。每一个子查询都独自地计算文档的相关性得分。一旦他们的得分被计算出来, bool 查询就将这些得分进行合并并且返回一个代表整个布尔操作的得分。
下面的查询用于查找 title 字段匹配 how to make millions 并且不被标识为 spam 的文档。那些被标识为 starred 或在2014之后的文档,将比另外那些文档拥有更高的排名。如果 两者 都满足,那么它排名将更高:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}
must语句,那么至少需要能够匹配其中的一条should语句。但,如果存在至少一条must语句,则对should语句的匹配没有要求。
增加带过滤器(filtering)的查询
如果我们不想因为文档的时间而影响得分,可以用 filter 语句来重写前面的例子:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"range": { "date": { "gte": "2014-01-01" }} <1>
}
}
}
should语句中移到filter语句
通过将 range 查询移到 filter 语句中,我们将它转成不评分的查询,将不再影响文档的相关性排名。由于它现在是一个不评分的查询,可以使用各种对 filter 查询有效的优化手段来提升性能。
所有查询都可以借鉴这种方式。将查询移到 bool 查询的 filter 语句中,这样它就自动的转成一个不评分的 filter 了。
如果你需要通过多个不同的标准来过滤你的文档,bool 查询本身也可以被用做不评分的查询。简单地将它放置到 filter 语句中并在内部构建布尔逻辑:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"bool": { <1>
"must": [
{ "range": { "date": { "gte": "2014-01-01" }}},
{ "range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks" }}
]
}
}
}
}
bool查询包裹在filter语句中,我们可以在过滤标准中增加布尔逻辑
通过混合布尔查询,我们可以在我们的查询请求中灵活地编写 scoring 和 filtering 查询逻辑。
constant_score 查询
尽管没有 bool 查询使用这么频繁,constant_score 查询也是你工具箱里有用的查询工具。它将一个不变的常量评分应用于所有匹配的文档。它被经常用于你只需要执行一个 filter 而没有其它查询(例如,评分查询)的情况下。
可以使用它来取代只有 filter 语句的 bool 查询。在性能上是完全相同的,但对于提高查询简洁性和清晰度有很大帮助。
{
"constant_score": {
"filter": {
"term": { "category": "ebooks" } <1>
}
}
}
term查询被放置在constant_score中,转成不评分的 filter。这种方式可以用来取代只有 filter 语句的bool查询。
验证查询
查询可以变得非常的复杂,尤其 和不同的分析器与不同的字段映射结合时,理解起来就有点困难了。不过 validate-query API 可以用来验证查询是否合法。
GET /gb/tweet/_validate/query
{
"query": {
"tweet" : {
"match" : "really powerful"
}
}
}
以上 validate 请求的应答告诉我们这个查询是不合法的:
{
"valid" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
}
}
理解错误信息
为了找出 查询不合法的原因,可以将 explain 参数 加到查询字符串中:
GET /gb/tweet/_validate/query?explain <1>
{
"query": {
"tweet" : {
"match" : "really powerful"
}
}
}
explain参数可以提供更多关于查询不合法的信息。
很明显,我们将查询类型(match)与字段名称 (tweet)搞混了:
{
"valid" : false,
"_shards" : { ... },
"explanations" : [ {
"index" : "gb",
"valid" : false,
"error" : "org.elasticsearch.index.query.QueryParsingException:
[gb] No query registered for [tweet]"
} ]
}
理解查询语句
对于合法查询,使用 explain 参数将返回可读的描述,这对准确理解 Elasticsearch 是如何解析你的 query 是非常有用的:
GET /_validate/query?explain
{
"query": {
"match" : {
"tweet" : "really powerful"
}
}
}
我们查询的每一个 index 都会返回对应的 explanation ,因为每一个 index 都有自己的映射和分析器:
{
"valid" : true,
"_shards" : { ... },
"explanations" : [ {
"index" : "us",
"valid" : true,
"explanation" : "tweet:really tweet:powerful"
}, {
"index" : "gb",
"valid" : true,
"explanation" : "tweet:realli tweet:power"
} ]
}
从 explanation 中可以看出,匹配 really powerful 的 match 查询被重写为两个针对 tweet 字段的 single-term 查询,一个single-term查询对应查询字符串分出来的一个term。
当然,对于索引 us ,这两个 term 分别是 really 和 powerful ,而对于索引 gb ,term 则分别是 realli 和 power 。之所以出现这个情况,是由于我们将索引 gb 中 tweet 字段的分析器修改为 english分析器。
排序与相关性
默认情况下,返回的结果是按照 相关性 进行排序的——最相关的文档排在最前。 在本章的后面部分,我们会解释 相关性 意味着什么以及它是如何计算的, 不过让我们首先看看 sort 参数以及如何使用它。
排序
为了按照相关性来排序,需要将相关性表示为一个数值。在 Elasticsearch 中, 相关性得分 由一个浮点数进行表示,并在搜索结果中通过 _score 参数返回, 默认排序是 _score 降序。
有时,相关性评分对你来说并没有意义。例如,下面的查询返回所有 user_id 字段包含 1 的结果:
GET /_search
{
"query" : {
"bool" : {
"filter" : {
"term" : {
"user_id" : 1
}
}
}
}
}
这里没有一个有意义的分数:因为我们使用的是 filter (过滤),这表明我们只希望获取匹配 user_id: 1的文档,并没有试图确定这些文档的相关性。 实际上文档将按照随机顺序返回,并且每个文档都会评为零分。
constant_score查询进行替代:GET /_search { "query" : { "constant_score" : { "filter" : { "term" : { "user_id" : 1 } } } } }这将让所有文档应用一个恒定分数(默认为
1)。它将执行与前述查询相同的查询,并且所有的文档将像之前一样随机返回,这些文档只是有了一个分数而不是零分。
按照字段的值排序
在这个案例中,通过时间来对 tweets 进行排序是有意义的,最新的 tweets 排在最前。 我们可以使用 sort 参数进行实现:
GET /_search
{
"query" : {
"bool" : {
"filter" : { "term" : { "user_id" : 1 }}
}
},
"sort": { "date": { "order": "desc" }}
}
你会注意到结果中的两个不同点:
"hits" : {
"total" : 6,
"max_score" : null, <1>
"hits" : [ {
"_index" : "us",
"_type" : "tweet",
"_id" : "14",
"_score" : null, <2>
"_source" : {
"date": "2014-09-24",
...
},
"sort" : [ 1411516800000 ] <3>
},
...
}
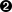
_score不被计算, 因为它并没有用于排序.

date字段的值表示为自 epoch (January 1, 1970 00:00:00 UTC)以来的毫秒数,通过sort字段的值进行返回。
首先我们在每个结果中有一个新的名为 sort 的元素,它包含了我们用于排序的值。 在这个案例中,我们按照 date 进行排序,在内部被索引为 自 epoch 以来的毫秒数 。 long 类型数 1411516800000 等价于日期字符串 2014-09-24 00:00:00 UTC 。
其次 _score 和 max_score 字段都是 null 。 计算 _score 的花销巨大,通常仅用于排序; 我们并不根据相关性排序,所以记录 _score 是没有意义的。如果无论如何你都要计算 _score , 你可以将track_scores 参数设置为 true 。
"sort": "number_of_children"字段将会默认升序排序 ,而按照
_score的值进行降序排序。
多级排序
假定我们想要结合使用 date 和 _score 进行查询,并且匹配的结果首先按照日期排序,然后按照相关性排序:
GET /_search
{
"query" : {
"bool" : {
"must": { "match": { "tweet": "manage text search" }},
"filter" : { "term" : { "user_id" : 2 }}
}
},
"sort": [
{ "date": { "order": "desc" }},
{ "_score": { "order": "desc" }}
]
}
排序条件的顺序是很重要的。结果首先按第一个条件排序,仅当结果集的第一个 sort 值完全相同时才会按照第二个条件进行排序,以此类推。
多级排序并不一定包含 _score 。你可以根据一些不同的字段进行排序, 如地理距离或是脚本计算的特定值。
sort参数:GET /_search?sort=date:desc&sort=_score&q=search
多值字段的排序
一种情形是字段有多个值的排序, 需要记住这些值并没有固有的顺序;一个多值的字段仅仅是多个值的包装,这时应该选择哪个进行排序呢?
对于数字或日期,你可以将多值字段减为单值,这可以通过使用 min 、 max 、 avg 或是 sum 排序模式。 例如你可以按照每个 date 字段中的最早日期进行排序,通过以下方法:
"sort": {
"dates": {
"order": "asc",
"mode": "min"
}
}
字符串排序与多字段
被解析的字符串字段也是多值字段, 但是很少会按照你想要的方式进行排序。如果你想分析一个字符串,如 fine old art , 这包含 3 项。我们很可能想要按第一项的字母排序,然后按第二项的字母排序,诸如此类,但是 Elasticsearch 在排序过程中没有这样的信息。
你可以使用 min 和 max 排序模式(默认是 min ),但是这会导致排序以 art 或是 old ,任何一个都不是所希望的。
为了以字符串字段进行排序,这个字段应仅包含一项: 整个 not_analyzed 字符串。 但是我们仍需要 analyzed 字段,这样才能以全文进行查询
一个简单的方法是用两种方式对同一个字符串进行索引,这将在文档中包括两个字段: analyzed 用于搜索, not_analyzed 用于排序
但是保存相同的字符串两次在 _source 字段是浪费空间的。 我们真正想要做的是传递一个 单字段 但是却用两种方式索引它。所有的 _core_field 类型 (strings, numbers, Booleans, dates) 接收一个 fields 参数
该参数允许你转化一个简单的映射如:
"tweet": {
"type": "string",
"analyzer": "english"
}
为一个多字段映射如:
"tweet": { <1>
"type": "string",
"analyzer": "english",
"fields": {
"raw": { <2>
"type": "string",
"index": "not_analyzed"
}
}
}
tweet主字段与之前的一样: 是一个analyzed全文字段。
tweet.raw子字段是not_analyzed.
现在,至少只要我们重新索引了我们的数据,使用 tweet 字段用于搜索,tweet.raw 字段用于排序:
GET /_search
{
"query": {
"match": {
"tweet": "elasticsearch"
}
},
"sort": "tweet.raw"
}
以全文
analyzed字段排序会消耗大量的内存。获取更多信息请看 聚合与分析 。
什么是相关性?
我们曾经讲过,默认情况下,返回结果是按相关性倒序排列的。 但是什么是相关性? 相关性如何计算?
每个文档都有相关性评分,用一个正浮点数字段 _score 来表示 。 _score 的评分越高,相关性越高。
查询语句会为每个文档生成一个 _score 字段。评分的计算方式取决于查询类型 不同的查询语句用于不同的目的: fuzzy 查询会计算与关键词的拼写相似程度,terms 查询会计算 找到的内容与关键词组成部分匹配的百分比,但是通常我们说的 relevance 是我们用来计算全文本字段的值相对于全文本检索词相似程度的算法。
Elasticsearch 的相似度算法 被定义为检索词频率/反向文档频率, TF/IDF ,包括以下内容:
检索词频率
检索词在该字段出现的频率?出现频率越高,相关性也越高。 字段中出现过 5 次要比只出现过 1 次的相关性高。
反向文档频率
每个检索词在索引中出现的频率?频率越高,相关性越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
字段长度准则
字段的长度是多少?长度越长,相关性越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段权重更大。
单个查询可以联合使用 TF/IDF 和其他方式,比如短语查询中检索词的距离或模糊查询里的检索词相似度。
相关性并不只是全文本检索的专利。也适用于 yes|no 的子句,匹配的子句越多,相关性评分越高。
如果多条查询子句被合并为一条复合查询语句 ,比如 bool 查询,则每个查询子句计算得出的评分会被合并到总的相关性评分中。
理解评分标准
当调试一条复杂的查询语句时, 想要理解 _score 究竟是如何计算是比较困难的。Elasticsearch 在 每个查询语句中都有一个 explain 参数,将 explain 设为 true 就可以得到更详细的信息。
GET /_search?explain <1>
{
"query" : { "match" : { "tweet" : "honeymoon" }}
}
explain参数可以让返回结果添加一个_score评分的得来依据。
explain参数会为每个匹配到的文档产生一大堆额外内容,但是花时间去理解它是很有意义的。 如果现在看不明白也没关系 — 等你需要的时候再来回顾这一节就行。下面我们来一点点的了解这块知识点。
首先,我们看一下普通查询返回的元数据:
{
"_index" : "us",
"_type" : "tweet",
"_id" : "12",
"_score" : 0.076713204,
"_source" : { ... trimmed ... },
这里加入了该文档来自于哪个节点哪个分片上的信息,这对我们是比较有帮助的,因为词频率和 文档频率是在每个分片中计算出来的,而不是每个索引中:
"_shard" : 1,
"_node" : "mzIVYCsqSWCG_M_ZffSs9Q",
然后它提供了 _explanation 。每个 入口都包含一个 description 、 value 、 details 字段,它分别告诉你计算的类型、计算结果和任何我们需要的计算细节。
"_explanation": { <1>
"description": "weight(tweet:honeymoon in 0)
[PerFieldSimilarity], result of:",
"value": 0.076713204,
"details": [
{
"description": "fieldWeight in 0, product of:",
"value": 0.076713204,
"details": [
{ <2>
"description": "tf(freq=1.0), with freq of:",
"value": 1,
"details": [
{
"description": "termFreq=1.0",
"value": 1
}
]
},
{ <3>
"description": "idf(docFreq=1, maxDocs=1)",
"value": 0.30685282
},
{ <4>
"description": "fieldNorm(doc=0)",
"value": 0.25,
}
]
}
]
}
honeymoon相关性评分计算的总结
字段长度准则
explain结果代价是十分昂贵的,它只能用作调试工具 。千万不要用于生产环境。
第一部分是关于计算的总结。告诉了我们 honeymoon 在 tweet 字段中的检索词频率/反向文档频率或TF/IDF, (这里的文档 0 是一个内部的 ID,跟我们没有关系,可以忽略。)
然后它提供了权重是如何计算的细节:
检索词频率:
检索词 `honeymoon` 在这个文档的 `tweet` 字段中的出现次数。
反向文档频率:
检索词 `honeymoon` 在索引上所有文档的 `tweet` 字段中出现的次数。
字段长度准则:
在这个文档中, `tweet` 字段内容的长度 -- 内容越长,值越小。
复杂的查询语句解释也非常复杂,但是包含的内容与上面例子大致相同。 通过这段信息我们可以了解搜索结果是如何产生的。
explain描述是难以阅读的, 但是转成 YAML 会好很多,只需要在参数中加上format=yaml。
理解文档是如何被匹配到的
当 explain 选项加到某一文档上时, explain api 会帮助你理解为何这个文档会被匹配,更重要的是,一个文档为何没有被匹配。
请求路径为 /index/type/id/_explain ,如下所示:
GET /us/tweet/12/_explain
{
"query" : {
"bool" : {
"filter" : { "term" : { "user_id" : 2 }},
"must" : { "match" : { "tweet" : "honeymoon" }}
}
}
}
不只是我们之前看到的充分解释 ,我们现在有了一个 description 元素,它将告诉我们:
"failure to match filter: cache(user_id:[2 TO 2])"
也就是说我们的 user_id 过滤子句使该文档不能匹配到。
Doc Values 介绍
本章的最后一个话题是关于 Elasticsearch 内部的一些运行情况。在这里我们先不介绍新的知识点,所以我们应该意识到,Doc Values 是我们需要反复提到的一个重要话题。
当你对一个字段进行排序时,Elasticsearch 需要访问每个匹配到的文档得到相关的值。倒排索引的检索性能是非常快的,但是在字段值排序时却不是理想的结构。
- 在搜索的时候,我们能通过搜索关键词快速得到结果集。
- 当排序的时候,我们需要倒排索引里面某个字段值的集合。换句话说,我们需要
转置倒排索引。
转置 结构在其他系统中经常被称作 列存储 。实质上,它将所有单字段的值存储在单数据列中,这使得对其进行操作是十分高效的,例如排序。
在 Elasticsearch 中,Doc Values 就是一种列式存储结构,默认情况下每个字段的 Doc Values 都是激活的,Doc Values 是在索引时创建的,当字段索引时,Elasticsearch 为了能够快速检索,会把字段的值加入倒排索引中,同时它也会存储该字段的 Doc Values。
Elasticsearch 中的 Doc Values 常被应用到以下场景:
- 对一个字段进行排序
- 对一个字段进行聚合
- 某些过滤,比如地理位置过滤
- 某些与字段相关的脚本计算
因为文档值被序列化到磁盘,我们可以依靠操作系统的帮助来快速访问。当 working set 远小于节点的可用内存,系统会自动将所有的文档值保存在内存中,使得其读写十分高速; 当其远大于可用内存,操作系统会自动把 Doc Values 加载到系统的页缓存中,从而避免了 jvm 堆内存溢出异常。
我们稍后会深入讨论 Doc Values。现在所有你需要知道的是排序发生在索引时建立的平行数据结构中。
执行分布式检索
在继续之前,我们将绕道讨论一下在分布式环境中搜索是怎么执行的。 这比我们在 分布式文档存储 章节讨论的基本的 增-删-改-查 (CRUD)请求要复杂一些。
内容提示
你可以根据兴趣阅读本章内容。你并不需要为了使用 Elasticsearch 而理解和记住所有的细节。
这章的阅读目的只为初步了解下工作原理,以便将来需要时可以及时找到这些知识, 但是不要被细节所困扰。
一个 CRUD 操作只对单个文档进行处理,文档的唯一性由 _index, _type, 和 routing values (通常默认是该文档的 _id )的组合来确定。 这表示我们确切的知道集群中哪个分片含有此文档。
搜索需要一种更加复杂的执行模型因为我们不知道查询会命中哪些文档: 这些文档有可能在集群的任何分片上。 一个搜索请求必须询问我们关注的索引(index or indices)的所有分片的某个副本来确定它们是否含有任何匹配的文档。
但是找到所有的匹配文档仅仅完成事情的一半。 在 search 接口返回一个 page 结果之前,多分片中的结果必须组合成单个排序列表。 为此,搜索被执行成一个两阶段过程,我们称之为 query then fetch 。
查询阶段
在初始 查询阶段 时, 查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的 优先队列。
优先队列
一个 优先队列 仅仅是一个存有 top-n 匹配文档的有序列表。优先队列的大小取决于分页参数
from和size。例如,如下搜索请求将需要足够大的优先队列来放入100条文档。GET /_search { "from": 90, "size": 10 }
这个查询阶段的过程如图 图 14 “查询过程分布式搜索” 所示。
图 14. 查询过程分布式搜索
查询阶段包含以下三个步骤:
- 客户端发送一个
search请求到Node 3,Node 3会创建一个大小为from + size的空优先队列。 Node 3将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为from + size的本地有序优先队列中。- 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是
Node 3,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点。 这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
第一步是广播请求到索引中每一个节点的分片拷贝。就像 document GET requests 所描述的, 查询请求可以被某个主分片或某个副本分片处理, 这就是为什么更多的副本(当结合更多的硬件)能够增加搜索吞吐率。 协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。
每个分片在本地执行查询请求并且创建一个长度为 from + size 的优先队列—也就是说,每个分片创建的结果集足够大,均可以满足全局的搜索请求。 分片返回一个轻量级的结果列表到协调节点,它仅包含文档 ID 集合以及任何排序需要用到的值,例如 _score 。
协调节点将这些分片级的结果合并到自己的有序优先队列里,它代表了全局排序结果集合。至此查询过程结束。
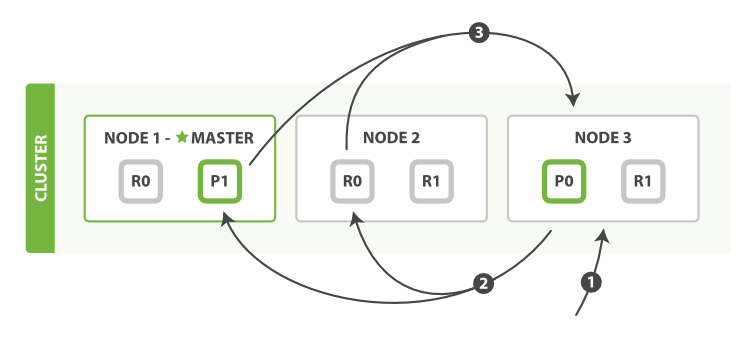
取回阶段
查询阶段标识哪些文档满足 搜索请求,但是我们仍然需要取回这些文档。这是取回阶段的任务, 正如 图 15 “分布式搜索的取回阶段” 所展示的。
图 15. 分布式搜索的取回阶段
分布式阶段由以下步骤构成:
- 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个
GET请求。 - 每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。
- 一旦所有的文档都被取回了,协调节点返回结果给客户端。
协调节点首先决定哪些文档 确实 需要被取回。例如,如果我们的查询指定了 { "from": 90, "size": 10 } ,最初的90个结果会被丢弃,只有从第91个开始的10个结果需要被取回。这些文档可能来自和最初搜索请求有关的一个、多个甚至全部分片。
协调节点给持有相关文档的每个分片创建一个 multi-get request ,并发送请求给同样处理查询阶段的分片副本。
分片加载文档体-- _source 字段--如果有需要,用元数据和 search snippet highlighting 丰富结果文档。 一旦协调节点接收到所有的结果文档,它就组装这些结果为单个响应返回给客户端。
深分页(Deep Pagination)
先查后取的过程支持用
from和size参数分页,但是这是 有限制的 。 要记住需要传递信息给协调节点的每个分片必须先创建一个from + size长度的队列,协调节点需要根据number_of_shards * (from + size)排序文档,来找到被包含在size里的文档。取决于你的文档的大小,分片的数量和你使用的硬件,给 10,000 到 50,000 的结果文档深分页( 1,000 到 5,000 页)是完全可行的。但是使用足够大的
from值,排序过程可能会变得非常沉重,使用大量的CPU、内存和带宽。因为这个原因,我们强烈建议你不要使用深分页。实际上, “深分页” 很少符合人的行为。当2到3页过去以后,人会停止翻页,并且改变搜索标准。会不知疲倦地一页一页的获取网页直到你的服务崩溃的罪魁祸首一般是机器人或者web spider。
如果你 确实 需要从你的集群取回大量的文档,你可以通过用
scroll查询禁用排序使这个取回行为更有效率,我们会在 later in this chapter 进行讨论。
搜索选项
有几个 查询参数可以影响搜索过程。
偏好
偏好这个参数 preference 允许 用来控制由哪些分片或节点来处理搜索请求。 它接受像 _primary,_primary_first, _local, _only_node:xyz, _prefer_node:xyz, 和 _shards:2,3 这样的值, 这些值在search preference 文档页面被详细解释。
但是最有用的值是某些随机字符串,它可以避免 bouncing results 问题。
Bouncing Results
想象一下有两个文档有同样值的时间戳字段,搜索结果用
timestamp字段来排序。 由于搜索请求是在所有有效的分片副本间轮询的,那就有可能发生主分片处理请求时,这两个文档是一种顺序, 而副本分片处理请求时又是另一种顺序。这就是所谓的 bouncing results 问题: 每次用户刷新页面,搜索结果表现是不同的顺序。 让同一个用户始终使用同一个分片,这样可以避免这种问题, 可以设置
preference参数为一个特定的任意值比如用户会话ID来解决。
超时问题
通常分片处理完它所有的数据后再把结果返回给协同节点,协同节点把收到的所有结果合并为最终结果。
这意味着花费的时间是最慢分片的处理时间加结果合并的时间。如果有一个节点有问题,就会导致所有的响应缓慢。
参数 timeout 告诉 分片允许处理数据的最大时间。如果没有足够的时间处理所有数据,这个分片的结果可以是部分的,甚至是空数据。
搜索的返回结果会用属性 timed_out 标明分片是否返回的是部分结果:
...
"timed_out": true, <1>
...
- 超时检查是基于每文档做的。 但是某些查询类型有大量的工作在文档评估之前需要完成。 这种 "setup" 阶段并不考虑超时设置,所以太长的建立时间会导致超过超时时间的整体延迟。
- 因为时间检查是基于每个文档的,一次长时间查询在单个文档上执行并且在下个文档被评估之前不会超时。 这也意味着差的脚本(比如带无限循环的脚本)将会永远执行下去。
路由
在 路由一个文档到一个分片中 中, 我们解释过如何定制参数 routing ,它能够在索引时提供来确保相关的文档,比如属于某个用户的文档被存储在某个分片上。 在搜索的时候,不用搜索索引的所有分片,而是通过指定几个 routing 值来限定只搜索几个相关的分片:
GET /_search?routing=user_1,user2
这个技术在设计大规模搜索系统时就会派上用场,我们在 扩容设计 中详细讨论它。
搜索类型
缺省的搜索类型是 query_then_fetch 。 在某些情况下,你可能想明确设置 search_type 为 dfs_query_then_fetch 来改善相关性精确度:
GET /_search?search_type=dfs_query_then_fetch
搜索类型 dfs_query_then_fetch 有预查询阶段,这个阶段可以从所有相关分片获取词频来计算全局词频。 我们在 被破坏的相关度! 会再讨论它。
游标查询 Scroll
scroll 查询 可以用来对 Elasticsearch 有效地执行大批量的文档查询,而又不用付出深度分页那种代价。
游标查询允许我们 先做查询初始化,然后再批量地拉取结果。 这有点儿像传统数据库中的 cursor 。
游标查询会取某个时间点的快照数据。 查询初始化之后索引上的任何变化会被它忽略。 它通过保存旧的数据文件来实现这个特性,结果就像保留初始化时的索引 视图 一样。
深度分页的代价根源是结果集全局排序,如果去掉全局排序的特性的话查询结果的成本就会很低。 游标查询用字段 _doc 来排序。 这个指令让 Elasticsearch 仅仅从还有结果的分片返回下一批结果。
启用游标查询可以通过在查询的时候设置参数 scroll 的值为我们期望的游标查询的过期时间。 游标查询的过期时间会在每次做查询的时候刷新,所以这个时间只需要足够处理当前批的结果就可以了,而不是处理查询结果的所有文档的所需时间。 这个过期时间的参数很重要,因为保持这个游标查询窗口需要消耗资源,所以我们期望如果不再需要维护这种资源就该早点儿释放掉。 设置这个超时能够让 Elasticsearch 在稍后空闲的时候自动释放这部分资源。
GET /old_index/_search?scroll=1m <1>
{
"query": { "match_all": {}},
"sort" : ["_doc"], <2>
"size": 1000
}
_doc是最有效的排序顺序。
这个查询的返回结果包括一个字段 _scroll_id, 它是一个base64编码的长字符串 ((("scroll_id"))) 。 现在我们能传递字段 _scroll_id 到 _search/scroll 查询接口获取下一批结果:
GET /_search/scroll
{
"scroll": "1m", <1>
"scroll_id" : "cXVlcnlUaGVuRmV0Y2g7NTsxMDk5NDpkUmpiR2FjOFNhNnlCM1ZDMWpWYnRROzEwOTk1OmRSamJHYWM4U2E2eUIzVkMxalZidFE7MTA5OTM6ZFJqYkdhYzhTYTZ5QjNWQzFqVmJ0UTsxMTE5MDpBVUtwN2lxc1FLZV8yRGVjWlI2QUVBOzEwOTk2OmRSamJHYWM4U2E2eUIzVkMxalZidFE7MDs="
}
这个游标查询返回的下一批结果。 尽管我们指定字段 size 的值为1000,我们有可能取到超过这个值数量的文档。 当查询的时候, 字段 size 作用于单个分片,所以每个批次实际返回的文档数量最大为 size * number_of_primary_shards 。
_scroll_id。每次我们做下一次游标查询, 我们必须把前一次查询返回的字段_scroll_id传递进去。 当没有更多的结果返回的时候,我们就处理完所有匹配的文档了。